
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In recent years, Bangladesh has seen significant development in the digitalization of various healthcare services. Although many mobile applications and social platforms have been developed to automate the services of the healthcare sector, there is still scope to make the process smooth and easily accessible for general people. This paper describes a system where the users can give their health-related problems or symptoms in the native Bengali language, and the system would recommend the medical specialist the user should visit based on their stated symptoms. The data is processed using various Natural Language Processing techniques. In this study, we have applied both Machine Learning and Deep Learning-based approaches. Three different models of Machine learning and four models of deep learning have been applied, analyzed and the accuracy of various models is evaluated to determine the best one that could provide superior performance on the given dataset. From the pool of traditional machine learning algorithms, the Random Forest (RF) classifier gives the highest accuracy of about 94.60% and Convolutional Neural Network performs the best among the deep-learning models, with an accuracy of 94.17%.
1. Introduction
A good healthcare system plays an important role in the development of a country. With the growing technological advancement of the world, Bangladesh has been moving towards digitalization over the past few years. Recently there are many mobile applications and social platforms have been developed to automate different healthcare services. However, there are still scopes where the services can be digitalized to make the process smooth and easily accessible to the general people. For instance, the medical or government hospitals of Bangladesh, especially Dhaka city, are always busy with patients visiting from different areas of the country for various treatments. There are cases where the patient is not certain about the medical specialist or doctors to whom they should consult and approach to. Specialized treatment is out of reach for millions of individuals. Ineffective specialist visits caused by a lack of pre-referral workup compound the situation, resulting in delays in care and prognosis (Ip et al., Citation2022). Most of the time, the patients first visit the receptionist, and with many patients visiting, it becomes a time-consuming and hectic process, even before they can visit the doctor. The application of Data Analytics has gained tremendous traction across a multitude of sectors. A portion of such improvement is specifically correlated to the use of Text Analytics solutions and the institutes are increasingly looking to Text Analytics to systematize the methods for extracting information from textual data (Elbattah et al., Citation2021). During the last five years, NLP research has resulted in new techniques and technology, which have subsequently resonated in the healthcare field. A patient in Hospital who requires a specialist consultation must first be recommended by a general practitioner before being placed on a waiting list (Kai et al., Citation2014). Typically, a health practitioner checks each referral, written in normal language, to see if it correlates to a specific condition. A mistake in this categorization is disastrous for patients since it places them on a non-prioritized waiting list with excessive wait periods (Villena et al., Citation2021). In medicine, terms like the history of current sickness are used to help clinic workers to comprehend what specialist they should consult (Corcoran et al., Citation2019) and this task can be completed using NLP techniques (Demner-Fushman et al., Citation2021).
The paper proposes an automatic system where the patient can give their primary symptoms or health-related problems in the native Bengali language, and the system would recommend the medical specialist that would be suitable for the mentioned symptoms. This would give the user a general idea of the doctor to visit and reduce the time taken to determine and take doctor’s appointments. Text mining and NLP can be used to automate the manual system in hospitals, saving human resources and time (Todd et al., Citation2018). NLP is cost-effective, and it has been demonstrated to be the right approach for obtaining structured information (Roy et al., Citation2021).
There have been previous works based on a chatbot for disease classification or healthy lifestyle based on machine learning (Rahman et al., Citation2019). However, no specific work has been done on this idea of classifying medical specialists based on general symptoms given in the Bengali language. To the best of our knowledge, this is the such first initiative to recommend doctors based on the symptoms presented in Bangla Language.
For this study, our main objective is to apply NLP to the user input and then apply both traditional Machine Learning (ML) models and deep-learning models to predict the class labels for the symptoms given by the user in the native language. Finally, the accuracy of various models is evaluated to determine the model that provides the best performance on the dataset. The main contributions of our research are:
Prepare a combined dataset consisting of more than seven thousand records from a local Bengali dataset and a translated dataset from English to Bengali.
Classify the medical specialist based on the general symptoms of the patients recorded in the combined dataset.
Analyze the accuracy and model complexity of several ML and deep-learning algorithms on both local and combined datasets and find the best model with respect to different performance metrics.
The rest of the paper is organized as follows. Section 2 discusses the literature reviews, Section 3 describes the dataset and the applied methods that have been used for this study. Section 4 consists of a detailed discussion of the results analysis in our study and finally, the conclusion and possible future work is presented in section 5.
2. Literature review
In Bengali healthcare, there has been a healthcare chatbot based on disease description in Bengali NLP and they have presented the system using ML methods (Rahman et al., Citation2019). This Bengali healthcare system is named ‘Disha’. They have been translated their data from English to Bengali and then preprocessed the data. After the preprocessing step, the authors used cosine similarity and TF–IDF for vectorization. In their work, six supervised ML algorithms have been experimented and SVM gives the highest accuracy with 98.39%, whereas multinomial Naïve Bayes provides the worst performance accuracy, 95.73%, which is around 3% lower than the best classifier.
Biswas and Das (Citation2019) proposed a neural network approach with hyperparameter tuning and word vectorization in order to predict the disease from the user-given symptoms in both Bengali text and audio format. Though they have collected 59 diseases, consisting of symptoms over 1500 written in the English language from various medical websites, but their testing data was collected manually. Since they translated their data using Google Translate API, they had to stem the data for verb and noun inflection using both independent and combined inflections and finally, they found 6680 stemmed words in total and 1441 unique stemmed words. Later they revised and processed the data manually and validated them by crowdsourcing. They have used three variations of activation functions such as Sigmoid, Tanh and ReLU. Tanh gave better accuracy in their case. In the case of the CNN model, they have used single-channel architecture, and max-overtime polling operation to extract features using convolution filters of 3, 4 and 5 with a dropout rate of 0.25 and batch size 50. Using 20 test cases, they found 68.32%, 74.56%, 81.88% of text accuracy and 57.45%, 62.36% and 63.77% of speech accuracy and 14, 16, 17 diseases were detected for the ANN-non-stemmed, ANN-stemmed and CNN model, respectively.
There has been another work done on a multilingual healthcare chatbot, which is based on Hindi, Gujarati. The system takes English text and speech data (Badlani et al., Citation2021). They have collected 41 disease classes and around 5000 records written in the English language. Faris et al. (Faris et al., Citation2020) worked on medical and healthcare data, which is a medical question classification. The authors applied binary particle swarms and an ensemble of support vector machines. By using those question classifications, an automatic answering system was created. The system took questions or queries from the patients and classified them into medical specialty which is based on the Arabic language. In their work, 15,000 medical records are used as data from a telemedicine company called ‘Altibbi’ asked by the users of that platform and all of the data have been classified into 15 specialty classes. The Arabic dataset has been preprocessed using tokenization, stemming and normalization before the extraction of features. TF–IDF method has been applied to extract the features from the preprocessed text and converted it into the matrix format. The proposed classification system is basically on the one-versus-rest (OVR) SVM method. Initially, on the particle encoding, the length of TF–IDF is 19 and the number of the possible feature includes 102994 in the dataset. The next part of this process determines the document frequency parameter. During the experiment, the last step in the OVR method, SVM represents the C parameter value which is 8, and the dimension of the vector used to encode the features. They have accomplished the study also integrating the Particle Swarm Optimization (PSO) and reached 85% accuracy. Faris et al. (Citation2022) worked on the classification of the Arabic healthcare systems based on LSTM and Bi-LSTM. Their experiment is based on the Arabic NLP dataset with around 1.5 million data. The authors applied the prediction-based model Word2Vec for the word embedding layer. The minimum input length value is 502 and the word vector dimension is set to 300 during the experiment. They have analyzed the performance of the LSTM and Bi-LSTM models using accuracy, recall and precision and f1-score evaluation metric. They have fixed the loss function ‘categorical_crossentropy’ and ‘Adam’ optimizer in both of the models. Another specialist classification work done by Maria et al. (Habib et al., Citation2021) which can classify the health-related telemedicine data from the Arabic language and the authors applied LSTM, Conv1D and a combination of LSTM and Conv1D. The authors reported the highest performance values using Conv1D in their study.
Most of the works are based on English language data where Usama et al. (Citation2020) have worked on healthcare data collected from a hospital in Wuhan, China, to predict different diseases using a self-attention based recurrent convolutional neural network. Their initial dataset contains 706 patients’ clinical notes and divided the patients into two categories for the experiment. The authors proposed a model which initially included an input layer. In their study, they used a convolutional kernel size: 100, embedding size: 50, learning rate: 0.10, epoch size: 30 was fixed and the filter size is set to 5 for further work after experimenting with various values of size. Seven-fold cross-validation has been applied for analyzing the evaluation results. After conducting the experiment and analyzing various models such as CNN, the RF-based prediction model, their proposed model achieved 95.71% accuracy and 91.43% recall which was notably improved than the traditional methods. In another health sector data collected from triage notes, Arnaud et al. (Arnaud et al., Citation2021) tried to predict the specialty using NLP techniques on hospital admission and also incorporated the CNN model for the prediction.
Kanimozhi et al. (Citation2022) recently studied big data in the healthcare sector and tried to predict the specialists using their proposed model, which performs better than the classical Naïve Bayes and Decision tree algorithms. In another study, outpatient specialty recommendations are useful among clinics using traditional ML algorithms, which reduces the waiting time of patients (Li et al., Citation2021).
The healthcare domain is exploring the NLP and ML techniques day by day for the classification of a specific disease or emergency issue (Tohira et al., Citation2021). Some other works also introduced using deep-learning models, especially in English languages. Lee et al. (Citation2021) built a deep learning-based NLP pipeline and developed an AI chatbot that could be utilized on a smartphone in order to produce a contactless way of proposing the right medical specialty. The authors applied the lightweight LSTM method for recommending specialists. Another recent work is done by Sadman et al. (Citation2021), which is based on the English language and focuses on a medical specialty from the transcription of patients. This research compared the conventional ML algorithms with the BiLSTM model, where logistic regression gives the best result in their scenario. For medical symptoms classification, another study is reported by Do and Vu (Citation2022) where GRU, LSTM and the bidirectional form of both models are compared on English data. In this study, stacked LSTM provides better performance compared to the stacked GRU model. In the paper (Chaitrashree et al., Citation2021), unstructured medical text data is found from text and voice descriptions and classified based on ML and DL approaches. The comparison between different feature extraction methods is shown using ML and DL methods by Weng et al. (Citation2017), which classified the subdomain of the healthcare domain from clinical notes. Another work on automatic triage referral (Wee et al., Citation2022) is conducted based on a customized NN model which is compared with the traditional ML algorithms. Some other healthcare-related tasks are accomplished by using NLP and ensemble ML techniques for classification (Sadman et al., Citation2020). A recent study was completed on patients’ speech texts based on basic symptoms (Aftab et al., Citation2021) classification on ML algorithms where naïve conversation texts are processed for the study and provide promising 99.4% accuracy on their dataset.
Along with traditional ML and DL algorithms, the combination of both algorithms is applied to different literature for improving performance. In some recent works, the CNN-LSTM model is studied for different text classification applications such as medical text classification (Zeghdaoui et al., Citation2021), text in both English and Roman Urdu, which is shared on social media (Khan et al., Citation2022), restaurant reviews (Hossain et al., Citation2020), Bengali text categorization method (Alam et al., Citation2022).
3. Materials and methods
3.1. Data collection
The primary dataset that is used in this study is obtained from Mendeley (Mridha et al., Citation2021). The dataset, Bengali Colloquial Dataset of Primary Medical Issues for Improving Health System, is based on the data collected with reference to Bangladesh. It can be used for the medical specialist classification. It consists of 704 records and 9 unique class labels.Each record has a problem statement in the Bengali language, describing the symptoms of the patients and its corresponding class label, which is the suggestion of the specialist that they should consult.
Since this dataset is limited and recently published data, in order to extend the dataset and validate the data, a secondary dataset has been combined with this dataset to increase the scope of our work. The second dataset Medical Speech, Transcription and Intent retrieved from Kaggle (Mooney and Medical Speech, Transcription, and Intent, Citationn.d.) consist of similar data but the problem statements are given in English. Before combining this with the initial dataset, the data has been translated into Bengali language using Google API. Further data preprocessing were also carried out, which will be discussed in the following section.
The final combined dataset consists of 7041 records with nine classes of unique specialists’ names, which have been used to train the different classification models. Class label wise patient distribution is given in .
shows the total number of the dataset we have used for the training and test in our experiment. We have stratified the data samples and selected 20% of the total data for the test.
Table 1. Number of data in Dataset-1 and Dataset-2 (train and test split).
3.2. Data preprocessing
Since the second dataset has been translated from English to Bengali by using Google API in python, data cleaning and filtering had to be done before combining the two datasets. Few Bengali terms needed to be replaced to match the familiar words used in the original Bangla dataset (Mridha et al., Citation2021). Records with similar class labels have been selected, and also redundant data were discarded.
shows the sample data from our combined dataset. The first column gives the problem statement in the Bengali language, and the second column represents the corresponding class label.
Table 2. Sample records from the Dataset.
Before using the data in the classification models, the raw data needs to be transformed into an understandable format. This is known as the data preprocessing and data cleaning techniques under NLP. Removing bad characters, punctuations, stop word removal, stemming and tokenization has been implemented on the raw data as a part of the preprocessing step.
In the beginning, the punctuation, white space, digits and other unnecessary characters have been removed using the BNLP tool (Sarker, Citation2021). Then tokenization has been applied, which is one of the primary tasks in NLP. In this process, the texts are broken down into smaller units referred to as tokens. Tokenization helps to analyse each word as an independent unit.
Stop word removal is the procedure where the essential words are extracted by removing the irrelevant words where we used the Bengali stopwords list (Diaz, Citation2016). There are many Bengali words that fall under the category of stop words.
The next step of preprocessing the data is stemming. It is a process in NLP that helps generate the root word by removing the prefixes and suffixes of the word (Mahmud et al., Citation2014). We applied the Bengali rule-based stemmer for our experiment.
Here is an example of a record after data preprocessing steps:
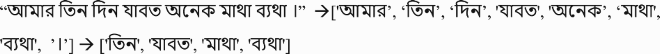
3.3. Feature extraction
After the preprocessing of data, the text needs to be encoded into a matrix or vector of features to be used for modelling. This is known as feature extraction in NLP.
ML algorithms cannot process raw text data directly; hence, one of the well-known feature extraction techniques called CountVectorizer has been applied to the preprocessed data before fitting into the ML models. For the deep learning approach, another popular method, Word2Vec, has been used for feature extraction.
3.3.1. Count vector
The features have been created basically using the frequency of every word in the text. The count vector is represented by the N × M matrix, where N denotes the number of records and M denotes each unique feature.
For our combined dataset, N = 7041 and M = 1619. We have used The CountVectorizer function that transforms a given text into a vector-based on the count of each feature that occurs in the entire text. In this study, CountVectorizer has been implemented by a popular python pre-trained module known as BnVec. It is an open-source library for the Bangla word extraction system.
Here we have given one example from our work of the count vector matrix for 3 × 14. Initially, we take three sentences here, which are preprocessed; after that, the matrix has been created using the frequency of words.

is the vector representation of the listed three sentences. Each vector contains 14 elements and those elements are the frequency of each word in the text.
Table 3. Vector representation of the sentences.
3.3.2. Word2vec embedding
Word2Vec is a widely used NLP model for word embedding, where the input is the text corpus, and the output is the set of vectors represented by numerical values (Mikolov et al., Citation2013). There are two types of word2vec, such as CBOW and Skip-gram model.
The Continuous Bag of Words (CBOW) model has been used in our experiment. This CBOW model takes tokenized texts as input. This input will pass through a hidden layer and from the hidden layer output layer is produced. The output layer produces the probability value according to the similarity of any word. The main idea is to take the target words as input and gives the output with probability values according to the similarity. Genism is an open-source python library that has been used in our study to implement the Word2Vec word embedding.
In our experiment, we have used window = 5, which represents the number of context words, vector size = 100 represents the dimensionality of the embedding vector and we get vocabulary size 1619. Input layer XV, where V = 1, 2, … 1619, hidden layer hN, where N = 100.
3.4. Traditional machine learning algorithms
3.4.1. Random forest (RF) classifier
RF is a supervised ML algorithm that can solve both classification and regression problems. It is based on the ensemble of decision trees and the implementation of the bagging method to generate the required prediction of the class label. The training data is fitted into the RF Classification model, and the performance of both dataset has been evaluated. RF has many advantages, which makes it a good algorithm for classification problems. A good prediction result can be obtained using the default hyperparameters. It also reduces the risk of overfitting the model, as an RF classifier is built on multiple decision trees, and the output is based on the majority voting or averaging.
3.4.2. Support vector classifier (SVC)
One of the supervised learning algorithms in ML that can be used in classification problems is known as a support vector machine. SVM is an approach in ML that can aid in classifying large amounts of data. The SVM classifier separates data points using a hyperplane in multi-dimensional space to separate different classes. Its main target is to find the maximum marginal hyperplane between the support vectors that divide the dataset into classes in the best possible way. In our study, we have used a linear kernel and the regularization parameter (C) as 1.0. Then we fit the training data into the SVM model and analysed its performance.
3.4.3. Logistic regression classifier
Logistic regression is another ML algorithm that can be used for binary or multi-class classification. It is widely used as it is easy to implement. In our paper, logistic regression has been applied like the other two ML models to evaluate the performance.
3.5. Deep learning-based models/neural network based models
3.5.1. Long short term memory (LSTM)
LSTM is a recurrent neural network that contains a hidden layer as the memory unit. The LSTM architecture is based on the memory unit and also it contains forget gate to prioritize the memory cell state (Hochreiter & Schmidhuber, Citation1997). We have used spatial dropout and dropout layers to avoid overfitting issues. We have used a dropout value 0.2.
3.5.2. Gated recurrent unit (GRU)
Gated recurrent unit (GRU) is similar to LSTM but contains a low number of parameters than the LSTM. This model was proposed by Chung et al. to make each recurrent unit adaptively learn dependencies. GRU contains another unit which is called hashtagging to learn the information in the unit (Chung et al., Citation2014). But GRU has no memory cells like LSTM. We used the unit value 36 and the dropout value 0.20 when we train our model.
3.5.3. Convolutional neural network (CNN)
CNN provides effective results in terms of classifying short sentences (Kim, Citation2014). Convolutional neural networks (CNN) employ layers that apply convolving filters on local features. By changing the size of the parts and concatenating their outputs, CNNs are great at extricating nearby and position-invariant highlights through RNNs are way better when classification is determined by a prolonged semantic reliance instead of a few local key-phrases. When we utilize CNN as a text classifier, it processes text as a grouping is passed to a CNN and .
Figure 1. Class labels of the combined dataset.
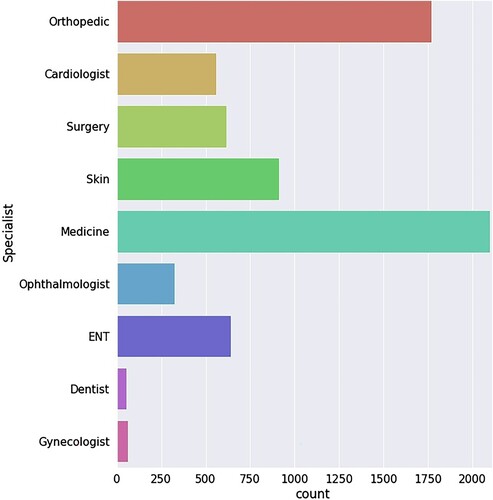
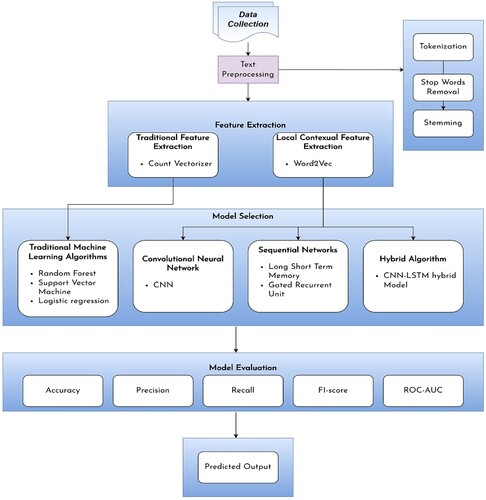
Figure 2. Basic abstract of the methodology.
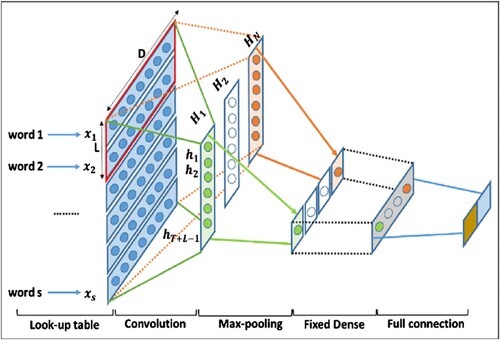
We have used a one-dimensional Convolutional layer where the kernel size is 3 and the filter size is 128. The word embedding matrix is passed to the embedding layer and three different channel sizes are connected to each layer. We have also applied the GlobalMaxPooling1D layer and set the dropout value to 0.5. Here in the convolutional layer, ‘ReLu’ has been used as the activation function. shows convolutional neural network architecture.
Figure 3. Convolutional neural network architecture.
3.5.4. CNN–LSTM
Zhou et al. (Citation2015) have proposed a combined architecture of both CNN and LSTM, which is called CNN-LSTM. In this architecture, the CNN layer helps to extract the sequences from the input word vectors and the output of this layer is fed forward to the next LSTM layer input. CNN–LSTM is able to extract both phrase-level local characteristics as well as global and temporal sentence semantics. In our experiment, we have applied one convolutional layer with 32 filters, where kernel size is three and activation function is ‘ReLu’. The output of this CNN layer is passed through a max-pooling layer and finally fed into an LSTM layer. The LSTM layer output passes through the dense layer.
We set the ‘categorical_crossentropy’ as the loss function, ‘adam’ optimizer, batch_size 8, epochs 30 and learning rate 0.001 for all the DL models we applied in our study. ModelCheckpoint is also added as a callback of the models which saves the best model from the model training period. Workflow of our system is represented in .
3.6. Evaluation measures
We have used accuracy, precision, recall and F1-score to analyze our models.
True Positive (TP): If the model can classify the specialist correctly or the number of exactly classified instances, that number will be called a true positive.
True Negative (TN): The number of negative instances correctly classified by the applied model.
False Positive (FP): If the model misclassifies negative instances based on the symptoms, that will be called a false positive.
False Negative (FN): The number of misclassified positive instances is called a false negative.
Accuracy: Overall percentage of the correctly classified classes is defined by the accuracy metric.
Precision: Precision is referred to as the ratio of genuine positives to all positive outcomes.
Recall: Recall indicates the percentage of false occurrences that are accurately recognized.
F1-score: Harmonic mean of the precision and recall metric of outdoor patient classification.
The equations of the evaluation metrics have been listed below:
(1)
(1)
(2)
(2)
(3)
(3)
(4)
(4)
3.7. Confusion matrix
The confusion matrix indicated the True positive (TP), True Negative (TN), False Positive (FP) and False Negative (FN) values.
4. Results and analysis
In our first step after preprocessing, we applied a countvectorizer to extract the features from the medical corpus. From the first dataset (Dataset-1), we have extracted 706 features and after combining the datasets, the number of features is 1619.
4.1. Performance of traditional machine learning classifiers
4.1.1. Performance analysis of Dataset-1
When we have applied ML classifiers in our dataset 1, from we can see that the RF classifier gives the best accuracy 78.01%, whereas the SVM classifier shows 77.3%. Logistic regression performs worst amongst all of the ML classifiers we have applied in terms of accuracy, which is 75.89% and around 2.21% lower than the RF classifier and 1.41% lower than the SVM classifier.
Table 4. Test performance result (Dataset 1).
We have also analysed Precision, recall and F1-Score performance matrices. The highest precision score, recall and F1-score of the RF classifier (Dataset 1) are 79%, 78% and 77%, respectively. But when we applied logistic regression precision score, recall and F1-score is lower than RF results which are 77%, 76% and 76.5%, respectively.
4.1.2. Performance analysis of Dataset-2
In our combined dataset (Dataset-2), the accuracy is around 97.66% in the RF classifier, which is the highest amongst all the ML classifiers we have applied, and 97.59% in both logistic regression and SVM have been observed from . In our work, LR and SVM provide almost similar accuracy in both cases.
Table 5. Test performance result (Dataset 2).
The other performance metrics, such as precision score, recall and F1-score are 98% in both RF and LR classifiers. In the case of SVM, the recall value is similar to the RF and LR, but the precision and f1-score are slightly lower, which is 97% for the augmented dataset.
4.2. Performance analysis of deep learning/neural network based models
4.2.1. Performance analysis (Dataset-1)
From , we have found that CNN-LSTM and CNN provide the highest training accuracy 99.29%, and GRU gives the lowest training accuracy, 97.51% for our small dataset. In this case, LSTM shows 97.69% training accuracy, which is around 1.6% lower than CNN and CNN-LSTM. When we observed the test accuracy in dataset 1 after 30 epochs, it is quite clear that CNN provides the best test accuracy result, which is 82.27% in terms of accuracy. GRU model results are poor compared to other experimented models and 5.67% lower than the CNN and around 4% less than LSTM.
Table 6. Deep-learning model performance after 30 epochs (Dataset 1).
In this case, LSTM performs better than the CNN-LSTM and GRU models. LSTM gives the second highest test accuracy result on the pure Bengali dataset which is 80.14% and around 2.13% less than the CNN model.
(f) shows the train and test accuracy for 30 epochs. The test accuracy fluctuates slightly over the epochs, but the training accuracy is stable after 20 epochs. In (e), we see the loss graph of the train and test of the CNN model. Training loss for CNN is near zero value after 20 epochs, but the testing loss increases over the epochs.
Figure 4. Training and testing loss values (first column) and accuracy values (second coloumn) using different deep-learning models using Dataset 1 during 30 epochs.
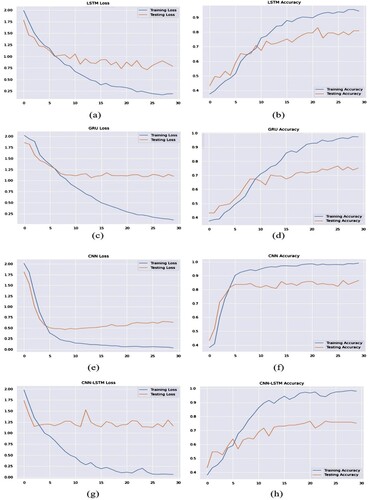
In (b), we can see that the training accuracy of LSTM is stable after 20 epochs and test accuracy increases throughout 20 epochs, and after that, testing accuracy is slightly fluctuating between 75% and 79%. Training loss is stable after 25 epochs, shown in (a), in this case, test loss is lowest around 18 epochs after that, loss fluctuates over the epochs.
The testing accuracy and loss are not stable throughout the experiment with dataset-1 in CNN-LSTM as given in the last row of . The testing accuracy varies from 70% to 80% throughout the period. When we observed the loss, it is highly fluctuating over the test period and provides high loss value than the other DL models we have tested.
4.2.2. Performance analysis of Dataset-2
In the next step, we conducted our experiment on the combined dataset to validate our deep-learning models. indicates all the results of deep-learning models after 30 epochs. CNN and CNN-LSTM model both provides the same training accuracy of 99.73%, whereas LSTM shows around 99.68% accuracy, which is slightly lower than the CNN and CNN–LSTM models.
We have also remarked that CNN shows the highest test accuracy 97.73%, on the augmented dataset whereas LSTM, GRU and CNN–LSTM provide 96.88%, 96.45% and 96.84%, respectively. So, the GRU model has performed poorly in this case. represents the accuracy.
From (third row), CNN’s training accuracy and the testing accuracy are stable after completing 10 epochs, but test loss is increasing over the epochs perhaps it becomes lower compared to our first experiment with dataset 1. The loss value has been reported as around 0.75 after completing the 30 epochs.
Figure 5. Training and testing loss values (first column) and accuracy values (second coloumn) using different deep-learning models using Dataset 2 during 30 epochs.
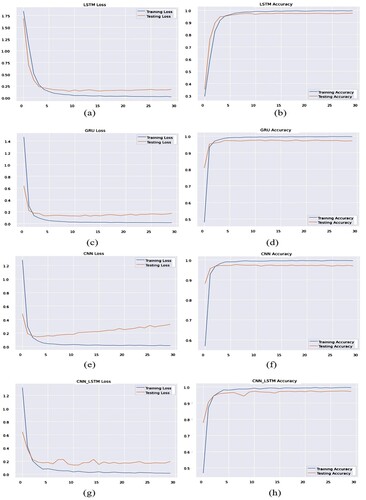
(a) and (b) shows the training and testing loss and accuracy graph for the combined dataset when we have executed the LSTM model. The testing loss is around 0.2 over the epochs and it has been noticeably reduced compared to our first experiment. The training loss indicates around 0 value and training accuracy is over 99%.
The results of CNN-LSTM arealso improved in the combined dataset. The test accuracy is oscillating before 20 epochs and after that, the values are stable throughout the period. The test loss value is around 0.2–0.4 over the epochs and the values are changing over the period. The loss values arehigher from the LSTM and GRU model we have experimented with before in this section but lower than the CNN model loss value, which is increasing ().
Table 7. Deep-learning model performance with 30 epochs (Dataset 2).
4.3. Model prediction
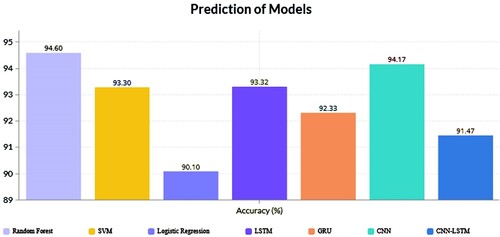
When we have predicted the accuracy of dataset 1 after training all the models with dataset 2, the prediction accuracy is highest in RF. We can clearly see that model performance () improves when we have combined our dataset. Because when we worked with only dataset 1, RF accuracy was around 78.01% and after incorporating the dataset’s accuracy is 94.60%. CNN model provides 94.17% accuracy on prediction, which is the highest in DL models.
Table 8. Comparison of model predictions on Dataset 1.
The ML classifier SVM accuracy is slightly lower which is 93.31%, from other DL models we have applied such as LSTM and GRU. LSTM and GRU give quite similar results in the prediction here. In our experiment, Logistic regression and CNN-LSTM prediction results are lowest than the other models, which are 90.10% and 91.47%, respectively.
shows the overall precision, recall, f1-score and roc-auc values of DL models. CNN gives the highest values of the classification metrics among all of the models. LSTM performs well compared to GRU and CNN-LSTM in all cases. CNN-LSTM provides the lowest recall, f1 score and roc-auc values in this experiment but the precision score is similar to the LSTM model. But the GRU model gives the lowest precision values among all the DL models we have applied.
Table 9. Overall classification report of the deep-learning models.
represents the graphical representations of predictions we get for all of our applied approaches. This graph clearly shows that RF gives the highest prediction when we enlarge our dataset. If we consider DL models, then accuracy is slightly lower for the combined dataset in the case of CNN. Logistic regression shows the lowest prediction values among all of the models we have applied. From the experiments, we have found that when the dataset is small in that case, CNN works better compared to the ML classifiers. But when we have expanded our dataset, ML classifier RF works much better than other models and if we only consider DL-based models, then CNN provides improved results in performance.
Figure 6. Graphical representation of prediction of models.
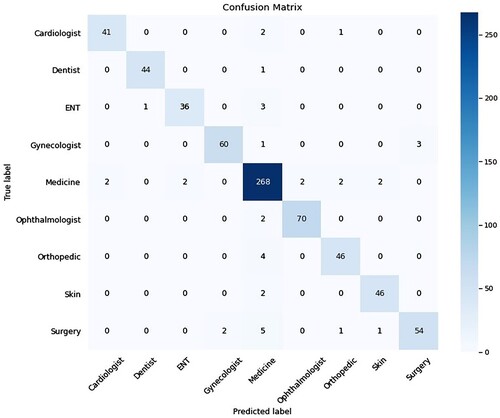
shows the confusion matrix when we predict the first dataset using the RF classifier. We have also manually tested the user-given data using RF classifier and in that case, our RF model predicts the specialist class, which is similar to the actual class label. The following shows a few examples of actual classes and predicted classes using an RF classifier. The problem statements were also manually tested using CNN, which also gave the correct classifications.
Figure 7. Confusion matrix on RF model prediction.
Although our models predicted most of the problem statements accurately and gave the correct class labels for the specialists, we also analysed a few examples where our model could not give accurate results due to a few constraints of our dataset (). represents a snanshot of our system where it does correct classification.
Table 10. Prediction table for specialist with correct classification.
, given above, shows two such scenarios. The first row of the table shows the problem statement where the RF model fails, but the sequence CNN-based model succeeded. It shows that the problem statement is mispredicted by RF. However, when we try to predict the same problem statement with CNN or other DL models, it predicts perfectly as the actual class. RF has predicted that problem as an Ophthalmologist because of the word ‘চোখ’. RF has only focused on this word due to the high frequency of this word under Ophthalmologists in our dataset. But when we have applied the sequential models, word2vec word embedding helps find similar words and predicts the actual label medicine. RF provides higher accuracy in our experiments because our problem statements are not so large, and also the features are also limited because of the small dataset. If the problem statements are large and features are sparse, then sequential models will perform much better in classification.
Table 11. Prediction table for specialist with incorrect classification.
For the second scenario, both our ML and sequential-based models predicted incorrect class labels. According to our models, the class label is predicted as Medicine, whereas the actual class label should be Gynecologist. The problem statement given is a sequence of sentences, and one of the keywords here is ‘ ’. However, in our dataset, the word for period or menstruation is referred to mostly as ‘
’. However, in our dataset, the word for period or menstruation is referred to mostly as ‘ ’. The word ‘
’. The word ‘ ’ is not similar to the model, and as our dataset has the highest class labels for the class ‘Medicine’ specialist, the model overfits the data. This can also be a possible reason for the misclassification. This problem arises in Bengali NLP, especially with the colloquial language. Bengali is a diverse language and contains a wide range of words with similar meanings. Sometimes a Bengali term that we use for regular speaking is not the formal term used in the case of writing. Finally, we have replaced the word ‘
’ is not similar to the model, and as our dataset has the highest class labels for the class ‘Medicine’ specialist, the model overfits the data. This can also be a possible reason for the misclassification. This problem arises in Bengali NLP, especially with the colloquial language. Bengali is a diverse language and contains a wide range of words with similar meanings. Sometimes a Bengali term that we use for regular speaking is not the formal term used in the case of writing. Finally, we have replaced the word ‘ ’ to ‘
’ to ‘ ’ which could predict the classes perfectly in the applied example on the table. Therefore, it is not easy to cover the wide range of Bengali words. Moreover, our dataset consists of a combination of colloquial Bengali languages and translated statements, which could have those limitations.
’ which could predict the classes perfectly in the applied example on the table. Therefore, it is not easy to cover the wide range of Bengali words. Moreover, our dataset consists of a combination of colloquial Bengali languages and translated statements, which could have those limitations.
5. Conclusions
The healthcare system is an indispensable component of any community. We have demonstrated a Bengali NLP-based system where the user will provide the basic or primary symptoms of the disease and our system would suggest which specialist patients should consult with. We have experimented with both ML and DL methods. In our work, when we used a small dataset in the Bengali language, CNN performed best with 82.27% accuracy, compared to the ML classifiers. When we augment our dataset with another one, the dataset is enlarged and prediction accuracy is highest in the RF classifier with 94.60% accuracy, and the second highest is provided by CNN, which is 94.17%. Finally, we have manually tested our system with RF classifier because RF gives the highest accuracy and our system predicts the specialist that matches the actual class label. Our work has a few limitations with the specialist class. If we can expand our dataset in the native colloquial Bengali language and increase the number of classes for medical specialists, it will help to improve the accuracy of our system with more disease-specific specialist prediction.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Jannatul Ferdous Ruma
Jannatul Ferdous Ruma pursued Master's and Bachelor's degree in Computer Science and Engineering from North South University, Dhaka, Bangladesh. She is currently working as a lecturer at The International University of Scholars and is also involved as a Research Assistant at North South University under the supervision of Dr. Rashedur M. Rahman. She also worked as a Graduate Teaching Assistant at the same institution. She has published research articles in journals like Results in Engineering, Cybernetics and Systems, and Decision Analytics Journal. Her current research interests include NLP, Machine Learning and Deep Learning.
Fayezah Anjum
Fayezah Anjum completed her Master's and Bachelor's degree in Computer Science and Engineering from North South University, Dhaka, Bangladesh. Currently serving as a faculty member at Scholastica, she wants to pursue a higher degree and work in academia. Her main research interests include Machine Learning and Deep Learning. She is also working on research based on Intrusion Detection System. She has her research papers published in conference proceedings by Industrial, Engineering and Other Applications of Applied Intelligent Systems (IEA/AIE), Computer Science On-line Conference(CSOC) by Springer, and IEEE Computing and Communication Workshop and Conference (CCWC).
Rokeya Siddiqua
Rokeya Siddiqua received her Bachelor of Science (B.Sc) degree in Computer Science and Engineering from North South University, Dhaka, Bangladesh, in 2022. In 2020, she joined the Department of Electrical and Computer Engineering at North South University as an Undergrad Teaching Assistant. The following year, she became a Lab Instructor in the same department and university. Her research interests revolve around the application of Machine Learning and Deep Learning technologies for assessing depression among Bangladeshi students.
Md. Abidur Rahman
Md. Abidur Rahman is a Computer Science and Engineering graduate from North South University. With in-depth knowledge of ML frameworks, libraries, data modeling, and this thesis on 'Stock Market Prices Analysis and Prediction using Machine Learning,' he is pursuing to become a machine learning scientist. He is currently working in a Cybersecurity firm in Bangladesh but has a strong interest in artificial intelligence and wants to become a successful analyst and researcher who can use machine learning and algorithms to address issues facing real-world businesses.
Abir Hossain Rohan
Abir Hossain Rohan is a Computer Science and Engineering graduate specializing in AI with a focus on machine learning. He has over two years of experience in data science, currently working as a research assistant at North South University. He has done a thesis on 'Stock Market Prices Analysis and Prediction Using Machine Learning' and is passionate about exploring new technologies and applying their skills to real-world problems.
Rashedur M. Rahman
Rashedur M. Rahman received an M.S. degree from the University of Manitoba, Winnipeg, Canada, in 2003 and a Ph.D. from the University of Calgary, Canada, in 2007. He is an Electrical and Computer Engineering Department Professor at North South University, Dhaka, Bangladesh. He has published more than 150 research papers in the area of parallel and distributed computing, cloud and grid computing, and data and knowledge engineering. His current research interests include cloud load characterization, VM consolidation, and the application of machine learning in different decision-making problems. He is also on the editorial committees of many international journals.
References
- Aftab, H., Gautam, V., Hawkins, R., Alexander, R., & Habli, I. (2021, November 13–14). Robust intent classification using Bayesian LSTM for clinical conversational agents (CAs). International Conference on Wireless Mobile Communication and Healthcare, pp. 106–118.
- Alam, S., Haque, M. A. U., & Rahman, A. (2022, February 26–27 ). Bengali text categorization based on deep hybrid CNN–LSTM network with word embedding. 2022 International Conference on Innovations in Science Engineering and Technology, pp. 577–582. https://doi.org/10.1109/ICISET54810.2022.9775913
- Arnaud, É, Elbattah, M., Gignon, M., & Dequen, G. (2021, August 09–12). NLP-based prediction of medical specialties at hospital admission using triage notes. 2021 IEEE 9th International Conference on Healthcare Informatics, pp. 548–553. https://doi.org/10.1109/ICHI52183.2021.00103
- Badlani, S., Aditya, T., Dave, M., & Chaudhari, S. (2021). Multilingual healthcare chatbot using machine learning. https://doi.org/10.1109/INCET51464.2021.9456304.
- Biswas, E., & Das, A. K. (2019, June 28–30). Symptom-based disease detection system In bengali using convolution neural network. 2019 7th International Conference on Smart computing and Communications, pp. 1–5. https://doi.org/10.1109/ICSCC.2019.8843664
- Chaitrashree, K. M., Sneha, T. N., Tanushree, S. R., Usha, G. R., & Pramod, T. C. (2021, August 27–28). Unstructured medical text classification using machine learning and deep learning approaches. 2021 International Conference on Recent trends electronics and Information, communication Technology, pp. 429–433. https://doi.org/10.1109/RTEICT52294.2021.9573667
- Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014, December 8–11). Empirical evaluation of gated recurrent neural networks on sequence modeling. NIPS 2014 Workshop in Deep learning..
- Corcoran, C. M., Benavides, C., & Cecchi, G. (2019). Natural language processing: Opportunities and challenges for patients, providers, and hospital systems. Psychiatric Annals, 49(5), 202–208. https://doi.org/10.3928/00485713-20190411-01
- Demner-Fushman, D., Elhadad, N., & Friedman, C. (2021). Natural language processing for health-related texts. In E. H. Shortliff & J. J. Cimino (Eds.), Biomed. Informatics (pp. 241–272). Springer. https://doi.org/10.1007/978-3-030-58721-5_8
- Diaz, G., Stopwords ISO · GitHub (2016). Retrieved October 9, 2021 https://github.com/stopwords-iso/
- Do, C., & Vu, L. (2022). Application of deep-learning for medical text analysis: A comparison of different types of recurrent neural network. Journal of Data Science and Artificial Intelligence, 1(1). https://www.isods.org/publications/index.php/jdsai/article/view/7
- Elbattah, M., Arnaud, E., Gignon, M., & Dequen, G. (2021). The role of text analytics in healthcare: A review of recent developments and applications. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2021) (Vol. 5, pp. 825–832). SCITEPRESS – Science and Technology Publications. https://doi.org/10.5220/0010414508250832
- Faris, H., Habib, M., Faris, M., Alomari, A., Castillo, P. A., & Alomari, M. (2022). Classification of arabic healthcare questions based on word embeddings learned from massive consultations: A deep learning approach. Journal of Ambient Intelligence and Humanized Computing, 13, 1811–1827. https://doi.org/10.1007/s12652-021-02948-w
- Faris, H., Habib, M., Faris, M., Alomari, M., & Alomari, A. (2020). Medical speciality classification system based on binary particle swarms and ensemble of one vs. rest support vector machines. Journal of Biomedical Informatics, 109, 103525. https://doi.org/10.1016/j.jbi.2020.103525
- Habib, M., Faris, M., Qaddoura, R., Alomari, A., & Faris, H. (2021). A predictive text system for medical recommendations in telemedicine: A deep learning approach in the arabic context. IEEE Access, 9, 85690–85708. https://doi.org/10.1109/ACCESS.2021.3087593
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Hossain, N., Bhuiyan, M. R., Tumpa, Z. N., & Hossain, S. A. (2020, July 1–3). Sentiment analysis of restaurant reviews using combined CNN-LSTM. 2020 11th International Conference on Computing, Communication and Network Technologies, pp. 1–5. https://doi.org/10.1109/ICCCNT49239.2020.9225328
- Ip, W., Prahalad, P., Palma, J., & Chen, J. H. (2022). A data-driven algorithm to recommend initial clinical workup for outpatient specialty referral: Algorithm development and validation using electronic health record data and expert surveys. JMIR Medical Informatics, 10(3), e30104. https://doi.org/10.2196/30104
- Kai, E., Ahmed, A., Inoue, S., Taniguchi, A., Nohara, Y., Nakashima, N., & Kitsuregawa, M. (2014, September 13–17). Evolving health consultancy by predictive caravan health sensing in developing countries. Proceedings on the 2014 ACM International Joint Conference on Pervasive Ubiquitous Computing Adjunt Publications, Association for Computing Machinery, New York, NY, USA, pp. 1225–1232. https://doi.org/10.1145/2638728.2638816
- Kanimozhi, K. V., Jeyavathana, R. B., & Hameed, C. S. (2022). Prediction of disease and suggestion of specialist using big data techniques. AIP Conference Proceedings, 2393, 20027. https://doi.org/10.1063/5.0074128
- Khan, L., Amjad, A., Afaq, K. M., & Chang, H.-T. (2022). Deep sentiment analysis using CNN-LSTM architecture of English and roman urdu text shared in social media. Applied Sciences, 12(5), 2694. https://doi.org/10.3390/app12052694
- Kim, Y. (2014, October 25–29). Convolutional neural networks for sentence classification. Proceedings of the 2014 Conference on Empirical Methods Natural Language Processing, Association for Computational Linguistics, Doha, Qatar, pp. 1746–1751. https://doi.org/10.3115/v1/D14-1181
- Lee, H., Kang, J., & Yeo, J. (2021). Medical specialty recommendations by an artificial intelligence chatbot on a smartphone: Development and deployment. Journal of Medical Internet Research, 23(5), e27460. https://doi.org/10.2196/27460
- Li, Q.-C., Ling, X.-Q., Chiang, H.-S., & Yang, K.-J. (2021). A medical specialty outpatient clinics recommendation system based on text mining. International Journal of Grid and Utility Computing, 12(4), 450–456. https://doi.org/10.1504/IJGUC.2021.119568
- Mahmud, M. R., Afrin, M., Razzaque, M. A., Miller, E., & Iwashige, J. (2014, September 24–27). A rule based bengali stemmer, In: Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics, ICACCI 2014, Institute of Electrical and Electronics Engineers Inc., pp. 2750–2756. https://doi.org/10.1109/ICACCI.2014.6968484
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. https://doi.org/10.48550/ARXIV.1301.3781.
- Mooney, P., & Medical Speech, Transcription, and Intent (n.d.). Retrieved October 9, 2021 from https://www.kaggle.com/datasets/paultimothymooney/medical-speech-transcription-and-intent
- Mridha, D. M. F., Islam, T., & Mahbin Zinat, S. (2021). Bengali colloquial dataset of primary medical issues for improving health system, Mendeley data. V3. https://doi.org/10.17632/4TT953XWK2.3 [dataset].
- Rahman, M. M., Amin, R., Khan Liton, M. N., & Hossain, N. (2019, December 18–20). Disha: An implementation of machine learning based bangla healthcare chatbot. 2019 22nd International Conference on Computer and Information Technology, pp. 1–6. https://doi.org/10.1109/ICCIT48885.2019.9038579
- Roy, K., Debdas, S., Kundu, S., Chouhan, S., Mohanty, S., & Biswas, B. (2021). Application of natural language processing in healthcare. Computational Intelligence and Healthcare Informatics, 393–407. https://doi.org/10.1002/9781119818717.ch21
- Sadman, N., Rahman, H., Tasneem, S., Haque, M., & Gupta, K. D. (2021). Recommend speciality doctor from health transcription: Ensemble machine learning approach. https://doi.org/10.1109/CCWC51732.2021.9376111.
- Sadman, N., Tasneem, S., Haque, A., Islam, M. M., Ahsan, M. M., & Gupta, K. D. (2020, November 4–7). Can NLP techniques be utilized as a reliable tool for medical science? Building a NLP framework to classify medical reports. 2020 11th IEEE Annual Information Technology Electronics and Mobile Communication Conference, pp. 159–166. https://doi.org/10.1109/IEMCON51383.2020.9284834
- Sarker, S. (2021). BNLP: Natural language processing toolkit for Bengali language, ArXiv Prepr. ArXiv2102.00405.
- Todd, J., Richards, B., Vanstone, B., & Gepp, A. (2018). Text mining and automation for processing of patient referrals. Applied Clinical Informatics, 9(01|1), 232–237. https://doi.org/10.1055/s-0038-1639482
- Tohira, H., Finn, J., Ball, S., Brink, D., & Buzzacott, P. (2021). Machine learning and natural language processing to identify falls in electronic patient care records from ambulance attendances. Informatics for Health and Social Care, 47(4), 1–11. https://doi.org/10.1080/17538157.2021.2019038
- Usama, M., Ahmad, B., Xiao, W., Hossain, M. S., & Muhammad, G. (2020). Self-attention based recurrent convolutional neural network for disease prediction using healthcare data. Computer Methods and Programs in Biomedicine, 190, 105191. https://doi.org/10.1016/j.cmpb.2019.105191
- Villena, F., Pérez, J., Lagos, R., & Dunstan, J. (2021). Supporting the classification of patients in public hospitals in Chile by designing, deploying and validating a system based on natural language processing. BMC Medical Informatics and Decision Making, 21(1), 208. https://doi.org/10.1186/s12911-021-01565-z
- Wee, C. K., Zhou, X., Gururajan, R., Tao, X., Chen, J., Gururajan, R., Wee, N., & Barua, P. D. (2022). Automated triaging medical referral for otorhinolaryngology using data mining and machine learning techniques. IEEE Access., 10, 44531–44548. https://doi.org/10.1109/ACCESS.2022.3168980
- Weng, W.-H., Wagholikar, K. B., McCray, A. T., Szolovits, P., & Chueh, H. C. (2017). Medical subdomain classification of clinical notes using a machine learning-based natural language processing approach. BMC Medical Informatics and Decision Making, 17(1), 155. https://doi.org/10.1186/s12911-017-0556-8
- Zeghdaoui, M. W., Boussaid, O., Bentayeb, F., & Joly, F. (2021). Medical-based text classification using FastText features and CNN-LSTM model. In C. Strauss, G. Kotsis, A. M. Tjoa, & I. Khalil (Eds.), Database expert syst. Appl. (pp. 155–167). Springer International.
- Zhou, C., Sun, C., Liu, Z., & Lau, F. C. M. (2015). A C-LSTM neural network for text classification. https://doi.org/10.48550/ARXIV.1511.08630.