
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
To improve the quality of the super-resolution (SR) reconstructed medical images, an improved adaptive multi-dictionary learning method is proposed, which uses the combined information of medical image itself and the natural images database. In training dictionary section, it uses the upper layer images of pyramid which are generated by the self-similarity of low resolution images. In reconstruction section, the top layer image of pyramid is taken as the initial reconstruction image, and medical image’s SR reconstruction is achieved by regularization term which is the non-local structure self-similarity of the image. This method can make full use of the same scale and different scale similar information of medical images. Simulation experiments are carried out on natural images and medical images, and the experimental results show the proposed method is effective for improving the effect of medical image SR reconstruction.
1. Introduction
With the continuous innovation of medical imaging technology and computer technology, medical image processing is becoming important in clinical diagnosis. It can help doctors fully understand the structure of the internal pathology of patients, and then an accurate treatment plan is developed. High-quality medical images can not only improve the level of clinical diagnosis, but also provide necessary support for medical research, teaching, surgery, etc. Commonly used methods of super-resolution (SR) reconstruction are interpolation methods, such as B-spline and bicubic interpolation etc. Through SR reconstruction, the clarity of medical images and the correctness of disease diagnosis, can be improved. Thereby it can help doctors to perform precise treatment on patients.
A single HR image is generated by one or more low-resolution images in the same scene based on SR method [Citation1]. And for SR method, it is the biggest difficulty to recover high frequency information lost during process of getting LR inputs [Citation2,Citation3].
Yang et al. [Citation4] propose a SR algorithm based on sparse representation. In this algorithm, FSS (Feature-Sign Search) method plans to generate low-resolution (LR) and high-resolution (HR) dictionaries by using the patch pairs of HR and LR image. LR dictionary produces the spare coefficients of LR image patches, and it uses the coefficients to produce the HR image patches based on the HR dictionary.
For each local patch, pre-learned dictionaries from a dataset of high quality example patches are selected based on Dong [Citation5]. In the process of reconstruction, non-local structure self-similarity (NLSS) and autoregressive model are considered as the regularization term. Dong’s method uses the self-similarity of the image that increases the accuracy and reliability accessed to the information. Therefore, it still uses the image database to train the global dictionary, and it cannot be sparse representation for all image patches. In order to further improve the reconstruction effect, A SR method based on adaptive multi-dictionary learning (MDL) was proposed by Pan [Citation6]. Firstly, patches of LR image pyramid which are packed into some categories are classified into one of these groups, if they meet special conditions. And then, corresponding dictionaries are generated for each group based on MDL.
This paper proposes an improved method based on adaptive MDL and structural self-similarity. In this method, we use the pyramid generated by structural self-similarity upper layer images as samples instead of Pan’s method. It uses the pyramid decomposition to obtain samples when training a dictionary, which will achieve more self-similar information of the different scales. In addition, the paper uses the top layer image of pyramid as the initial reconstruction image. SR image is reconstructed by regularization term using the non-local structure self-similarity of image. It also employs self-similar information of the same scale to reconstruct image. Experimental results demonstrate that the HR medical image reconstructed by the proposed method has good effect for medical images.
2. SR model
2.1. SR model based on sparse representation
Supposing
is an over-complete dictionary of M prototype signal-atoms, a sparse linear combination of these atoms can represent a signal. The signal vector can be expressed as:
(1)
(1)
is the sparse coefficient with very few
nonzero term. Solving an
-minimization problem can calculate the sparse decomposition coefficient, and it can be formulated as:
(2)
(2)
where
is a pseudo norm that counts the number of non-zero entries in
, and approximation error is influenced by a small constant
. Minimization
is converted to the convex
-minimization. It is an issue about NP-hard combinatorial optimization. According to sparse coding problem,
-norm is summarized as follows:
(3)
(3)
EquationEq. (3)(3)
(3) also can be written as the form of Lagrange polynomials:
(4)
(4)
where
represents the regularization parameter, it is a constant.
The single image SR problem can be presented as: a HR image of the same scene can be recovered by giving a LR image
. Assuming the LR image is the version of the solution
. And the version is blurred and down-sampled:
(5)
(5)
where
is a fuzzy filter, and
is a lower sampling operator. The process of solving
by
is the process of image SR reconstruction, which is to solve the following least squares problem:
(6)
(6)
The sparse representation prior on small patches of
is used to make HR images
satisfy the reconstruction constraint for a given LR input
.
is an image column vector reshaped from image
.
is a extracting-matrix, whose function is extracting patch
from
.
,
is the
patch (size:
) vector of
.
,
is defined to be a set of orthonormal sub-dictionaries.
can approximately express the sparse coding
,
and the reconstructed patches
are averaged to reconstruct the whole image
. And it can be described as:
(7)
(7)
where
represents a collection of all
. And
represents a collection of all sub-dictionaries
.
For , recovering the original image
from
is our goal. A super-resolution reconstruction model based on sparse representation through EquationEqs. (6)
(6)
(6) and Equation(7)
(7)
(7) can be summarized as follows:
(8)
(8)
-norm sparsity regularization term
is weighted by the constant
. And the
-norm sparsity is closer to the reweighted
-norm sparsity than using a constant weight according to Ref [13]. Therefore, EquationEq. (8)
(8)
(8) can be summed up as:
(9)
(9)
where
represents the weight assigned to
,
represents the coefficient associated with the
atom of
.
that can be obtained by the following formula:
(10)
(10)
where
is a constant,
is an estimated value of the first
iteration of
, and
is a small constant.
2.2. SR model combined with structure self-similarity
In general, many duplicate images contain a lot of redundant information. And the quality of reconstructed images is significantly improved. Therefore, a non-local self-similar regularization term based on sparsity of the image SR framework is proposed. In the whole image , similar patches
are found for each local patch
. If
, similar patch will choose a patch
.
,
are the current estimated value based on the preset threshold
. And the patch
within the first L closest patches is also selected to
, where L is also a preset threshold. The center pixel of patch
and
are
and
, respectively. The weighted average of
, i.e.,
is predicted based on
. The weight
, which is allocated to
is assumed as
, where
is a weight control factor. In this paper, the difference between
and
is used as a regularization term, i.e.
. So the sparse representation and structure self-similarity are combined to obtain the image super resolution reconstruction model:
(11)
(11)
where
is to balance the contribution of non-local regularization, it is a constant.
Then by merging the first term and third term, the simplified form of EquationEq. (11)(11)
(11) can be expressed as
(12)
(12)
where
(13)
(13)
A expresses the weight matrix, and
expresses the identity matrix.
3. Acquisition and training of adaptive multi-dictionary samples
3.1. Selection of samples
In order to get the missing high-frequency information, it is necessary to obtain the dictionary that contains the high-frequency information. In this paper, the dictionary training samples is consisted of image itself to be processed and the natural image database. The natural image database is mainly to select high resolution images with rich texture details. For the image itself, we generate the image pyramid by self-similarity to produce the training samples. It contains the image's own information, and the upper layer images of pyramid are selected as the samples of a dictionary. The principle of generating the image pyramid by self-similarity is as follows.
shows the input image , and we generate LR images
(
) as the lower layer images of the pyramid firstly. In the lower-resolution images (
or
), some similar patches (
and
) are searched where
is a source patch in
. A corresponding region (
or
) in
are determined for each patch (
or
). The corresponding region (
or
) depends on two factors: (1) the area of source patch
, and (2) the layer index of the found patch (−1 of
or −2 of
). In the end,
is moved to the corresponding position of the enlarged area
, and
is also the case.
is not exactly like
, and
is not exactly like
. So
can be obtained by
weighted, and the formula is as follows:
(14)
(14)
where their weights are
(15)
(15)
Figure 1. The image pyramid generated by self-similarity.
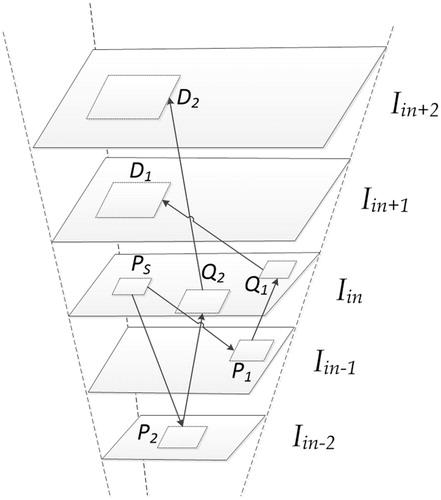
And controls the degree of similarity.
and
are denoted in the HR images in .
and
, which have some copied patches, have many undetected areas (i.e., in the image pyramid, some similar patches are not found by source patches in
). Uncovered area will be filled with the back projection to improve image resolution based on method [Citation6].
3.2. Training of adaptive multi-dictionary
As mentioned above, the dictionary has an important impact on the reconstruction results. In order to enrich the high frequency information contained in the dictionary, this paper adopts the method of combining the image itself and the natural images database. Firstly, we take the upper layer images of pyramid as the training samples . The semantic information is conveyed by the edge of image which is sensitive to human visual system. The high-pass filtering is used to obtain the feature of each patch with size
for the training samples
of clustering. Blocks only with a certain edge structure are used in dictionary learning to exclude the smooth patches from training. We select the intensity variance of image patch which is better than a threshold
. The selected image patch, denoted by
, and
is the high frequency component of
. The high frequency component patches
are clustered into K clusters by K-means algorithm, which is denoted by
,
, where
is the number of samples for each class that guarantee
. Then we compute class centers
and radius
for each class.
Similar with the upper layer images of pyramid, the high-pass filtering is used for the images of the natural image database. Abundant image patches are cropped from the natural images. The size of the image patch is , and we selected the patches whose intensity variances are better than a threshold
. The selected image patch is denoted by
, and
is the high frequency component of
. Then we compute the distance between
and the class centers
, which is denoted by
. If
,
is added to
, otherwise the image block is abandoned, where
is a parameter that is used to control the similarity degree between the image blocks and the class centers. After the above operation, the samples are expanded, and each type of expanded sample is recorded as
, where
is the number of samples after the expansion.
Then, according to the high frequency component samples , we can find the corresponding image block sample matrix
. The following objective function can formulate the design of sub-dictionary
.
(16)
(16)
where
is the representation coefficient matrix, and
is the parameter controlling the degree of sparsity. In order to reduce the amount of computation, the principal component analysis (PCA) is used to calculate the main parts for each sub-dataset
. An orthogonal transformation matrix
, which is generated by applying PCA, is set the dictionary, and it meets
. Then we will have
=
= 0. In order to obtain a dictionary
, the first
which is the most important eigenvectors in
is separated. In this way, the relationship of
-norm regularization term and
-norm approximation term in EquationEq. (16)
(16)
(16) is more balanced. The reconstruction error
will increase the decrease of
according to EquationEq. (16)
(16)
(16) . Considering the term
will reduce, the best value
of
can be prescribed for:
(17)
(17)
where
is the weight of the
norm sparse regularization term
. In the end, the sub-dictionary which is learned from sub-dataset
is
,
.
Finally, we seek an adaptive dictionary for the image patches to be reconstructed. Considering spanning the adaptive sparse domain, a sub-dictionary is assigned adaptively to each partial patch of .
needs to be estimated in advance, because it is not known at the beginning. We can take the top layer image of pyramid as the initial estimation of
.
represents the estimate of
, and
represents the local patch of
. For the centroid
, considering the high-pass filtered patch of
, the best fitted sub-dictionary to
is generated, which is of each cluster available. For
, the dictionary is influenced by the minimum distance between
and
, i.e.
(18)
(18)
3.3. Algorithm Flow
In the paper, in order to solve EquationEq. (12)(12)
(12) , we use the iterative shrinkage algorithm [Citation7]. The algorithm flow chart is shown in .
Figure 2. The algorithm flow chart of this paper.
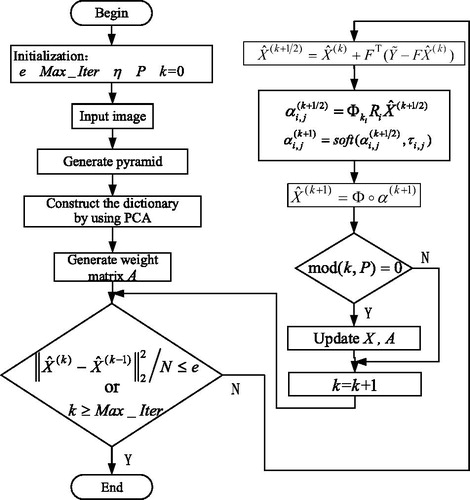
The overall algorithm process is as follows:
Initialization:
By the descending process of the image, we determine the down-sampling matrix
and the blurring matrix
The sub-dictionary
The weight matrix
The termination error
It is iterated on
The current estimation is updated using EquationEq. (19)
The sparse representation coefficients are updated using EquationEq. (20)
Re-update the current estimation
If
4. Experimental results and analysis
This section mainly presents the results of the SR reconstruction of medical images by this method. It also performs three sets of experiments in both noiseless and noisy cases. The three sets of experimental images (Head1, Head2, and Chest) are actually taken by the hospital, including MRI images and CT images. In the experiments, the degraded LR image is generated by a 7 × 7 gaussian kernel and an original image with a standard deviation of 1.6 make the degraded LR image. Then the image is down sampled by a factor of 3. Firstly, the low resolution color images are converted to ycbcr format. Finally, the bicubic interpolator is applied to the color components. We compare our method with two most advanced methods: the bicubic interpolation method and the ASDS method [Citation8]. The statistical experimental results are analyzed and discussed to verify the advantages of this method for medical image’s SR reconstruction. The results with noiseless are shown in and . The results with noise are shown in and .
Figure 3. Comparison of the reconstructed images of various methods for noiseless medical image (Equation1(1)
(1) ) (a) Original image (b) LR image (c) Bicubic (d) ASDS (e) Our.
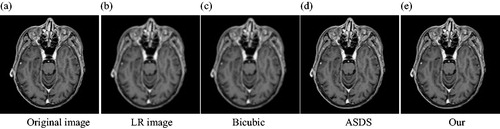
Figure 4. Comparison of the reconstructed images of various methods for noiseless medical image (Equation2(2)
(2) ) (a) Original image (b) LR image (c) Bicubic (d) ASDS (e) Our.
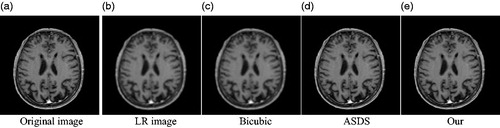
Figure 5. Comparison of the reconstructed images of various methods for noiseless medical image (Equation3(3)
(3) ) (a) Original image (b) LR image (c) Bicubic (d) ASDS (e) Our.
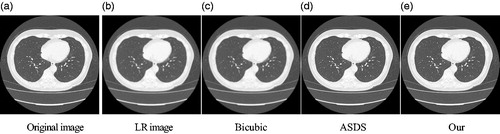
Figure 6. Comparison of the reconstructed images of various methods for noisy medical image (Equation1(1)
(1) ) (a) Original image (b) LR image (c) Bicubic (d) ASDS (e) Our.
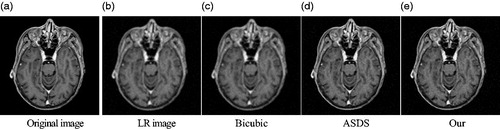
Figure 7. Comparison of the reconstructed images of various methods for noisy medical image (Equation2(2)
(2) ) (a) Original image (b) LR image (c) Bicubic (d) ASDS (e) Our.
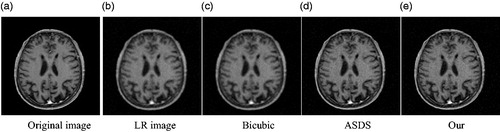
Figure 8. Comparison of the reconstructed images of various methods for noisy medical image (Equation3(3)
(3) ).
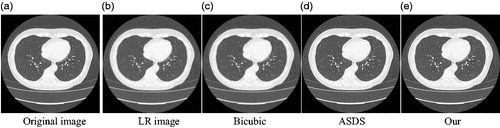
Table 1. Comparison of PSNR (dB)/SSIM of the medical images () based on various methods.
Table 2. Comparison of PSNR (dB)/SSIM of the medical images () based on various methods.
Firstly, show the reconstructed results for the three images of Head1, Head2, and Chest. The texture of the head and the texture of lungs in the chest can be observed clearly. The blur and noise conditions are greatly improved. Compared with the bicubic algorithm and the ASDS method, the medical images reconstructed by our method are of better quality, and more detailed.
Secondly, we compare our method with the two method for medical images respectively for quantitatively prove the advantages of our method. Evaluating the experimental results based on various methods use the SSIM and PSNR [Citation9]. The greater value of the PSNR indicates the quality of the reconstructed image and the reconstructed results are better. SSIM evaluates the structure differences between the reconstructed image and the high resolution image by SR. The greater the value of SSIM is, the better the reconstructed result will be. and list the SSIM and PSNR results, and it can be seen from the results in the table that the method presented in this paper has good results.
In addition, we compare the complexity and time consumption of the bicubic interpolation method, the ASDS method and our method. The calculation formula of time complexity is , where
is the frequency of the sentence with the largest frequency in the algorithm. The program of time consuming test method is run on Matlab R2014b, and the average time consumption of the 512 × 512 pixel test chart is calculated. The test results are shown in .
Table 3. Comparison of complexity.
Furthermore, we give the experimental results on the public image library for fully prove the advantages of our method. We randomly selected 20 high quality natural images from the sample database. shows the results of comparing our method with two most advanced methods: the bicubic interpolation method and the Yang method. From the result we can see the proposed method results achieve the most visual effect, which is more clearly compared with the other algorithms because more details are restored. Secondly, for quantitatively demonstrate the advantages of our method, we use PSNR and SSIM to evaluate the experimental results based on various methods. list the SSIM and PSNR consequence of these algorithms, where it can be seen that our method is more effective than others. The average PSNR gains over other methods are up to 3.4 dB and 2.57 dB. Compared with other methods, the average value of the SSIM gains up to 0.0706 and 0.0455, respectively.
Figure 9. Comparison of the reconstructed images of various methods for Butterfly image (a) Original image (b) Bicubic (c) Yang (d) Our.
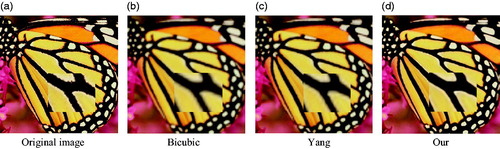
Table 4. Comparison of PSNR (dB)/SSIM of the reconstructed images based on various method.
5. Conclusions
In this paper, we introduce a single image super resolution reconstruction method based on adaptive MDL and structural self-similarity. The proposed method is the improvement for the existing adaptive MDL method. In this method, the image pyramid is generated by structural self-similarity, and the pyramid upper layer images are as samples, which will contain more self-similar information of the different scales than directly conducting the pyramid decomposition for the image itself. In addition, the paper uses the top layer image of pyramid as the initial reconstruction image and the image SR reconstruction uses the non-local structure self-similarity of the image as the regularization term. It also added the self-similar information of the same scale to the reconstruction image. Experimental results demonstrate that our method achieves better results in terms of all the visual perception and the parameters of PSNR and SSIM compared with multiple super resolution reconstruction methods.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Xie B, Duan ZM, Ma PG, et al. SR reconstruction algorithm of infrared image based on dynamic pyramid model[J]. Infrared and Laser Eng. 2018;001(1):277–282.
- Pan ZX, Yu J, Hu SX, et al. Super-resolution based on compressive sensing and structural self-similarity for remote sensing images. IEEE Transac Geosci Remote Sens. 2013;51(9):4864–4876.
- Zhao H, Wei JX, Pang ZH, et al. Wave-front coded super-resolution imaging technique. Infrared and Laser Eng. 2016;45(4):227–236.
- Yang J, Wright J, Huang TS, et al. Image super-resolution via sparse representation. IEEE Transac Image Proc. 2010;19(11):2861.
- Dong WS, Zhang L, Shi GM, et al. Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization. IEEE Transac Image Proc. 2011;20(7):1838–1857.
- Pan ZX, Yu J, Xiao CB, et al. Single image super resolution based on adaptive multi-dictionary learning. Acta Electronica Sinica. 2015;43(2):209–216.
- Dong WS, Zhang L, Lukac R, et al. Sparse representation based image interpolation with nonlocal autoregressive modeling. IEEE Transac Image Proc. 2013;22(4):1382–1394.
- Zhang A, Guan C, Jiang H, et al. An image super-resolution scheme based on compressive sensing with PCA sparse representation. In: Shi YQ, Kim HJ, editors. The international workshop on digital forensics and watermarking 2012. Berlin Heidelberg: Springer; 2013.
- Zhang X, Zhou W, Duan Z. Image super-resolution reconstruction based on fusion of K-SVD and semi-coupled dictionary learning. IEEE Signal and Information Processing Association Summit and Conference; 2017 December 13–16, Jeju, South Korea.