
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article studies the optimal control of batching equipment in the poultry processing industry. The problem is to determine a control policy that maximizes the long-term average revenue while achieving a target throughput. This problem is formulated as a Markov Decision Process (MDP). The developed MDP model captures the unique characteristics of poultry processing operations, such as, the trade-off between giveaway and throughput. Structural properties of the optimal policy are derived for small-sized problems where batching equipment utilizes a single bin. Since the MDP model is numerically intractable for industry-sized problems, we propose a heuristic index policy with a Dynamic Rejection Threshold (DRT). The DRT heuristic is constructed based on the salient characteristics of the problem setting and is easy to implement in practice. Numerical experiments demonstrate that DRT performs well. We present an industry case study where DRT is benchmarked against current practice, which shows that the expected revenue can be potentially increased by over 2% (yielding an additional revenue between 750,000 and 2,270,000 Euros per year) through the use of DRT.
1. Introduction
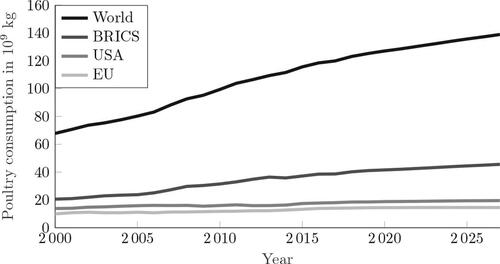
Global poultry meat consumption is projected to grow in the foreseeable future (OECD, Citation2017), as shown in . Especially emerging markets such as Brazil, Russia, India, China, and South-Africa (BRICS) contribute to this projected growth. In more developed markets such as Europe or the United States, the demand for poultry products is saturated, which has led to increased pressure on the profit margins. However, retailers are large and powerful, and are able to put much of this pressure on their suppliers instead (Manning and Baines, Citation2004). Consequently, poultry processing plants experience increasing financial challenges, forcing them to explore new avenues for cost reduction in order to remain competitive. In this article, we consider the perspective of a poultry processing plant that faces demand from retailers, and aims to maximize their revenue through novel production control policies.
Figure 1. Past and forecasted poultry consumption per year for selected regions (OECD, Citation2017)
Farmers breed broilers before delivering them to poultry processing plants. At these plants, broilers are processed into a variety of final products (e.g., fillets, legs or wings). A processing plant using high-end equipment is typically capable of processing 15,000 broilers per hour for 16 hours per day. Each broiler can be sold as whole or processed into different parts, and packaged according to customer demand. The majority of demand comes from retailers, who impose a strict daily target throughput on poultry processing plants, i.e., they require a minimum amount of products produced per day. In addition, retailers require that each delivered (retail) batch contains a pre-specified target weight and pay a fixed price per batch of products. Additional weight over this target weight is not paid for, and is called giveaway. These retail batches are the packaged products one can purchase at supermarkets. The remaining demand comes from customers such as restaurant chains, who impose no target throughput. Such customers order large batches of products (bulk batch) rather than retail batches. Processing plants are paid for all weight in a bulk batch (i.e., no giveaway), although the price per unit weight of a bulk batch is lower compared with a retail batch.
Batchers are machines used to produce retail batches. shows a grader, which is a batcher typically used in poultry processing plants. A schematic overview of this machine is shown in . Each item arriving on the conveyor is weighed and placed in one of the available bins or rejected. A grader producing retail batches is allowed to reject items and send them to a downstream process that produces bulk batches. For practitioners, this leads to a critical trade-off between giveaway and throughput: by rejecting items, the giveaway can be reduced. However, rejecting items lowers the throughput, and may lead to a failure to comply with the target throughput. Therefore, we consider the following problem setting. A grader produces retail batches with a given target weight and target throughput. Each completed retail batch has a fixed value, and all rejected weight is processed as bulk batches, which have a lower value per gram. The goal is to simultaneously achieve the target throughput and maximize the overall revenue, by either allocating items to a bin in the grader, or rejecting them.
Figure 2. The batcher considered in this article.
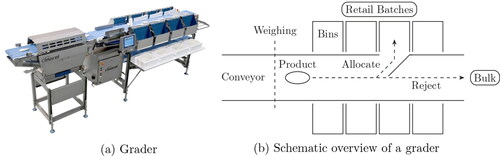
The problem is relevant in practice, as the profit margins of processing plants are decreasing and giveaway reduction is an important avenue for cost reduction. For example, in a high-end processing plant, each percentage of giveaway reduction producing fillet batches is worth over a million Euro per year in revenue. Grader algorithms used in practice are able to control the fraction of items allocated to retail batches, but cannot control the throughput directly. It is challenging to achieve the target throughput, as throughput and giveaway are conflicting objectives, and the impact of the giveaway–throughput trade-off on the total expected revenue is not fully understood.
To address these challenges, we formulate a Markov Decision Process (MDP) model capturing the trade-off between giveaway and throughput. For a special case of the problem with a single bin and no throughput constraint, we show that optimal policies have a threshold-type structure on a subset of the state space. Due to the curse of dimensionality, the MDP model cannot be solved for industry-sized problems. In order to remedy this problem, a heuristic algorithm is developed, that is capable of achieving a given target throughput while minimizing the giveaway.
The heuristic introduced in this article is shown to be competitive with the MDP formulation for small-sized problems. The developed algorithm significantly outperforms the best-known heuristic, increasing revenue by up to 5% for the same target throughput. Testing this algorithm on a practically-relevant benchmark (provided by our industry partner) shows an increased revenue in all studied settings. In particular, our numerical analysis estimates that the revenue can potentially be increased between 750,000 and 2,270,000 Euros per year. Lastly, the revenue is studied for different target weights, throughput requirements, and relative values of bulk batches compared with retail batches. In numerical experiments, we anticipate revenue improvements up to 15% between different production settings, illustrating the high sensitivity of revenue to the production setting.
This article is organized as follows. In Section 2, literature relevant to this problem and the proposed algorithm are discussed. Next, Section 3 introduces the model describing the grader, item weights, and performance measures. Section 4 discusses heuristic grader policies, and the proposed extension to setting a target throughput. Simulation experiments are presented in Section 5, and our conclusions and recommendations for future work are summarized in Section 6.
2. Literature
The grader considered in this article has the property that products arrive one-by-one, products must be allocated or rejected immediately, and the grader can add products to batches in one of its bins. The problem of minimizing giveaway using such a batcher is known as an online K-bounded bin-covering problem with rejection. Online refers to the type of arrival process, K refers to the number of bins, and the bin-covering problem refers to the challenge of minimizing the long-term average overfill (giveaway) per bin.
Packing problems such as the bin-covering problem have been widely studied. Frequently, stylized off-line or unbounded problems are considered, which permit sorting of items and have an unlimited number of available bins. However, these assumptions might not be realistic for most production settings, as equipment and items have physical limitations. In this context, heuristics are typically necessary to deal with practically-sized problems. Csirik et al. (Citation2001) introduce and analyze the Sum-of-Squares (SS) algorithm for bin covering that is online and bounded. Ásgeirsson (Citation2014) introduces a prospect function to forecast the eventual giveaway of a bin and uses this function to develop algorithms for the online and bounded case. Similar to the prospect function, Peeters et al. (Citation2017) introduce an index policy to predict giveaway and control multiple graders in parallel. Some research considers bin-covering problems with the option to reject items. Most algorithms developed in this context require a partitioning of item weights or an unbounded setting (Dósa and He, Citation2006; Correa and Epstein, Citation2008). Lastly, Peeters et al. (Citation2019) introduce a heuristic based on an index function to control the throughput in an online and bounded setting. To the best of our knowledge, only Peeters et al. (Citation2019) consider a problem setting similar to ours. However, Peeters et al. (Citation2019) focus soley on developing a heuristic solution, and conduct a simulation study to assess its performance. In contrast, we build a stochastic optimization model for an online bin-covering problem with rejection, and exploit the structural properties of optimal policies. In addition, we enhance the heuristic proposed by Peeters et al. (Citation2019) and study its performance both analytically and numerically.
Some studies employ exact methods such as Markov chains to solve packing problems. For instance, Asgeirsson and Stein (Citation2006) and Asgeirsson and Stein (Citation2009) utilize Markov chains to predict giveaway in different system states, and use the information to allocate products in their Min-Bin-State-Cost algorithm. Both consider an online and bounded setting. Coffman Jr et al. (Citation1993) model the Best Fit algorithm as an infinite multi-dimensional Markov chain to analyze its performance. While online, Best Fit can only be used in an unbounded setting. Finally, Ásgeirsson (Citation2014) introduces an MDP formulation of the online and bounded problem, and develops new heuristics based on the resulting optimal policies. In the current article, we continue the line of research of Asgeirsson and Stein (Citation2006, Citation2009); Ásgeirsson (Citation2014); Peeters et al. (Citation2017); Peeters et al. (Citation2019). They each study policies that utilize giveaway prediction in the form of index-type policies.
We summarize our contributions as follows:
We study a practically-relevant problem of optimizing batching and rejection decisions, and develop an MDP formulation (and a corresponding Linear Program formulation) for an online K-bounded bin-covering problem with rejection. Our model captures the salient features of poultry processing operations, such as, the trade-off between giveaway and throughput.
We analyze the structural properties of optimal policies, and show that optimal policies have a switching-curve structure under certain special cases (i.e., there exists a certain threshold value on item weight and bin weight, such that, it is optimal to only reject items when the system’s state exceeds these thresholds). However, we show that this switching-curve structure exists only for a subset of the state space (so called closing-states) under a special case of the problem with a single bin and no throughput requirement.Footnote1
To solve industry-size problems, we develop a heuristic based on index policies. Our proposed heuristic adopts dynamic rejection thresholds to manage the giveaway–throughput trade-off. In addition, we prove that the proposed heuristic achieves the target throughput.
We present an industry case study to illustrate the use of the optimization approach and quantify its potential impact on practice. In addition, numerical experiments show that our proposed heuristic outperforms other best-known heuristics (e.g., Peeters et al. (Citation2019), and current practice).
In summary, our models formalize our understanding on the online bin-covering problem in the poultry processing industry, and our results inform practitioners on the potential impact of the giveaway–throughput trade-off on the long-term average revenue.
3. Model
This section describes the problem of controlling a grader, and models the batching process. Section 3.1 provides a formal description of the grader, which is used in Section 3.2 to introduce the MDP model and corresponding Linear Program (LP) formulation. Structural results for the special case of a single bin with no throughput constraint are presented in Section 3.3. A summary of notation used throughout the paper is provided in online Appendix A.
3.1. Grader model
In practice, the grader is typically dedicated to a certain product type (e.g., fillets). In this setting, the grader is tasked with allocating items (e.g., fillets) to bins, or letting them pass to a bulk batching station as follows. Items arrive on a conveyor belt at the grader and are weighed to the nearest integer gram. The set of observed weights is and p(w) is the probability that a product weighs w grams. The grader can place an arriving item in one of its K available bins or reject it. Bins are labeled 1 through K, and the set of available bins is
When bins are filled to their target weight B or more, they are emptied instantaneously (i.e., the target weight for each bin is B, and hence, giveaway is obtained when the weight of a bin exceeds the target weight B). The weight in bin
is indicated as
The interested reader can find a more detailed description of the production process in Peeters et al. (Citation2017).
Let μ denote the average item weight and T the average inter-arrival time of products. So is the average weight arriving per time unit. Suppose that the due date of an order of Q batches with target weight B is D time units from now. Then the long-term target throughput of batched weight per time unit is
which should be less than
This translates to a target of batching a fraction
of the arriving weight per time unit. Hence, the goal is to allocate or reject items such that the revenue is maximized, under the condition that in the long term (at least) a fraction q of the arriving weight is batched. In Section 3.2, we present an MDP formulation of this problem.
3.2. MDP model
To define the MDP model, we need to specify states, actions, rewards and transitions. Decision epochs correspond with the arrivals of items. State records the weights in all bins just before arrival of an item as well as the weight of the arriving item. Action
denotes rejection of the arriving item if a = 0 and allocation of the item to bin a if
The normalized value of retail batches is 1 per gram and the normalized value of rejected weight is rr per gram, where
The revenue for giveaway is zero, so the value of a batch of size
is equal to B. The revenue for batched weight is incurred when the batch is completed. The reward of action a in state
is denoted by
and given by
The probability of making a transition from state to
when taking action a is denoted by
This transition probability is given by
(1)
(1)
where the function e(x) is defined as
The objective is to maximize the long-term average reward per item, provided the throughput target is met. To do so, we employ a LP formulation of the MDP (Derman, Citation1970). Let xsa denote the long-term average fraction of times action is taken in state
To formulate the throughput constraint we note that the average weight per item allocated to the grader is
(2)
(2)
The allocated weight can be divided into throughput weight and giveaway. Throughput weight is defined as the weight that is added to a batch below the target weight, and giveaway is the weight that is added more than the target weight of a batch. The long-term average giveaway per item is
(3)
(3)
where the giveaway function g(x) of a bin with weight
is specified as
(4)
(4)
Subtracting giveaway (3) from the allocated weight (2) yields the long-term average throughput weight per item. The throughput constraint states that this should be greater than or equal to a fraction q of the average item weight μ, in other words
The LP formulation of the MDP now reads as follows:
(5a)
(5a)
(5b)
(5b)
(5c)
(5c)
(5d)
(5d)
(5e)
(5e)
The objective of maximizing the long-term average reward per item is expressed by (5a). EquationEquations (5b)(5b)
(5b) are the balance equations. EquationEquations (5c)
(5c)
(5c) and Equation(5d)
(5d)
(5d) are the normalization equation and the throughput constraint, respectively.
The above LP formulation may have no feasible solutions, i.e., the target of batching a fraction q of the arriving weight per unit may not be achievable. The LP problem below determines the maximal achievable target throughput
(6a)
(6a)
(6b)
(6b)
(6c)
(6c)
(6d)
(6d)
The following theorem presents a necessary and sufficient condition for feasibility of the MDP.
Theorem 1.
LP problem (5a)-(5e) has a feasible solution if and only if
Proof.
LP problem (6a)-(6d) is feasible, since the balance Equationequations (6b)(6b)
(6b) are feasible. Let
denote the solution with maximal target throughput
Then
is a feasible solution of (5b)-(5e) if
On the other hand, if
there can be no feasible solution of (5b)-(5e), since this solution would yield a target throughput exceeding
which the maximal throughput. □
3.3. Structural results
To study the structural properties of optimal policies, we now consider a special case of the problem with a single bin (K = 1) and no throughput constraint. We focus on this special case because the theoretical analysis (Section 3.3) and numerical experiments (Section 5.3) indicate that optimal policies do not necessarily exhibit a structural behavior (even for the special case with a single bin). All proofs are available in online Appendix B.
To exclude that it is optimal to reject every arriving item, we assume in this section that
(7)
(7)
where ga is the average reward of the always-accept policy and
is the average reward of the always-reject policy. Let
denote an optimal action in state (v, w). Next, we derive structural properties of optimal actions in states (v, w) for which
Hereafter, these states will be referred to as closing-states.
Theorem 2.
For states (v, w) with there exist
such that
for
, and
for
For a given bin level v, Theorem 2 characterizes the structural properties of optimal policies for closing-states. In particular, Theorem 2 indicates that, for given bin level v, there exists a threshold from which it is optimal to only reject items. This makes sense: once it is profitable to reject an item, this is also profitable for heavier items, as they result in the same immediate reward B but lead to higher giveaway. The next theorem is symmetrical to Theorem 2, stating that, for given item weight w (instead of bin level v), there exists a threshold from which it is optimal to only reject items.
Theorem 3.
For states (v, w) with there exist
such that
for
, and
for
For closing-states (v, w) with Theorems 2 and 3 indicate that rejection thresholds exist in both w and v. From a practical perspective, this result means that optimal policies have a switching-curve structure for closing-states. A visual representation of optimal policies are provided in for a problem setting with a single bin and no throughput constraint. As illustrated in , optimal policies have a switching-curve structure for closing-states, although it is hard to derive structural properties on other parts of the state space.
In realistic settings, the state space of the MDP model will be “too big” for numerical calculations, i.e., the size of the state space is and the size of the action space is k + 1. Observe that the space space grows exponentially in the number of bins k. For a standard industry-size problem with K = 8 bins (as presented in Section 5), the state space can easily reach a magnitude of 1022 states. Consequently, we turn to efficient approximate methods for online bin-covering problems. In Section 4, we present heuristic methods for controlling the grader with rejection.
4. Heuristic policies with rejection
Heuristic policies have been successfully used in bin-covering problems in a practical setting (Ásgeirsson, Citation2014; Peeters et al., Citation2017, Peeters et al., Citation2019). In this section, we formally describe policies that are typically used and motivate their use in our specific setting. Then, these policies are extended to allow for rejection of items.
First, we introduce some notation. For any allocation policy, the grader evolves as a Markov chain on state space In the following we assume this Markov chain is irreducible. After N items have been processed, the total throughput weight is denoted as the random variable
the total giveaway as
and the total rejected weight as
When item N + 1 arrives with weight
and finds weights
in the K bins (so the Markov chain is in state
), these quantities are adapted depending on whether item N + 1 is accepted (
) or rejected (a = 0). Consistent with Peeters et al. (Citation2019), this update procedure is modeled in (8):
(8)
(8)
Let wN denote the total weight of the first N items. Then we have:
(9)
(9)
By defining the fraction of throughput weight giveaway
and rejected weight
we obtain from (9) that:
(10)
(10)
Since the Markov chain is finite and irreducible, the time averages and
converge as
with probability 1. Hence, also the long-term fraction of throughput weight
giveaway
and rejected weight
exist and, by (10), satisfy
(11)
(11)
Clearly, the long-term average revenue per gram is and the long-term average loss per gram is
Below we describe heuristic policies that try to minimize
provided
as
4.1. Heuristic grader policies
This section introduces a type of heuristic policy that previously has been used to control poultry product batchers see Ásgeirsson (Citation2014); Peeters et al. (Citation2017) and Peeters et al. (Citation2019). These types of policies are known as index policies, and are modeled in (12)-(18) Peeters et al. (Citation2017). Let function f(v) be the loss of a bin filled to level and let
be the expected loss of a bin with level v, assuming that the bin is filled with items with weight distribution p(w). Hence,
can be calculated recursively as
(12)
(12)
where the random variable W denotes the weight of an arriving item. Index policies use the loss function
to assign items to bins, attempting to minimize the long-term giveaway. In this setting, Ásgeirsson (Citation2014) proposes differential and ratio policies for selecting a policy-optimal bin
These policies are specified in (13) and (14), respectively:
(13)
(13)
(14)
(14)
The corresponding policy-optimal value per state for the differential and ratio policies are given by
(15)
(15)
(16)
(16)
A well-performing policy in Ásgeirsson (Citation2014) is the ratio policy using a PRospect Exponential loss function (PRE), which is of the form
(17)
(17)
where β is a discount factor between zero and one. Peeters et al. (Citation2019) apply the differential policy using a loss function of the following form:
(18)
(18)
This policy is referred to as the Index Policy with Power function (IPP). Depending on the power α, giveaway can be neglected (α = 0), discounted (), considered directly (α = 1), or amplified (
). Peeters et al. (Citation2019) experimentally observe that the power α minimizing giveaway is always between zero and one. They use the following iterative procedure to tune α. Initially set
and estimate the giveaway
through simulation. Step 1) is to consider
with
If either value yields lower giveaway, update α to the one with lowest giveaway. Step 2) is to consider
with
and update α if it improves upon the giveaway. The procedure is repeated until the step size
in step A is sufficiently small. In the next section, index policies are extended to allow for rejection of items.
4.2. Rejection threshold
An index policy assigns an arriving item to bin yielding the highest reduction in expected loss
where
and
are shorthand notations for
and
respectively. Clearly,
allows for a direct comparison between states: states with high
may be preferable. Following this observation,
can be used to decide whether an item should be accepted or rejected. Ásgeirsson (Citation2014) applies this idea to control the number of accepted items and introduces a rejection threshold R: an item is accepted if
and rejected otherwise. Threshold R indirectly controls both giveaway and fraction of allocated items. illustrates the threshold R = 0 together with index values
and
for a discrete Normal item weight distribution
(see Section 5.1).
Figure 3. Maximum and minimum indexes per bin level v.
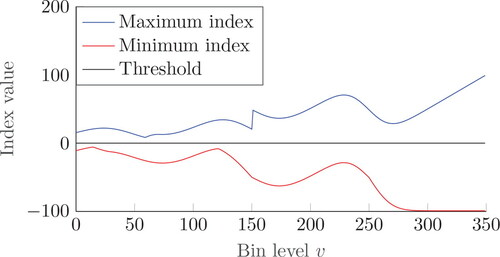
Interestingly, shows that the range of index values varies strongly. As a result, trial-and-error will be necessary to determine a threshold R that yields the desired throughput, if it exists. Moreover, suggests, by increasing the threshold R, that the system may end up in a situation where for each bin
So all arriving items will be rejected, and the target throughput will never be achieved. In order to prevent this situation and to set the throughput target directly, we propose to dynamically update the threshold. That is, let RN denote the threshold value after having processed N items, then item N + 1 is accepted and assigned to
if
and rejected otherwise, and the threshold is updated as follows:
(19)
(19)
where
is the decision for item N + 1, and C1 and C2 are positive constants. Clearly, an item weight that contributes to the throughput is scaled by C2 and increases the threshold, and an item weight that does not, is scaled by C1 and decreases the threshold. Below we first heuristically argue how to choose the constants C1 and C2 such that the target throughput q is achieved. From (19) we readily obtain:
where R0 is the initial threshold, and by substituting (9):
(20)
(20)
The total change in threshold value after N items is
(21)
(21)
Normalizing by the total processed weight wN, yields the threshold displacement per processed gram, which by substitution of (11), can be written as
(22)
(22)
As we obtain the long-term threshold displacement per processed gram:
(23)
(23)
assuming that the limit
exists. Clearly, if
then
as
and all items will be rejected, and if
then
and no items will be rejected. Hence, to be able to achieve the long-term target throughput
we have to impose
yielding:
(24)
(24)
The goal of the grader policy is to achieve the target throughput, So we set
(25)
(25)
If C1 and C2 satisfy (25), then we claim that, by using an index policy with threshold RN updated according to (19), the throughput converges to the target q. To support this claim consider again (22). By substituting (25), we find that after N items have been processed:
(26)
(26)
For the case where case it follows that
As a result, the threshold increases and fewer items will be accepted. Similarly, if
it follows that
In this case the threshold decreases, such that more items will be accepted instead. In conclusion, if the throughput deviates from the target, the threshold updates will attempt to push it back.
To make this claim rigorous, note that the grader now evolves as a Markov chain with states where
is the set of possible values for the threshold R. To obtain a countable set
we make the (mild) assumption that the target throughput q is a rational number. By (25), this implies that C1 and C2 are also rational, provided C is also chosen as a rational number, say
and
for some integers
Then
consists of all grid points
Thus, the state space
is an infinite strip of grid points. The state transitions are specified by (1) and (19). Since
is bounded (as the weight distribution is finite), it follows that in states
with R sufficiently large, items are always rejected and transitions are directed to states with a smaller threshold. Thus, these states are transient. However, to prevent the Markov chain escaping to R = – ∞ (and no items will be rejected anymore), we have to satisfy a mean drift condition (Neuts, Citation1995) that states that the mean change of R in states
with R sufficiently small, is positive. More formally, the mean drift condition states that, if
(27)
(27)
then the Markov chain on the infinite strip
is stable. In (27), the random variable W denotes the item weight and
is the random content of the bin to which the item is allocated, in the finite Markov chain on
for the grader with no rejection. Substituting (25) into (27), we get
(28)
(28)
Note that the right-hand side corresponds to the long-term fraction of throughput weight for the grader with no rejection. Hence, for the Markov chain with a dynamic rejection threshold to be stable, the target q should be less than the maximal achievable throughput. If this Markov chain is stable, then indeed the limit exists and
from which we can conclude, by (23), that
Summarizing, we proved the following result.
Theorem 4.
An index policy employing a rejection threshold that is dynamically updated according to (19) achieves target throughput q provided constants C1 and C2 satisfy (25) and q satisfies (28).
This approach to equip an index policy with a rejection threshold that is dynamically updated according to (19), is summarized in Algorithm 1, which will be referred to as index policy with Dynamic Rejection Threshold (DRT).
Algorithm 1.
Index policy with Dynamic Rejection Threshold (DRT).
Choose C > 0 and set C1, C2 according to (25). Initialize threshold R0. Set N = 0 and repeat the following steps:
Determine the policy-optimal value
for item N + 1 with weight
Allocate item N + 1 to bin
Reject item N + 1. Calculate
end.
The constant C scales the step size to adapt the rejection threshold. The larger C, the larger the average step size. The scheme proposed in Peeters et al. (Citation2019) to dynamically adapt the threshold assumes a fixed constant C = 1. In Section 5, we will investigate through a simulation study the effect of the choice of C on the giveaway throughput
and convergence to the target throughput q. For this study we investigate different index policies in addition to DRT.
5. Numerical results
In this section, we specifically aim to understand: (i) whether DRT can manage the throughput–giveaway trade-off; (ii) how DRT performs compared to the best known algorithms from practice and literature as well as MDP; and (iii) the impact of the production setting (target throughput, target weight, relative value of bulk batches) on the revenue. In order to address these points, we first describe the settings under which the experiments are performed. Then, we investigate the behavior of DRT through a numerical study performed in Matlab. In this study, the sensitivity of DRT to the scale parameter C is tested first. The best known algorithm in the literature is the Index Policy with Power function and Throughput target q (IPPT(q)) which is proposed in Peeters et al. (Citation2019), which utilizes the differential policy of (13). We conduct a simulation study that compares DRT, IPPT(q) and MDP under different settings. Finally, we benchmark the revenue generated by using DRT against results provided by our industrial partner, and we study the impact of different production settings on the revenue.
5.1. Parameter and problem settings
The following settings are used in the numerical experiments. A discretized Normal distribution is used to generate product weights. That is, an item with weight w is sampled with probability
where
is the density of the Normal distribution with mean μ and variance
In all experiments we use μ = 100, σ = 15,
and
The discretized Normal distribution is denoted as
The grader uses K = 8 bins. Ásgeirsson (Citation2014) showed that target weights that are (close to) a multiple of the mean item weight (for example, B = 300) generally yield low giveaway, and that the opposite is true for target weights that are far from a multiple of the mean item weight (such as B = 350). These cases are referred to as easy and hard, respectively. In the experiments we consider both easy and hard cases. Additionally, target throughputs in the range of zero through one are studied. Lastly, the relative value of bulk batches to retail batches per gram is based on practice, and typically ranges from 0.7 to 0.9. In the experiments, target weight, target throughput, and relative value of bulk batches are varied to illustrate the sensitivity of the performance in terms of revenue.
As mentioned in the previous section, we equip DRT with different index policies. In particular, we study IPP and PRE with the differential policy (13) or ratio policy (14). For each application of DRT we initialize Furthermore, DRT in combination with an index policy has two important parameters: the scale parameter C and the parameters α and β in the loss functions (18) and (17) of IPP and PRE, respectively. For given value of C, α or β are tuned to minimize giveaway in A = 9 steps of the procedure described at the end of Section 4.1. In the next section we focus on how to tune the parameter C. In every simulation run, the order size Q is fixed at 10,000 batches, corresponding to a large customer order. In other words, items are generated until 10,000 batches are completed.
5.2. Parameter tuning
This section presents our findings regarding the impact of the scale parameter C in DRT. For expository purposes we have selected DRT in combination with IPP and a differential policy. Target weight B = 350, and target throughput q = 0.5 are used in the analysisFootnote2. We investigate how changes per item N. The results for the first N = 1000 items using
and
are plotted in .
Figure 4. Throughput after N items.
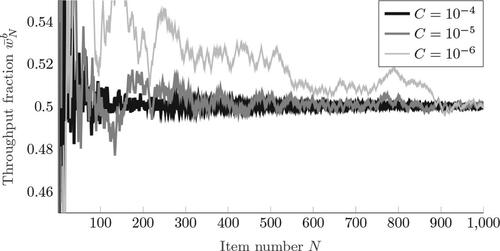
suggests that for all values of C the throughput approaches the target q = 0.5. Convergence is faster for larger values of C. Furthermore, shows that this behavior is caused by increased sensitivity of the threshold with respect to item allocations. Higher values of C result in higher variability of RN. Most importantly, these figures suggest that DRT indeed approaches the target throughput q as N gets sufficiently large. So what prevents us from selecting an arbitrarily large value of C? This question is answered in , which shows the absolute deviation from the target throughput () and giveaway
() for different values of C and different policies. In particular, we study IPP and PRE with differential and ratio policies.
Figure 5. Value of threshold after N items.
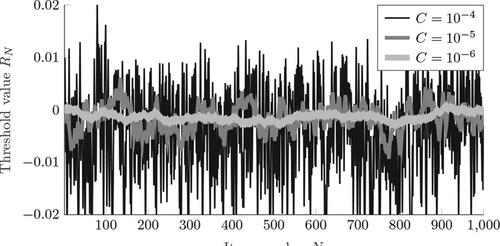
Figure 6. Sensitivity of various policies to C.
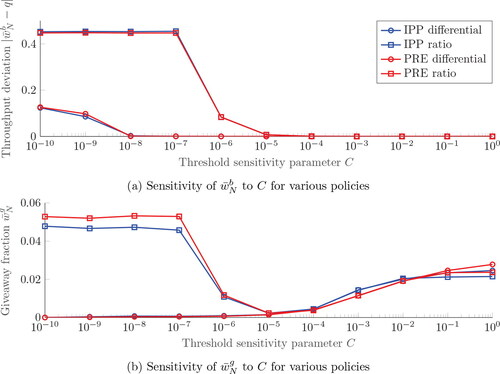
The data in presents a clear pattern, where DRT is no longer able to achieve the target throughput for small values of C. As observed in , convergence to the target throughput is slower for smaller values of C, suggesting that there has been insufficient time for the algorithm to converge. As a result, for smaller order sizes, the minimal feasible value of C and corresponding giveaway should be larger. However, deviations from the target throughput occur much sooner for the ratio policies than the differential policies, as the range of values obtained for ratio policies is generally much greater. The disadvantage of ratio policies is further compounded by their poor giveaway performance for low values of C.
Instead, sensitivity of the giveaway of both differential policies is low from through
where the deviation from the target throughput is small. We conclude that differential policies outperform ratio policies, with minimal difference between IPP and PRE. Due to their similar hallmarks, we proceed with DRT equipped with IPP utilizing a differential policy, although PRE appears equally suitable. In the following, we will simply refer to this combination of DRT and IPP as DRT. Finally, note that the value of the PRE differential policy for C = 1 corresponds to the peformance of the IPPT(q). We conclude that employing DRT leads to a substantial giveaway reduction of almost 2.4 percentage points when using
with an IPP differential policy, illustrating the added value of DRT.
Based on these findings, we propose the following procedure to tune C. The idea is to set C as small as possible (for minimal giveaway), while still achieving the target throughput. The initial value of C is taken to be one, as suggests that this value achieves fast convergence to the target throughput. Subsequently, C is progressively decreased by division of 10 (to limit calculation time) as long as the permitted deviation δ from the target throughput is not violated. This procedure is used to conduct the remaining experiments, where tolerance δ is taken to be 0.1% of the target throughput q.
5.3. Numerical analysis of small-scale problems
In this section, we numerically explore the structure of the optimal policy for the single bin problem K = 1, and compare the performance of the DRT and IPPT(q) algorithms against the optimal solution produced by the MDP model.
5.3.1. Structural analysis
First, we consider a special case with K = 1 and no target throughput requirement, which has been studied in Section 3.3. The optimal policy is obtained by the value iteration algorithm (Puterman, Citation2014). For a specific problem instance with K = 1, B = 350 and normalized revenue of rejected weight per gram, shows the optimal actions in states (v, w). The closing-states (i.e., states (v, w) where v + w = B) have been marked white for clarity.
Figure 7. Optimal action per state for K = 1, B = 350, and
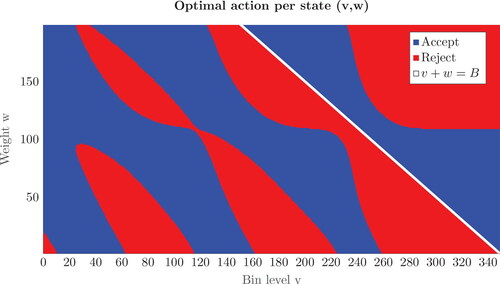
We observe from that optimal policies do not have a simple structure. Only in the area of closing-states (as marked white in ), do we see that the optimal policy is characterized by a switching curve. This insight aligns with Theorems 2 and 3. However, shows that optimal policies do not have a structure for non-closing-states. Therefore, illustrates that structural insights cannot be easily derived for non-closing states, even when we consider a special case with single bin and no throughput requirement. These observations also substantiate the analytical difficulty and practical challenges associated with our problem setting.
5.3.2. Performance of heuristics
Next, we benchmark DRT and IPPT(q) against the optimal solution obtained by the constrained MDP in Section 3.2. In addition, the solution (OPT) of the unconstrained MDP is determined to quantify the impact of the throughput constraint on the revenue. The constrained MDP is solved to optimality using LP solver in Matlab. and the unconstrained version is solved by value iteration. In order to keep the solution time tractable, a small-scale problem is considered.
We take K = 1, and the target weights and item sizes are scaled down with a factor 10 compared with the previously considered problem instances. Specifically, we consider batch sizes B = 30 and 35, and item weights The maximum and minimum item weights are taken to be
and
respectively. Under these settings, the standard deviation of the discretized distribution deviates less than
from σ. Furthermore, both
and 0.9 are considered. The target throughput is varied from q = 0 through q = 0.8 in steps of 0.1. A total of 10,000 batches are completed per parameter settings for both DRT and IPPT(q).
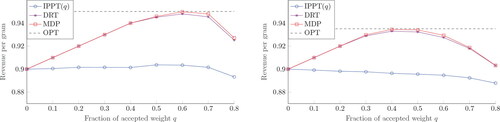
shows that the optimal revenue per gram is lower for the hard case B = 35 than for the easy one B = 30. Additionally, for all algorithms, the revenue is increasing in the target q, which is as expected, since batched weight (with little giveaway) is more valuable than rejected weight. Furthermore, the difference in revenue between the MDP solution and DRT is negligible, as it is less than 0.0022 in all cases. However, there is a significant gap between IPPT(q) and DRT, illustrating the impact of tuning the scale parameter C on the revenue.
Figure 8. Revenue per gram for and B = 30 (left) and 35 (right).
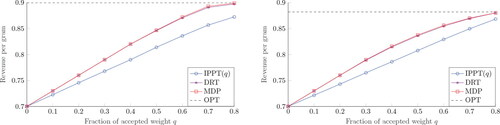
The second instance with higher value of rejected weight () is presented in . We observe that the revenue curves are no longer strictly increasing and the fraction of accepted weight maximizing revenue is smaller than in . Again DRT performs close to MDP, with the difference in revenue staying below 0.0026. For all algorithms, the revenue per gram is significantly higher than in case
For example, the gap in revenue between the MDP curves in and ranges from 0.023 to 0.2. Lastly, it is concluded that DRT significantly outperforms IPPT(q) in all experiments.
Figure 9. Revenue per gram for and B = 30 (left) and 35 (right).
In conclusion, for small-scale problems, DRT results in near-optimal performance in all settings, and significantly outperforms IPPT(q) in terms of revenue. Next, we will study DRT in a case study.
5.4. Managerial insights: An industry case study
In this section, we perform experiments and case studies to provide insight for managers. Specifically, DRT is benchmarked against the algorithm currently used in practice to quantify the room for improvement. Insight into the trade-off between throughput and giveaway is obtained through additional experimentation. Lastly, sensitivity of the revenue with respect to different production settings in terms of flock, order, and revenue values are studied.
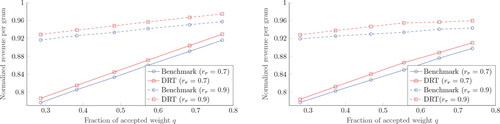
First, the performance of DRT is benchmarked in a practical setting. Our industrial partner provided us with simulation results of their state-of-the-art batcher. Algorithms currently used in practice are not capable of controlling the throughput, but solely control the fraction of items allocated. Hence, to get a fair comparison, the achieved throughputs from the benchmark case are used as target throughput in DRT. Additionally, DRT is tested with the item weight distribution and target weights from our industrial partner. In particular, for a grader with K = 8 bins, 10,000 items are generated using a distribution, varying the target throughput and using target weights B = 300 and 350, respectively.
DRT outperforms the benchmark in all settings. As shown in , for the case B = 300, up to 0.015 more revenue per gram can be achieved. Also shown in is that for the case B = 350, the increase in revenue per gram ranges from approximately 0.01 to 0.02. To illustrate the impact of such a reduction, consider the following setting. A plant processes 15,000 broilers per hour for 16 hours per day. The plant is operational for 300 days per year, the average broiler weight processed is 1500 grams and the total fillet weight per broiler is 25% or 375 grams (Peeters et al., Citation2017), all broilers are processed into fillets, and the value of fillets is 4 Euro per kilogram. In such a case, an increase of 0.01 in the normalized revenue per gram represents a revenue increase of 1,080,000 Euro in fillets alone. This translates to yearly cost savings of between 750,000 and 2,270,000 Euro when using DRT over the benchmark. Moreover, implementation costs of DRT are relatively low, since only modifications in the allocation software are required.
Figure 10. Revenue per gram for the benchmark and DRT for B = 300 and 350.
Second, we study the relation between algorithm performance and the target weight. shows the giveaway of IPP without target throughput at different target weights after 10,000 bins are filled. The performance of IPP is used as baseline to generate target throughputs for the DRT algorithm, each of which are mentioned in the legend. Specifically, the target throughput of DRT is set to 75% and 50% of IPP throughput at each target weight, and the target weight is varied from 200 to 500 in steps of 10.
Figure 11. Giveaway per gram for different target weights.
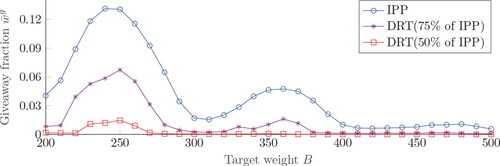
shows that, for all algorithms, the giveaway is relatively low for target weights that are a multiple of the mean item weight, and relatively high for target weights that are in between these values (illustrating the easy and hard cases). Furthermore, the overall level of giveaway decreases at higher target weights: more combinations of items can be made in larger bins, providing algorithms more flexibility to reduce giveaway. When the target throughput is lowered to 75% of the baseline, a significant giveaway reduction can be observed. DRT achieves close-to-zero giveaway around target weights that are a multiple of the mean product weight, as well as at target weights of 400 grams or higher. An additional giveaway reduction is achieved when only 50% of the baseline throughput is required, achieving negligible giveaway at all target weights except around B = 250. shows the corresponding revenue for and 0.9.
Figure 12. Revenue per gram for different target throughputs.

illustrates the revenue for different target throughputs. There is a strong relationship between revenue and normalized revenue of rejected weight. For the baseline algorithm generates a higher revenue for all target weights. All algorithms obtain a relatively high revenue for target weights yielding low giveaway. When the value of rejected weight is increased to
a completely different picture is observed. Lower target throughputs (and thus more rejected weight) yield a higher revenue in cases where IPP yields high giveaway. Poultry plants have reported target weights towards the lower end of the studied setting. The potential gain in revenue for different throughput targets at these lower target weights strongly depends on rr. For the case
a different production setting can yield up to 0.15 additional revenue per gram. For the case
this number changes to 0.06 per gram.
For plant managers, it is interesting to consider the above results in their production strategy. If their production setting changes, it is important to understand the ramifications in terms of revenue. Below, a number of different options and their impact on the revenue are discussed:
Suppose a customer demands batches with higher target weights B, which also corresponds to a higher throughput q. indicates that this change yields higher revenue if rr is low, but shows that this potential gain strongly depends on how much B changes in case rr is high.
Suppose the target throughput q is increased, because a customer demands more batches. The revenue increases if rr is low (see ), or if both rr and the target weight B are high, as can be seen in the right part of .
Suppose the target throughput is decreased, because a customer demands fewer batches. The revenue only increases if both rr and giveaway are high, as indicated by and (b).
To conclude, DRT equipped with IPP converges to the target throughput in all cases presented, and yields low giveaway by tuning the scale parameter C. This indicates that DRT is capable of managing the throughput–giveaway trade-off well. Second, numerical experiments for small-scale problems show that the structure of the optimal policy is complicated and that DRT achieves near-optimal performance and significantly outperforms IPPT(q). Third, we have seen that DRT outperforms the algorithm currently used in practice in a wide range of realistic problem settings for the industry. Lastly, the revenue per gram of processed weight appears to be sensitive to the relative value of weight processed as bulk batches, target throughput, and target weight.
6. Conclusions and future work
This article studies a problem relevant to the poultry processing industry. Retail customers order batches with a given target weight for which they pay a fixed price, and impose a target throughput on poultry processing plants. Additional weight in these batches is not paid for by retailers, and thereby results in giveaway. Weight that is not used in making retail batches is rejected to a batching process that creates bulk batches, which are worth less per weight compared with retail batches. Operating under this target throughput, the goal of poultry processing plants is to maximize the revenue by minimizing the giveaway.
This problem is formulated as an MDP. In a special case of the problem with single bin and no throughput constraint, we derived structural results for states where item allocation immediately results in a filled bin. In particular, we identified that optimal policies have a switching-curve structure under certain conditions. Since the MDP model is computationally intractable for industry-sized problems, we introduced a new heuristic algorithm called DRT, using a dynamically updated rejection threshold.
The performance of DRT was investigated in a numerical study. For small-scale problems, DRT appeared to perform close to optimal. In addition, a case study was performed, where DRT was benchmarked against simulation results provided by our industrial partner. Numerical experiments showed a significant improvement under all studied settings. In particular, for a realistic setting obtained from our industry partner, numerical experiments anticipated a revenue increase of up to 2% (which translates to millions per year) through the use of DRT.
Using insights from the numerical analysis, managers will be able to identify their current production setting and make informed decisions about future changes. Specifically, when customers request changes in the production setting in terms of target weight, target throughput, or relative value of bulk compared with retail batches, managers will be able to identify and quantify the expected outcome. As a future work, it will be interesting to investigate whether DRT can be adapted to other optimization problems where rejection is an option, such as bin-packing or knapsack problems. As another direction for future research, machine learning models could be trained to predict the item weight distribution on a rolling horizon.
Supplemental_Online_Materials.pdf
Download PDF (303.9 KB)Acknowledgments
The authors thank the Department Editor and two anonymous referees for their constructive comments that helped significantly improve this article.
Additional information
Notes on contributors
Kay Peeters
Kay Peeters is a PhD student of the dynamics and control research group at the Eindhoven University of Technology. He holds an MSc degree in mechanical engineering from the same university. His PhD project is centered around the optimization of poultry processing plants, with a focus on control, planning, and design. His research interests include discrete-event simulation of manufacturing networks, production control and production scheduling.
Ivo J. B. F. Adan
Ivo J. B. F. Adan is a professor at the Department of Industrial Engineering of the Eindhoven University of Technology. His current research interests are in the modeling and design of manufacturing systems, warehousing systems and transportation systems, and more specifically, in the analysis of multi-dimensional Markov processes and queueing models.
Tugce Martagan
Tugce Martagan is an assistant professor and Marie S. Curie Research Fellow in the Department of Industrial Engineering at Eindhoven University of Technology. She received her PhD in industrial engineering from the University of Wisconsin-Madison. Her research interests include stochastic modeling and optimization of manufacturing systems.
Notes
1 When we relax our assumptions on special cases to capture other problem configurations, numerical experiments indicate that optimal policies are complex and do not exhibit a structural behavior.
2 These values are chosen based on production data obtained from our industry partners, and represent common industry practices.
References
- Ásgeirsson, A. (2014) On-line algorithms for bin-covering problems with known item distributions. Ph.D. thesis, Georgia Institute of Technology, Atlanta, GA.
- Asgeirsson, E. and Stein, C. (2006) Using Markov chains to design algorithms for bounded-space on-line bin cover, in Proceedings of the Meeting on Algorithm Engineering & Expermiments, Springer, New York, NY, pp. 75–85.
- Asgeirsson, E. and Stein, C. (2009) Bounded space online bin cover. Journal of Scheduling, 12(5), 461–474.
- Coffman Jr, E.G., Johnson, D.S., Shor, P.W. and Weber, R.R. (1993) Markov chains, computer proofs, and average-case analysis of best fit bin packing, in Proceedings of the Twenty-Fifth Annual ACM Symposium on Theory of Computing, Association for Computing Machinery, New York, NY, pp. 412–421.
- Correa, J.R. and Epstein, L. (2008) Bin packing with controllable item sizes. Information and Computation, 206(8), 1003–1016.
- Csirik, J., Johnson, D.S. and Kenyon, C. (2001) Better approximation algorithms for bin covering, in Proceedings of the Twelfth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, USA, pp. 557–566.
- Derman, C. (1970) Finite State Markovian Decision Processes, Academic Press, Inc., Orlando, FL.
- Dósa, G. and He, Y. (2006) Bin packing problems with rejection penalties and their dual problems. Information and Computation, 204(5), 795–815.
- Manning, L. and Baines, R. (2004) Globalisation: A study of the poultry-meat supply chain. British Food Journal, 106(10/11), 819–836.
- Neuts, M. (1995) Matrix-Geometric Solutions in Stochastic Models: An Algorithmic Approach, Dover Publications, New York.
- OECD (2017, November) Meat consumption. Available at
- Peeters, K., Adan, I. and Martagan, T. (2019) Throughput control and giveaway minimization of a poultry product batcher, in 2019 Winter Simulation Conference, IEEE Press, Piscataway, NJ, pp. 2131–2141.
- Peeters, K., Martagan, T., Adan, I. and Cruysen, P. (2017) Control and design of the fillet batching process in a poultry processing plant, in 2017 Winter Simulation Conference, IEEE Press, Piscataway, NJ, pp. 3816–3827.
- Puterman, M.L. (2014) Markov Decision Processes: Discrete Stochastic Dynamic Programming, John Wiley & Sons, Hoboken, NJ.