
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The scope of this paper is to estimate the production function for the Brazilian industrial sector from a longitudinal panel of the industrial sector (Annual Industrial Survey produced by the Institute of Geography and Statistics—PIA/IBGE—and the Ministry of Labour and Employment’s Annual Relation of Social Information—RAIS/MTE—ranging from 1996 until 2005) through a Bayesian Vector Autoregressive (BVAR) approach. This new method adds to the empirical industrial organization another way to estimate the demand, avoiding cumbersome calculations. It gives the possibility of analysing not only the dynamic relationships among the variables but also the shocks through the impulse response function (IRF). Additionally, it gives the opportunity to analyse the industry sector’s productivity by minimizing the problem of endogeneity and therefore it also sheds some light on the trend of this variable throughout the period abovementioned.
PUBLIC INTEREST STATEMENT
The scope of this paper is to estimate the production function for the Brazilian industrial sector from a longitudinal panel of the industrial sector during Real Plan until President’s Lula management through a Bayesian Vector Autoregressive (BVAR) approach. This new method adds to the new empirical industrial organization another way to estimate the demand, avoiding cumbersome calculations such as Olley and Pakes (Citation1996) and Levinsohn and Petrin (Citation2003). It gives the possibility of analysing not only the dynamic relationships among the variables but also innovations through the impulse response function (IRF). Additionally, it gives the opportunity to analyse the industry sector’s productivity by minimizing the problem of endogeneity and therefore it also sheds some light on the trend of this variable. Then, it appoints the idea that human capital itself is not a driver in the Brazilian industry; just for sectors that employ high technological process and requires highly qualified workers.
1. Introduction
The scope of this paper is to estimate the Brazilian production function from a longitudinal panel of the industrial sector (Annual Industrial Survey produced by the Institute of Geography and Statistics—PIA/IBGE—and the Ministry of Labour and Employment’s Annual Relation of Social Information—RAIS/MTE—ranging from 1996 until 2005) through a Bayesian Vector Autoregressive (BVAR) approach. This new method adds to the empirical industrial organization another way to estimate the demand, avoiding cumbersome calculations such as those found at Olley and Pakes (Citation1996) and Levinsohn and Petrin (Citation2003) papers. It also gives the possibility of analysing not only the dynamic relationships among the variables but also the shocks through the impulse response function (IRF). Additionally, it gives the opportunity to analyse the industry sector’s productivity by minimizing the problem of endogeneity and therefore it also sheds some light on the trend of this variable throughout the period abovementioned. One big advantage of using the Bayesian framework relies on the fact that unobservable variables are fully estimated by using the a priori assumption and when this is updated it culminates in a new a posterior distribution.
In item two, it is done a revision of the literature regarding the idea behind Vector Autoregressive theory, mostly used in Macroeconomics. It is rest upon heavily on the Holtz—Eakin’s seminal paper (1988). Afterwards, a brief explanation regarding Bayesian point of view is also outlined, following the suggestion used in LeSage’s Matlab econometrics package and Canova’s book “Methods for Applied Macroeconomic Research”. In the following item, it is explained that the model as well as the retrieval of all variables used within the estimation also pay attention to methodology issues concerning it.
The estimated regression in item four aimed at verifying the dynamic relationship through the Cobb-Douglas production function, accounting for the industrial sector’s input production, that is, salaryFootnote1 and capital. As suggested by Olley and Pakes (Citation1996), a certain care was taken in avoiding the selection and endogeneity problem by controlling the number of firms who enter and exit during the timeframe in question. Comparison is made with other estimated methodologies such as Ordinary Least Square (OLS), General Least Square (GLS) and General Method of Moments (GMM). Some interesting findings do not corroborate the analysis of the authors in the aspect of having an overestimating problem with regards to capital and underestimating to labour.
2. Review of the literature
The objective of using the Vector Autoregressive approach (VAR) is related to its parsimony, avoiding cumbersome calculations as, for example, openly used in Olley and Pakes (Citation1996) and Levinsohn and Petrin (Citation2003), which requires a three stage methods to estimate demand functions—and level-based firms’ productivity— of course with variations as proposed by the latter authors, which use an intermediate input (material) as instrumental variables. The basic setup is suggested as follows:
Traditional Ordinary Least Square (OLS) regression is made in order to find the coefficient concerning the labour using a fourth order polynomial extension;
Analysis of survival through a Probit model;
And finally a Nonlinear Least Square (NLS) is performed in order to find the coefficients of capital, given the investment (and material inputs) as instrumental variables and the unobservable factor (which is productivity).
Those structural stages are set up in order to solve the problem of endogeneity towards productivity, which is sorted out between observable and unobservable variables. The first one being the decision-making process made by the board of management; whereas the second one being a truly unpredictable (or unanticipated) shock. However, both are presented as part of the “residuals” within the production function equation. Notwithstanding this rather complicated framework, a couple of assumptions covers both Olley and Pakes (Citation1996) and Levinsohn and Petrin (Citation2003) solutions, which can be subsumed below:
Strict monotonicity between the instruments and unobservable productivity;
This productivity also enters the instruments equations;
Labour does not have a dynamic implication as capital.
A web of science search shows us that firm productivity with panel VAR approach has very few outcomes. In 2018, the results were only 16 articles, while in 2017 accounted only for 11 and 6 in 2016. Overall, the new empirical industrial economics has based their finding in traditional methods, such as linear panel data, maximum likelihood and Arellano-Bond framework. They are shown in Journal of Economic Dynamics and Control (20), Economics Letters (6), Economic Modelling (5). Doing the same search, but only specifying firm productivity estimates using Cobb-Douglas model, articles figures were raised to 409 in 2018, 321 in 2017 and 371 in 2016. Journals that mostly contributed to the above results were essentially Economic Modelling (370), Journal of Economic Dynamics and Control (337) and European Economic Review (308).
It is clear that developing a new approach to the estimation of firm productivity, using panel data allied with non-frequentist time series methods would be a significant contribution to the literature.
In that line of thought, we cite the work of Miranda et al. (Citation2017), which argues that in a traditional Cobb-Douglas model, if only if covariates are correlated with the individual-specific effects and derive appropriate GLS and IV estimators for the resulting correlated random effects spatial panel data model. Also, they provide production function estimates supporting the existence of public capital spillovers, whose relation falls back on the evidence of a relation between public capital and the unobserved productivity (i.e., the individual specific effect of the production function) and its spatial spillover. This fact is not clearly shown in Olley and Pakes (Citation1996), Levinsohn and Petrin (Citation2003), and C. Álvarez et al. (Citation2016) states that production function approach is used to introduce the effect of public infrastructure on economic growth focusing on its spillover effects, being one of them productivity. They also managed to utilize spatial interdependence into these models, applying the most recent spatial econometric techniques based on instrumental variables estimation in spatial autoregressive panel models in comparison with Maximum Likelihood estimation methods. They concluded that in the spatial autoregressive panel model, labor and private capital are relevant production factors. Then, it confirms the relevance and significance of spillovers effects, which is consistent with the new empirical industrial organization.
Mavroeidis et al. (Citation2015) presented a miscellaneous framework, using a maximum likelihood method to estimate the cross sectional distributions of heterogeneous autoregressive (AR) parameters with short panel data. They construct a panel likelihood by integrating unknown cross-sectional density of heterogeneous AR parameters with respect to a known time-series data generating kernel. A model of employment dynamics with the firm-level data of Arellano and Bond (Citation1991) was tested and as a conclusion, they found out that adjustment rates of employment are significantly heterogeneous across firms and this result is not available with the existing methods, since they presume homogeneous adjustment rates or long panel data. In summary, the authors have shown a way to have a more generic and flexible model estimation, avoiding several econometric stages.
3. Methodology
In this article, it will proposed the use of Vector of Autoregressive (VAR), taken the form of as in Holtz-Eakin et al. (Citation1988). The advantage of it is regarding its relative simplicity and flexibility in dealing with econometric problems. Different from the macroeconomic point of view, the micro data have its own idiosyncrasies which accounts for individual’s heterogeneity across the longitudinal panel (cross-section). Pooling cross-section models have the following advantages:
Assumption of time stationary can be relaxed, allowing for integrated series if this is the case;
Asymptotic theory for large cross-sections units does not require the VAR to have unit or explosive roots (that is, non-stationary), which means the first point of the life of individuals is hypothetically “constant” (or also known as “random walk”).
To a certain point, the abovementioned assumptions are interesting because it provides no restrictions concerning the dynamic relationships among individuals (and those individuals’ movements as time passes by). Most importantly is the fact that allowing for lags from the dependent variable, it solves for the endogeneity problem concerning anticipated or predictable productivity, since it carries over from one time to the subsequent ones, minimizing its impact by giving less relevance to higher lags and therefore the residuals become less correlated to the remaining variables. Henceforth this fact can substitute the three-stage estimation proposed by Olley and Pakes (Citation1996) and Levinsohn and Petrin (Citation2003).
In terms of statistical inferences within the VAR approach, it must hold the orthogonality conditions within the errors and the variables within the system and this will be accomplished by Cholesky decomposition. In addition to it, error correction model can be also estimated in case of a long-term relationship dynamics among the variables.
According to Antonakakisa et al. (Citation2017), the advantages of using a panel VAR methodology relative to other methods are: (i) panel data models allow us to control for unobservable time-invariant characteristics, reducing concerns of omitted variable bias; (ii) time fixed effects can also be added in order to account for any shocks; (iii) the inclusion of variables lags helps to analyse the disequilibrium (or not) relationships among them. In that sense, impulse response functions based on PVARs can account for any delayed effects of the variables under consideration and thus determine whether the effects of those variables are short-lived, long-lived or even both. Such dynamic effects would not have been captured by traditional panel regressions; (iv) PVARs are designed to address the endogeneity problem, which is one of the most serious challenges of any empirical research; and (v) PVARs can be effectively employed with relative short-time series due to the efficiency gained from the cross-sectional dimension.
Moreover, according to Christou et al. (Citation2017), a PVAR model may allow for (i) dynamic interdependencies, which, in turn, occur when one sectoral variable affect another lagged variable, (ii) static interdependencies which occur when the correlations between the VARs’ errors of two or more sector variables are non- zero and (iii) cross-section heterogeneities which happen when two sectors have VARs with different coefficients. Furthermore, given the autoregressive structure of a PVAR, endogeneity problems are solved. Also Koop and Korobilis (Citation2016) developed methods which select among all possible combinations of restricted PVARs and find a parsimonious PVAR which deals with the overparameterization problems.
In Econometrics, it is well-known that one problem related to the micro data is concerning small samples. For that, LeSage’s Matlab Econometrics package and Doam, Litterman and Sims (Citation1984) proposed the use of Bayesian prior information, reflected by the Minnesota prior whose mean and variance are normally distributed and if the former is equal to 1 it reflects its importance in terms of lagged explanatory variables of coefficients of the model and if it is assigned zero is otherwise. This assumption, however, can also be relaxed. With this new framework, it is then presented the Bayesian panel Vector Autoregressive (BVAR).
4. The model
According to Holtz-Eakin et al. (Citation1988), the estimation of the panel Vector Autogressive Moving Average (VARMA (p,q)) will be done using the reduced form, which takes the form of
where
Xit represents the endogenous variables;
Zit represents the exogenous variables.
According to Cholesky decomposition (see, Enders (Citation1995) pgs. 302–303), in order to have a complete identification (and therefore guarantee the orthogonality conditions from the residuals that is expectation of the errors are zeros), it must create a linear combination that entails the following:
The triangularization can be guaranteed through a linear combination of the type: ; where P is an inferior triangular matrix and is also idempotent. Then:
Then,
That is for instance, in a generalized form:
The main criticism against VARMA(p,q) models are related to the overparametrization and it reflects only the “reduced form” from a structural model. For the latter critique, a good way to smooth it out is applying the Bayesian VAR (BVAR), where a priori distribution it is calculated for each of the coefficients instead of restrict them to zero, for instance.
Generally speaking, the use of informative priors is to redimensionalise the unrestricted model towards a parsimonious one, therefore reducing the parameter uncertainty within a certain set of random events and improving forecast accuracy. A benchmark application is with regards to the shrinkage prior proposed by Litterman (Citation1979, Citation1984) and subsequently developed by the University of Minnesota, more specifically Doan, T., Litterman, R., Sims, C. (Citation1984), which is known in the BVAR literature as the “Minnesota prior”. The informativeness of the prior can be set by treating it as an additional parameter, based on a hierarchical interpretation of the model. In summary, the Minnesota prior introduces restrictions in a flexible way since it imposes probability distributions on the coefficients of the VAR which reduce the dimensionality of the problem and, at the same time, give a reasonable account of the uncertainty faced by the Central Bank. The choice of φ is important since if the prior is too loose, overfitting is hard to avoid; while if it is too tight, the data is not allowed to speak.
In order to complete the desired Bayesian framework, the coefficients will vary accordingly to following system:
Where and priors have a normal probability distribution.
In terms of Impulse Response Function (IRF), the above setup also imposes a similar pass-through shock to the variables, as suggests. Moreover, the question regarding to the lag/leads of the model can be chosen according to the result of ratio likelihood (LR) hypothesis testing as verified by Holtz-Eakin et al. (Citation1988).
According to the Bayesian view, the coefficients allow to be weighted by the Minnesota priors, with the standard deviation having the form:
Where is the estimated standard error from the univariate autoregression involving i and the scaling factor is the estimated variance of j and i. The remaining variables are the hyperparameters, which reflects the standard deviation of the prior (
) and the decay of rate, varying from zero to one, as the lag length increases in less importance—
. Thus, the variance from the above model will be
rather than
.
This setup will help consistently recuperate the structural model (production function) and the error will be used to reflect the unobservational productivity of the economy.
4.1. The data
In this study, it is used a sample data from 1996 to 2005 in order to maintain the same monetary policy anchorage, that is, the “Real Plan” and the application of inflation target system with floating exchange rate. It worth noticing that after 2009, a “new development matrix” was applied the Luiz Inacio Lula da Silva’s Government (mandate from 2002 to 2010) and carried out by his successor, Dilma Roussef (mandate from 2010 to 2016), through a credit stimuli and industry subsidies (automobile, textiles and electronics), so as to buffer the subprime contagion into the country.
Therefore, the panel was constructed from Annual Industrial Survey produced by the Institute of Geography and Statistics—PIA/IBGE—and the Ministry of Labour and Employment’s Annual Relation of Social Information—RAIS/MTE—ranging from 1996 until 2005. It was used a 107 disaggregation from sub-sectors of the economic activity according to the CNAE (National Classification of Economic Activity).
Below it can be found the variables retrieved from the above surveys:
PRODUCTION (prod)—Earnings from Sales;
)LABOUR (lab)—Average Nominal Salary from the year in question;
CAPITAL (cap)—Net Fixed Assets in a year (already discounted by the depreciation);
INSTRUMENTAL VARIABLE (inst)—Average Nominal Salary from other sectors (except for the one in question);
EXIT (exit)—Binary variable that gives 1 to a negative variation of the number of firms;
ENTRANCE (ent)—Binary variable that gives 1 to a positive variation of the number of firms.
All non-deterministic variables were deflated by the accumulated annual inflation index calculated by the Brazilian Central Bank (IPCA—IBGE). Firms have the total of employees above 30 people, that is, it has been analysed the small, medium and large enterprises. The avoidance of micro-firms diminishes the strong problem of selection, since its rate of “death” is relatively high, by reaching a foreclosure in the first year, according to SEBRAE survey in 2005.
Turning to the binary variables, exit and entrance might cast some doubts about the possibility of encountering collinearity among the dependence variables. However, this is not seemed to be the case, since there are years, whose variations are zero within the analysed sectors. One can critic this effect because it is not possible to distinguish this zero variation from a transaction between a merger (less 1 one firm) and an entrant (1 additional firm). But this is a problem from Data Generating Process (DGP) because IBGE does not have a plant-based firm database.
It is interesting to show now the dynamics of all sectors pertaining to the panel data in a time average basis, that is, from 1996 to 2005.
The highest level of average production reflects the export sectors from the Brazilian economy, with special attention to Beverages, Food (vegetables and meal), Sugar, Iron Ore, Steel/Metal, and Automobile—represented in great part by the following companies Inbev, JBS, Cosan, Vale, CSN, Petrobras, GM, VM, FIAT and Ford—, as it can be verified in the tables below. Furthermore, they also present a high level of capital stock (in average terms), which suggest that the level of productivity among those sectors through new technologies are relatively low (requiring also certain time for them to mature).
Earnings, however, show a low level of payoff (considering they are not fully labour-intense), except for the automobile industry. This pattern appoints that human capital development is not a driver for the Brazilian industry. Exceptions are those sectors which demands higher labour qualification and they, therefore, offer higher compensations such as the case of Aviation (i.e., Embraer) and Oil derivates (i.e., Petrobras).
From the previous section, the equation which could best describe the dynamics above analysed are the Cobb-Douglas functional form in log terms as of below:
where “i” is the sector analysed, “t” is the time series panel, “Ait” is the lagged dependent variable, “B0t” to “B4t” are the exogenous variables and also represent the state space coefficients, according to Equationequation (1.3)(1.3)
(1.3) and assuming (1.4) assumptions.
In the next section, the analysis of the abovementioned estimated equation will take place and some interesting results will be drawn from it.
5. The estimation
The Bayesian panel Vector Autoregressive (BVAR) regression has the recourse of using LeSage’s MATLAB Econometric package and for the comparison with other methodologies (OLS, Fixed Effects, Random Effects, GMM, and GLS).
As it can be seen in below, although production (prod) and capital (cap) present a high standard deviation (remembering it is in log terms), a test of normality shows that the normal distribution can be rejected at a 5% level of significance. Labour (lab) can also be denoted as normal with the only exception of the instrumental variable, whose has got a probability of rejecting the normality hypothesis around 13%. But this is due to the way this variable was constructed, that is, around an average salary from other sectors and therefore it is less prone to huge dispersion, representing then a leptokurtic form. However, in order to facilitate the analysis, all variables are deemed to be normal, since Chi squared is produced by normal distributions.
Table 1. Average sector output/input results
Table 2. Descriptive statistics
Table 3. Normality test (*)
It is worth noticing that all variables are positively correlated, even though on a low value as verified in . From this first point of view, it diverges from Olley and Pakes (Citation1996) results in the sense that they verify a negative correlation with regards to capital.
Table 4. Correlation matrix
Table 5. Likelihood ratio
After the descriptive statistical analysis, now it is necessary to turn to model itself by choosing the lags representing the autoregressive component, according to a Likelihood ratio Hypothesis (LR). It is considered the maximum lag length of 12 and minimum of 3 as it can be shown below. The ideal result achieved is 5 lags.
Now for the Bayesian part, the hyperparameters are set to implement the dissipation of the prior, that is, recalling from section three, tightness is given by theta and equals 1%. The weight is 0.5, which means information from the priors are relatively important. The rate of decay around 1 is a medium “dying out” process. Therefore, running the regressions it yields in the results in . It is worth noticing that BVAR produces a coefficient in capital whose magnitude is relatively less than the orders estimations. This is an interesting result because the manufacturing industry in Brazil are not fully capital intense in a strict definition, as observed within data in Section 3. It also employs a mix with labour force and capital.
This fact implicates that the high level of average capital stock in the most prominent industries in Brazil does not dominate the data as a whole, since the BVAR regression shows a coefficient of 0.4 (and when comparing to other methodologies, this value is 60% less). That means not only most of the sectors employs low level of capital stock (as seen in Section 3), but it is also carried over to other periods. Considering also the control variables for selection (exit and entrance), coefficients are considerably high too, that is—0.32 and 0.28, respectively. This points to an interesting dynamic:—Firms might improve their level of productivity by “entering” into new markets (or sectors) or alternatively merging or acquiring competitors. Unfortunately, the latter cannot be fully identified owing to the data generating process (DGP) as mentioned before.
However, calculating an estimated productivity a la Olley and Pakes (Citation1996)—where productivity stems from the residuals—, growth (in aggregate terms) is relatively small, with an average increase of 3.9% (CAGR—Compound Annual Growth Rate). It can be verified in and below.
Table 6. Productivity
Table 7. Estimation
In the case of labour, it can be verified it reflects negative bias as shown in other regressions (BVAR, OLS and GLS when compared to FE and MLE). This stems from the fact that DGP (Data Generating Process) has some flaws in the sense that in does not open all the employment feature of the firms in the panel. But it corroborates the idea that human capital itself is not a driver in the Brazilian industry (just for sectors that employ high technological process and requires highly qualified workers as shown previously in the dataset ()).
Figure 1. Impulse response.
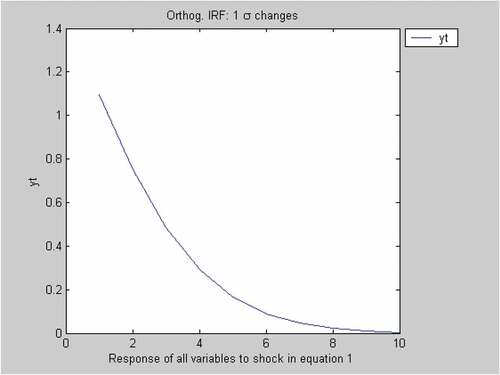
Given that BVAR better describes the dynamics and idiosyncrasies of the Brazilian industrial sector, it is now interesting to analyse “shocks” to productivity in the equation. This is done by considering the impulse response function (IRF). Below in the chart, it is shown that productivity innovations of 1% of standard deviation (that is, 0.55) do not have a permanent impact in production, since it dies out after 10 years in an almost equally paced velocity. This dynamic has a significant meaning because gains in productivity are normally seen in the first periods and the remaining will be absorbed in learning—by—doing process.
6. Concluding remarks
In this paper, it has been presented some interesting results to shed some lights on the estimating the production function from a different and relatively new instrument, that is, the Bayesian Panel Approach. A further line of research will be considering the productivity as an unobservable variable vis-à-vis Kalman Filter (KF). Also, a panel BVAR can be represented by MCMC in case variables a non-linear and non-Gaussian.
Therefore, the scope of this paper is to incentive a further analysis within the new empirical Organisation theory and by avoiding cumbersome calculations such as Olley and Pakes (Citation1996) and Levinsohn and Petrin (Citation2003). It also gives the possibility of analysing not only the dynamic relationships among the variables but also the shocks through the impulse response function (IRF) as seen previously.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Roberto Ivo Da Rocha Lima Filho
My name is Roberto and I am currently an Adjunct Professor at Federal University of Rio de Janeiro in Brazil, teaching economics and principles of finance for engineering undergraduate as well as postgraduate (executive MBAs) students with a myriad of background in the job market.
I deposited my doctorate thesis for a PhD in Science at the University of São Paulo, Medical School, in early 2014. Under the Department of Pathology/Medical Informatics, I managed to better understand the decision making process from traders and students with no financial background with a Neuroeconomics perspective, which is a novelty in the field of finance and economics.
I graduated in Economics in 2000 at the same University and while I was working within the financial markets, I got accepted to the University of Oxford, Queen Elizabeth House, to do a Msc in Economics for Development. After my background within the Financial Markets, I decided to pursue my career in the academia.
Notes
1. In this article, salaries, compensations and earnings are used commonly as synonyms.
References
- Antonakakisa, N., Cunado, J., Filis, G., & Gracia, F. P. (2017). Oil dependence, quality of political institutions and economic growth: A panel VAR approach. Resources Policy, 53, 147–16. doi:10.1016/j.resourpol.2017.06.005
- C. Álvarez, I., Barbero, J., & L. Zofío, J. (2016). A spatial autoregressive panel model to analyze road network spillovers on production. Transportation Research Part A, 93, 83–92. doi:10.1016/j.tra.2016.08.018
- Christou, C., Cunado, J., Gupta, R., & Hassapis, C. (2017). Economic policy uncertainty and stock market returns in Pacific-Rim countries: Evidence based on a Bayesian Panel VAR Model. Journal of Multinational Financial Management, 40, 92–102. https://doi.org/10.1016/j.mulfin.2017.03.001
- Doan, T., Litterman, R.B., and Sims, C.A. (1984). Forecasting and Conditional Projection Using Realistic Prior Distribution. Econometric Review, 3, 1–100. https://doi.org/10.1080/07474938408800053
- Enders, W. (1995). Applied econometric time series. Wyley.
- Holtz-Eakin, D. N., W. Rosen, H., & Rosen, H. S. (1988). Estimating vector autoregressive with panel data. Econometrica, 56(6), 1371–1395. https://doi.org/10.2307/1913103
- Koop, G., & Korobilis, D. (2016). Model uncertainty in panel vector autoregressive models. European Economic Review, 81, 115–131. https://doi.org/10.1016/j.euroecorev.2015.09.006
- LeSage, J. (1999). Applied econometrics using MATLAB. MATLAB Toolbox. https://www.spatial-econometrics.com/html/mbook.pdf
- Levinsohn, J., & Petrin, A. (2003). Estimating production functions using inputs to control for unobservables. Review of Economic Studies, 70(2), 317–342. https://doi.org/10.1111/1467-937X.00246
- Litterman, R. (1979). Techniques of forecasting using vector autoregressions. Federal Reserve Bank of Minneapolis Working Paper. no. 115: pdf.
- Litterman, R. (1984). Specifying VAR’s for macroeconomic forecasting. Federal Reserve Bank of Minneapolis Staff report. no. 92.
- Manuel Arellano, and Stephen Bond. (1991). Some Tests of Specification for Panel Data: Monte Carlo Evidence and an Application to Employment Equations. The Review of Economic Studies, 58(2), 277–297. http://www.jstor.org/stable/2297968
- Mavroeidis, S., Sasaki, Y., & Welch, I. (2015). Estimation of heterogeneous autoregressive parameters with short panel data. Journal of Econometrics, 188(1), 219–235. https://doi.org/10.1016/j.jeconom.2015.05.001
- Miranda, K., Martínez-Ibañez, O., & Manjón-Antolín, M. (2017). Estimating individual effects and their spatial spillovers in linear panel data models: Public capital spillovers after all? Spatial Statistics, 22, 1–17. https://doi.org/10.1016/j.spasta.2017.07.012
- Olley, G., & Pakes, A. (1996). The dynamics of productivity in the telecommunications equipment industry. Econometrica, 64(6), 1263–1297. https://doi.org/10.2307/2171831
Appendix
The algorithms are presented below for both MATLAB and STATA:
M-File MATLAB
% Panel VAR Calculation
nlags = 5; tight = 0.01; weight = 0.5; decay = 1.0; yt = data (:,3); xt = data (:,4:8);
result = bvar(yt,nlags,tight,weight,decay,xt);
prt(result);
% Impulse Response Function
nperiod = 10;
[m1 m2] = irf(result,nperiod,’o1’,’yt’);
Do-File STATA
label data “pia”
tsset sec year
sktest prod lab cap inst
regress prod lab cap inst ent exit
xtreg prod lab cap inst ent exit, fe
xtreg prod lab cap inst ent exit, mle
xtabond prod lab cap, diffvars(lab cap) inst(inst) lags(1) artests(2)
xtgls prod lab cap inst ent exit, panels(correlated) corr(ar1)
sqreg prod lab cap inst ent exit, quantiles(50) reps(20)
