
ABSTRACT
The empirical likelihood method is a powerful tool for incorporating moment conditions in statistical inference. We propose a novel application of the empirical likelihood for handling item non-response in survey sampling. The proposed method takes the form of fractional imputation but it does not require parametric model assumptions. Instead, only the first moment condition based on a regression model is assumed and the empirical likelihood method is applied to the observed residuals to get the fractional weights. The resulting semiparametric fractional imputation provides -consistent estimates for various parameters. Variance estimation is implemented using a jackknife method. Two limited simulation studies are presented to compare several imputation estimators.
1. Introduction
Missing data are frequently encountered in many areas, such as survey sampling, epidemiology and other fields. Simply ignoring missing values can potentially lead to biased estimation (Kim & Shao, Citation2013; Little & Rubin, Citation2002). Two statistical approaches for handling missing data have been used in practice: propensity score weighting and imputation. Propensity score weighting is used mainly to correct for unit non-response, while imputation is mainly used to handle item non-response. Haziza (Citation2009) provides a comprehensive overview of the imputation methods in survey sampling.
Multiple imputation (MI), proposed by Rubin (Citation1987), is a popular approach of imputation for general-purpose estimation due to its practical simplicity. However, the Rubin's variance estimator may be biased under certain situation (Fay, Citation1992; Kim, Brick, Fuller, & Kalton, Citation2006; Wang & Robins, Citation1998; Yang & Kim, Citation2016) and its validity requires the congeniality condition of Meng (Citation1994), which may not hold for general-purpose estimation.
Fractional imputation (FI), first proposed by Kalton and Kish (Citation1984), provides an alternative method for handling item non-response. Fay (Citation1996), Kim and Fuller (Citation2004), Fuller and Kim (Citation2005), and Durrant and Skinner (Citation2006) discussed fractional hot deck imputation. Kim (Citation2011) and Kim and Yang (Citation2014) discussed a fully parametric approach to FI. The parametric fractional imputation (PFI) provides a powerful tool for handling missing data for various situations. However, it relies on a strong parametric model assumption and making such an assumption is not usually preferred in survey sampling. Balanced random imputation of Chauvet, Deville, and Haziza (Citation2011) is also an attractive imputation technique, but it still requires parametric model assumptions for multipurpose estimation.
The empirical likelihood (EL) method, considered by Owen (Citation2001) and Qin and Lawless (Citation1994), is a useful tool for semiparametric inference in statistics. It involves a likelihood-based inference without making a parametric distributional assumption about the observed data. Qin (Citation1993) addressed the missing survey data problem by using a biased sampling argument of Vardi (Citation1985). Wang and Rao (Citation2002) brought regression-type imputation approaches to EL inference. Wang and Chen (Citation2009) used a nonparametric regression imputation approach to handle missing data in the EL inference. Müller (Citation2009) considered a novel application of EL method to handle missing data under a regression model assumption. In Müller (Citation2009), the moment condition of the error term in the regression model is used to construct a fully imputed estimator.
In this paper, motivated by the fully imputed estimator of Müller (Citation2009), we propose a semiparametric fractional imputation (SFI) method using EL that can be used to handle item non-response in survey sampling. Because the proposed SFI uses only moment conditions in the semiparametric regression model, it is more robust than the PFI method or parametric MI method. By using regression model assumptions, the proposed SFI method is more efficient than the nonparametric regression imputation method of Wang and Chen (Citation2009). The proposed method takes the form of FI, so the actual implementation is very attractive in practice. The proposed SFI method can be used to estimate various parameters, including non-smooth parameters such as population quantiles.
The paper is organised as follows. The basic set-up is introduced and the proposed method is presented in Section 2. The asymptotic properties of the SFI estimators are presented in Section 3. Extensions to non-smooth statistics as well as random imputations are covered in Section 4. In Section 5, variance estimation is discussed. Some numerical results are given in Section 6. Some concluding remarks are made in Section 7.
2. Basic set-up
Consider a finite population where xi is the vector of auxiliary variables that are always observed and yi is the study variable that is subject to missingness. We assume (xi, yi) are realisations from a regression model
(1) where
is assumed to be known with unknown parameter
and ε satisfies E(ε|X) = 0. No parametric distributional assumption on X is made.
Let δi be the response indicator such that δi = 1 if yi is observed and δi = 0 otherwise. We assume missing at random (MAR) in the sense that
(2) Even though we observe δi only in the sample, we can conceptually assume that δi's are defined throughout the population. Such extended definition of δi has been adopted in Fay (Citation1992), Shao and Steel (Citation1999), and Kim, Navarro, and Fuller (Citation2006).
Given the finite population, suppose that sample A of size n is selected from the finite population by a probability sampling mechanism. Let πi, i = 1, 2, … , N, be the first-order inclusion probability of unit i in the population. We are interested in estimating η0, defined as a solution to the estimating equation E{U(η; x, y)} = 0 where U(η; x, y) is a known function with parameter η. To avoid unnecessary details, we assume that the solution to E{U(η; x, y)} = 0 is unique and the dimensions of η and U(η; x, y) are r. Thus, the parameter η is just-identified. Under complete response, a consistent estimator of η0 is obtained by solving
for η. If some of yi are missing, under the MAR assumption, a consistent estimator of η0 can be obtained by solving the following expected estimating equation:
(3) for η. The conditional expectation in Equation (Equation3
(3) ) is with respect to f(y∣x), which is unknown as we only assume Equation (Equation1
(1) ).
In FI, our goal is to approximate the conditional expectation in Equation (Equation3(3) ) by the weighted mean of the fractionally imputed estimating functions. That is, we wish to achieve
(4) as closely as possible for some (w*ij, yi*(j)) satisfying ∑mj = 1wij* = 1, where w*ij's are desired fractional weights and y*(j)i's are m imputed values for subject i. Kim (Citation2011) and Kim and Yang (Citation2014) developed a FI satisfying Equation (Equation4
(4) ) using a parametric model assumption on f(y∣x).
In our proposed method, we use the EL approach to achieve the approximation in Equation (Equation4(4) ). To explain the idea, assume for now that the true parameter
in Equation (Equation1
(1) ) is known. In this case,
are available among δi = 1. Because E(ε∣x) = 0 holds, we can compute
where fε(ε∣x) is the (unknown) conditional density of ε given x. To apply the EL method, we assume that the conditional distribution of ε given x can be approximated by
(5) such that wi ≥ 0 with ∑δiwi = 1, where wi is the point mass assigned to the observed εi by assuming that the support of εi is equal to the set of observed εi. Using the approximation in Equation (Equation5
(5) ), we can obtain
which can be written in the FI form in Equation (Equation4
(4) ). To determine wj uniquely, we can use the idea of pseudo EL method of Wu and Rao (Citation2006) to maximise
(6) subject to
(7) In practice, we do not know
, and hence, we do not observe
. We can use a
-consistent estimator of
to obtain
and apply the above EL method to the observed residuals. In general, one can use
(8) to obtain a
-consistent estimator of
where
is an arbitrary function that enables the above equation to have a solution. If the variance function
for a known function q, then one can choose
where
This choice is motivated by the quasi likelihood method for generalised linear models (McCullagh & Nelder, Citation1989, Ch. 9). The solution to Equation (Equation8
(8) ) can be called complete-case (CC) method. The CC estimator is not efficient in general, but it is efficient for estimating
under MAR. Thus, the resulting SFI estimator can be constructed as follows:
| Step 1 | Obtain a | ||||
| Step 2 | Find | ||||
| Step 3 | Use | ||||
| Step 4 | The SFI estimator | ||||
Instead of Equation (Equation11(11) ), one can also consider a fully imputed estimating equation based on
which was considered by Müller (Citation2009) under the independently and identically distributed set-up. The fully imputed estimating equation may lead to a more efficient estimator of η (Matloff, Citation1981) but such over-imputation does not appeal to survey practice since we usually do not want to replace the true values of respondents with some imputed values. In the following section, we present the asymptotic properties of
under complex survey designs.
3. Asymptotic properties
To discuss the asymptotic properties of the proposed SFI estimator of η, we first assume a sequence of finite populations and samples with finite fourth moments as in (Fuller, Citation2009, Ch.1). The following theorem presents the asymptotic normality of the proposed SFI estimator. The sketched proof of Theorem 3.1 is provided in Appendix 1.
Theorem 3.1:
Under the regularity conditions (C1)–(C13) in Appendix 1, the SFI estimator defined in Equation (Equation11(11) ) is a
-consistent estimator of η0, that is
where B = [E{∂U(η; x, y)/∂η}]− 1,Σu2 = V(N− 1∑i ∈ Aπ− 1iζi), and
(12) and
with σ2 = E(ε2),
and l(ε) = −∂log fε(ε∣x)/∂ε.
Remark 3.1:
In Equation (Equation12(12) ), ζi can be written as the sum of four terms. The first two terms is the conditional expectation of U(η; x, y), the third term is the additional term due to approximating f(y∣x) by the EL method and the fourth term is the additional term due to estimating
.
According to Theorem 3.1, a consistent variance estimator of can be written as
(13) where
with
and
(14) where
and
is a plug-in estimator of ζi in Equation (Equation12
(12) ). One can use
with
When nN−1 = o(1), the second term of Equation (Equation14
(14) ) is of smaller order and can be safely ignored.
4. Extensions
In this section, we discuss two extensions of the proposed method. In Section 4.1, our proposed method is extended to handle non-smooth statistics including distribution functions and percentiles. In Section 4.2, an extension to stochastic imputation is discussed.
4.1. Inference for non-smooth statistics
Suppose that we are interested in estimating parameter η0, the solution of E{U(η; x, y)} = 0 with non-smooth function U(η; x, y), where the non-smoothness can be with respect to either η or y. For generality, we assume that the non-smoothness is with respect to both η and y. Wang and Opsomer (Citation2011) discussed asymptotic results for non-differentiable survey estimators. Define
Let
and
where
Denote
as the solution of estimating equation
To discuss asymptotic properties, we replace regularity conditions (C7)–(C10) in Appendix 1 with the regularity conditions (C14)–(C17) in Appendix 2. The following theorem presents the asymptotic expansion of
under this scenario and the sketched proof is presented in Appendix 2.
Theorem 4.1:
Under regularity conditions (C1)–(C3) and (C11)–(C17) in Appendix 1 and Appendix 2, has the following asymptotic expansion:
where
where
and
evaluated at
and other terms are the same as those in Theorem 3.1.
By Theorem 4.1, we can obtain
where B = [E{∂U(η; x, y)/∂η}]− 1 and Σu2 = V{N− 1∑i ∈ Aπ− 1iζ2i}. If we are interested in estimating the cumulative density function of y, which is Pr(y < t), then we can choose U(η; x, y) = I(y < t) − η and
where
Therefore, we have
A consistent estimator of D* can be written as
with
where Kx and Ky are kernel functions for x and y with bandwidth hx and hy. Thus, a consistent variance estimator of
here can be obtained similarly to Equation (Equation13
(13) ).
If the parameter of interest is the τth percentile of Y, given by η = F− 1Y(τ), the SFI estimator of η can be obtained by solving the estimating Equation (Equation11
(11) ) with U(η; x, y) = I(y < η) − τ. Since E{I(Y < η)} = FY(η), it can be shown that
has the asymptotic expansion in Theorem 4.1 with
where fy is the density function for y. A consistent estimator of ∂E{U(η0; x, y)}/∂η can be written as
and a consistent estimator of D* can be written as
with
4.2. Stochastic imputation
In the multi-purpose surveys, stochastic imputation is often preferred to deterministic imputation since it can preserve distributional relationship better. In stochastic imputation, imputed values are generated from a stochastic imputation mechanism and with additional variability due to the imputation. For simplicity, we only consider the case where U(η; x, y*(j)i) is a smooth function of η and The results can be naturally extended to non-smooth statistics. The stochastic imputation estimator
can be obtained by solving the following estimating equation:
where y*(s)i are randomly selected from
with the selection probability
, where w*ij are the fractional weights in Equation (Equation11
(11) ). Since
where the conditional expectation is with respect to the stochastic imputation mechanism, we have
Thus, using an argument similar to Theorem 3.1, we can obtain
(15) where
. Therefore, a consistent variance estimator can be written as
where
(16) and
can be obtained similarly to Equation (Equation13
(13) ) and
The second term of Equation (Equation16
(16) ) estimates the additional variance due to stochastic imputation. If m is large, the second term is negligible.
5. Replication variance estimation
Estimating the variance of the estimator can be done through the linearisation formulas presented in Section 3 for smooth statistics and the formulas in Section 4 for non-smooth statistics. However, it requires tedious algebra to compute all the terms. In this section, we consider an alternative approach using replication methods. Shao and Tu (Citation1995) considered the theoretical aspects of replication methods such as Jackknife and Bootstrap. Wolter (Citation2007) gives a comprehensive overview of replication variance estimation methods in survey sampling.
Suppose we are interested in estimating T = ∑Ni = 1yi. Define the design weight as di = π− 1i. The design unbiased estimator of T is and the consistent replication variance estimator of
is given by
where L is the number of replicates, ck is the replication factor associated with the kth replication and
with d(k)i being the kth replicate of di. For example, ck = (L − 1)/L for deleting one group jackknife method. For details of corresponding ck with different variance estimation approaches, see Wolter (Citation2007).
To obtain replication variance estimator of our proposed SFI estimator, we apply the same SFI method to each of the replicates. In the first step, we obtain the kth replicate of by solving
In the second step, the replicated EL weights are computed by maximising
subject to constraints
with
. In the final step, the replicated SFI estimator is computed using the replicated EL weights. For smooth statistics, the kth replicate of
, denoted by
, is obtained by the solution to the following estimating equation
where
. The final replication variance estimator of
is given by
For non-smooth statistics, our estimator is similar to that of Wang and Opsomer (Citation2011). Define
where
and
are defined in Section 4.1,
is defined in Equation (Equation11
(11) ) with design weight replaced by replication weight d(k)i and fractional weights replaced by replication fractional weights w*(k)ij. Then the replication variance estimator can be written as
with
defined in Section 4.1.
6. Simulation studies
In this section, we conduct two limited simulation studies. The first one is generated from an artificial data-set and the second one is based on the real data treated as a finite population.
6.1. Simulation one
We repeatedly generate B = 2000 finite populations of (xi, yi, δi) of size N = 10, 000 from a super-population model
with xi ∼ exp (1) and E(εi∣xi) = 0. Two error distributions are considered: (E1) εi ∼ N(0, 1) and (E2) ε ∼ {χ2(2) − 2}/2. Given (x, y), the response indicator δ has a Bernoulli distribution with
The overall response rate is about 50%. Given each finite population (x, y, δ), we draw a sample by using a Poisson sampling design with the first-order inclusion probability πi = nzi/∑Ni = 1zi, where n = 200 and zi = max {0.5yi + 2, 1} + ui, with ui ∼ χ2(1) and χ2(1) corresponding to the chi-squared distribution with degrees of freedom equal to one. In this simulation, we are interested in estimating three parameters:
| (1) | θ1 = N− 1∑Ni = 1yi, the population mean of y. | ||||
| (2) | θ2 = N− 1∑Ni = 1I(yi < 1), the proportion of y less than 1. | ||||
| (3) | θ3 = F−1(0.5), the population median of y. | ||||
From each sample, we compute the following four estimators:
| (1) | The CC estimator based on the complete cases only. The CC estimator is the solution to ∑i ∈ Aδiπ− 1iU(η; xi, yi) = 0, where U(η; x, y) is the corresponding estimating equation for each parameter. | ||||
| (2) | Full sample estimator based on the original sampling without missing data andpseudo EL method (FULL). Specifically, we maximise l = ∑i ∈ Aπ− 1ilog (ωi), subject to the following constraints:
| ||||
| (3) | The PFI estimator of Kim (Citation2011) assuming yi∣xi ∼ N(β0 + β1xi, σ2) with imputation size M = 100. | ||||
| (4) | The nonparametric fractional imputation (NFI) estimator that uses the following nonparametric fractional weights:
| ||||
| (5) | The stochastic regression imputation (SRI) estimator assuming the following model: yi = β0 + β1xi + εi with E(εi) = 0 and V(εi) = σ2. | ||||
| (6) | The proposed SFI estimator | ||||
From the Monte Carlo sample of size B = 2000, Monte Carlo bias, standard error and root mean squared error (RMSE) are computed for each point estimator. The results are presented in . Under (E1) and (E2), the CC estimators perform worst since the response mechanism is not missing completely at random (MCAR). Unless the response mechanism is MCAR, the CC estimator is biased. The FULL estimators always perform best since they assume no missing values and use moment condition (Equation1(1) ). Under distribution (E1), the SFI and PFI estimators have similar performances. Among the three imputation estimators, the NFI and SFI estimators perform worst in terms of RMSE for all scenarios since they used less information.
Table 1. The Monte Carlo bias (× 10−2), standard error (SE) (× 10−2) and root mean squared error (RMSE) (× 10−2) for four different methods with two error distributions in Simulation one.
Under model (E2), the SFI estimator shows negligible bias for all parameters, but the PFI estimator has non-negligible bias for estimating proportion and quantile which is due to the misspecification of the error distribution. The NFI and SRI estimators are not as efficient as the SFI estimator in terms of bias and variance. The SFI estimator outperforms PFI, NFI and SRI estimators in terms of RMSE. The overall results indicate the robustness of SFI. For variance estimation, we computed the relative bias based on the Taylor linearisation and replication methods, respectively. All the relative bias are below 7%. In addition, we calculate the Monte Carlo coverage rate for the 95% confidence intervals. Under model (E1), the coverage rates are 94.8%, 93.4% and 95.0% for estimating mean, proportion and quantile, respectively, by using Taylor method, and 94.9%, 93.6% and 95.1% by using replication method. The results under model (E2) are similar and the coverage rates are close to the nominal rate.
6.2. Simulation two
In the second simulation study, we use 2013–2014 U.S. National Health Examination and Nutrition Survey (NHANES) data as a pseudo finite population. Suppose the study variable is systolic blood pressure (BPXSY1) and the covariate variable is body mass index (BMXBMI). Keeping only the cases where both BPXSY1 and BMXBMI are greater than zero, the pseudo finite population eventually contains 7104 cases. The scatter plot of BPXSY1 versus BMXBMI is presented in . We assume that BPXSY1 is roughly linear with respect to BMXBMI. After performing linear regression of BPXSY1 versus BMXBMI, the QQ plot of residuals and residuals vs. fitted values plot are presented in . The residual plots suggest deviation from normality. The p value from Anderson–Darling test for normality is less than 2.2 × 10−16. We first generate response indicators δi, i = 1, 2, .… , 7104 from the following logistic regression model:
The response rate is around 60%. Then given the population of (BPXSY1i, BMXBMIi, δi), B = 2000 Monte Carlo samples are generated by simple random sampling with sample size n = 200. Assume that the parameters of interest are
| (Mean). | Finite population mean of BPXSY1, which is θm = 118.056. Figure 1. Scatter plot of BPXSY1 vs. BMXBMI. 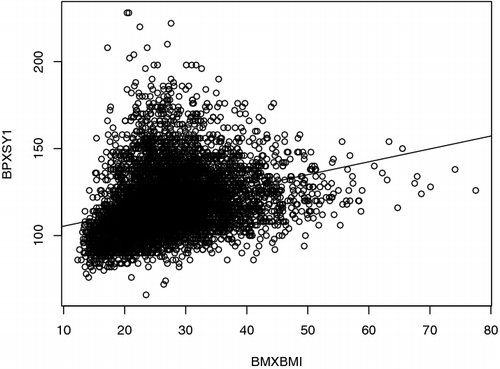 Figure 2. QQ stands for quantile quantile plot (left panel) and residual vs. fitted value plot (right panel). 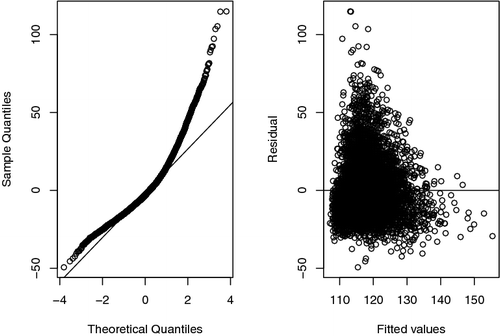 | ||||
| (Prop1). | Finite population proportion one of BPXSY1:
| ||||
| (Prop2). | Finite population proportion two of BPXSY1:
| ||||
| (Prop3). | Finite population proportion three of BPXSY1:
| ||||
We consider the same PFI, NFI, SRI and SFI estimators as discussed in Simulation one. The Monte Carlo bias, standard error and RMSE are presented in . For the population mean, PFI and SFI perform similarly and the NFI estimator has slightly larger bias and standard error. SRI has comparable bias as PFI and SFI, but it has larger SE, as expected. For population proportions, the PFI estimator has substantially larger bias than NFI, SRI and SFI which may be due to the misspecification of error distributions. The NFI and SRI estimators have larger standard errors than PFI and SFI estimators since the nonparametric methods are not as efficient as parametric or semiparametric methods and stochastic imputation will produce larger variance. Overall, SFI estimator performs the best in terms of both bias and variance.
Table 2. The Monte Carlo bias (× 10−2), standard error (SE) (× 10−2) and root mean squared error (RMSE) (× 10−2) for four different methods and four parameters.
7. Conclusions
Regression imputation is often used to handle item non-response in survey sampling. Unlike the usual regression imputation, the proposed SFI offers valid inference for a wide set of parameters such as population proportions and quantiles. Besides, only the first moment assumption is needed to obtain a consistent SFI estimator of the parameter, which leads to robust parameter estimation. The proposed SFI method shows good performances in the limited simulation studies.
The proposed method has several possible future research topics. First, instead of assuming ignorable response mechanism, we can consider an extension to non-ignorable non-response (Kim & Yu, Citation2011) using an exponential tilting response model. Also, extension of the SFI for handling multivariate missing data will be an important future research topic.
Acknowledgments
We thank an anonymous referee and the editor for very constructive comments. The first author wishes to acknowledge the partial funding provided by National Institutes of Health, National Institute of General Medical Sciences (Grant 1 U54GM104938), Oklahoma Shared Clinical and Translational Resources; Alterations and Renovations; Oversight and Management Core and IDeA-CTR to the University of Oklahoma Health Sciences Center. The research of the second author is partially supported by a grant from NSF in the US (MMS-1324922).
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Chauvet, G., Deville, J. C., & Haziza, D. (2011). On balanced random imputation in surveys. Biometrika, 98, 459–471.
- Chen, J., & Sitter, R. (1999). A pseudo empirical likelihood approach to the effective use of auxiliary information in complex surveys. Statistica Sinica, 9, 385–406.
- Durrant, G. B., & Skinner, C. (2006). Using missing data methods to correct for measurement error in a distribution function. Survey Methodology, 32(1), 25–36.
- Fay, R. E. (1992). When are inferences from multiple imputation valid? In Proceedings of the Survey Research Methods Section of the American Statistical Association (Vol. 81, pp. 227–232).
- Fay, R. E. (1996). Alternative paradigms for the analysis of imputed survey data. Journal of the American Statistical Association, 91(434), 490–498.
- Fuller, W. A. (2009). Sampling statistics. Hoboken, NJ: Wiley.
- Fuller, W. A., & Kim, J. K. (2005). Hot deck imputation for the response model. Survey Methodology, 31, 139–149.
- Haziza, D. (2009). Imputation and inference in the presence of missing data. In D. Pfeffermann & C. R. Rao (Eds.), Handbook of statistics. Sample surveys: Theory, methods and inference (Vol. 29, pp. 215–246). Amsterdam: Elsevier BV.
- Isaki, C. T. and Fuller, W. A. (1982). Survey design under the regression superpopulation model. Journal of the American Statistical Association, 77, 89–96.
- Kalton, G., & Kish, L. (1984). Some efficient random imputation methods. Communications in Statistics A, 13, 1919–1939.
- Kim, J. K. (2011). Parametric fractional imputation for missing data analysis. Biometrika, 98, 119–132.
- Kim, J. K., Brick, J., Fuller, W. A., & Kalton, G. (2006). On the bias of the multiple-imputation variance estimator in survey sampling. Journal of Royal Statistical Society: Series B, 68(3), 509–521.
- Kim, J. K., & Fuller, W. A. (2004). Fractional hot deck imputation. Biometrika, 91(3), 559–578.
- Kim, J. K., Navarro, A., & Fuller, W. A. (2006). Replicate variance estimation after multi-phase stratified sampling. Journal of the American Statistical Association, 101, 312–320.
- Kim, J. K., & Shao, J. (2013). Statistical methods for handling incomplete data. London: Chapman and Hall/CRC.
- Kim, J. K., & Yang, S. (2014). Fractional hot deck imputation for robust inference under item nonresponse in survey sampling. Survey Methodology, 40, 211–230.
- Kim, J. K., & Yu, C. L. (2011). A semi-parametric estimation of mean functionals with non-ignorable missing data. Journal of the American Statistical Association, 106, 157–165.
- Little, R. J. A., & Rubin, D. B. (2002). Statistical analysis with missing data (2nd ed.). Hoboken, NJ: Wiley.
- Matloff, N. S. (1981). Use of regression functions for improved estimation of means. Biometrika, 68, 685–689.
- McCullagh, P., & Nelder, J. (1989). Generalized linear models. London: Chapman and Hall.
- Meng, X. L. (1994). Multiple-imputation inferences with uncongenial sources of input. Statistical Science, 9, 538–558.
- Müller, U. U. (2009). Estimating linear functionals in nonlinear regression with response missing at random. Annals of Statistics, 98, 2245–2277.
- Owen, A. B. (2001). Empirical likelihood. New York, NY: Chapman and Hall/CRC.
- Qin, J. (1993). Empirical likelihood in biased sample problems. Annals of Statistics, 21(3), 1182–1196.
- Qin, J., & Lawless, J. (1994). Empirical likelihood and general estimating equations. The Annals of Statistics, 22, 300–325.
- Rubin, D. B. (1987). Multiple imputation for nonresponse in surveys. New York: John Wiley & Sons.
- Shao, J., & Steel, P. (1999). Variance estimation for survey data with composite imputation and nonnegligible sampling fractions. Journal of the American Statistical Association, 94, 254–265.
- Shao, J., & Tu, D. (1995). The jackknife and bootstrap. New York: Springer-Verlag.
- Vardi, Y. (1985). Empirical distributions in selection bias models. Annals of Statistics, 13, 178–203.
- Van der Vaart, A. W. (1998). Asymptotic statistics. New York: Cambridge University Press.
- Vís̆ek, J. A. (1979). Asymptotic distribution of simple estimate for rejective, Sampford and successive sampling. In J. Jurecková (Ed.), Contributions to statistics: Jaroslav hj́ek memorial volume (pp. 263–275). Dordrecht: Academia, Prague & D. Reidel.
- Wang, D., & Chen, S. X. (2009). Empirical likelihood for estimating equations with missing values. The Annals of Statistics, 37, 490–517.
- Wang, Q., & Rao, J. N. K. (2002). Empirical likelihood-based inference under imputation for missing response data. The Annals of Statistics, 30, 896–924.
- Wang, N., & Robins, J. M. (1998). Large-sample theory for parametric multiple imputation procedures. Biometrika, 85(4), 935–948.
- Wang, J. Q., & Opsomer, J. D. (2011). On asymptotic normality and variance estimation for nondifferentiable survey estimators. Biometrika, 98, 91–106.
- Wolter, K. M. (2007). Introduction to variance estimation. New York, NY: Wiley.
- Wu, C., & Rao, J. N. K. (2006). Pseudo empirical likelihood ratio confidence intervals for complex surveys. The Canadian Journal of Statistics, 34, 359–375.
- Yang, S., & Kim, J. K. (2016). A note on multiple imputation for general-purpose estimation. Biometrika, 103, 244–251.
Appendices
Appendix 1. Proof of Theorem 3.1
We first assume the following regularity conditions:
| (C1) | The finite population is a random sample from the semiparametric regression model in Equation (Equation1 | ||||
| (C2) | Function | ||||
| (C3) | The model error term in Equation (Equation1 | ||||
| (C4) | Let | ||||
| (C5) |
| ||||
| (C6) |
| ||||
| (C7) | Function U(η; x, y) has continuous partial derivatives ∂U(η; x, y)/∂η and ∂U(η; x, y)/∂y in the neighbourhood of the true value η0 and ||U(η; x, y)||2, ||∂U(η; x, y)/∂η|| and ||∂U(η; x, y)/∂y|| are bounded by some integrable function G2(x, y) in the neighbourhood. | ||||
| (C8) | Let | ||||
| (C9) |
| ||||
| (C10) |
| ||||
| (C11) | The first-order inclusion probabilities satisfy KL ≤ Nn−1πi ≤ KU for all i, where KL and KU are positive constants. | ||||
| (C12) | max i, j|πijπ− 1iπ− 1j − 1| = o(1) for any i, j = 1, 2, … , N and i ≠ j, where πij are the second-order inclusion probability of unit i and unit j in the population. | ||||
| (C13) | The response probability satisfies Equation (Equation2 | ||||
Conditions (C1)–(C2) are the model assumptions about the finite population. Condition (C3) is used to control the asymptotic order of in Equation (Equation10
(10) ). Chen and Sitter (Citation1999, Appendix 2) argued that (C3) holds for common unequal probability sampling designs. Conditions (C4) and (C8) ensure the consistency of
and
, respectively. Conditions (C5), (C6), (C9) and (C10) are the regularity conditions that ensure asymptotic normality of
and
. Van der Vaart (Citation1998, Ch. 5) used similar regularity conditions. Specifically, Conditions (C6) and (C10) have been used in many existing literature such as Wu and Rao (Citation2006), Wang and Opsomer (Citation2011), among others. Hajek (1960, 1964) established the asymptotic normality condition under simple random sampling and rejective sampling with unequal selection probabilities. Vís̆ek (Citation1979) established the asymptotic normality for the Horvitz–Thompson estimator under Rao-Sampford sampling designs. Condition (C7) controls the smoothness and asymptotic behaviour of estimating function U(η; x, y). Conditions (C11) and (C12) are the standard assumptions for the sampling designs. Similar conditions have been used in Isaki and Fuller (Citation1982) and Wang and Opsomer (Citation2011). Condition (C13) controls the behaviour of the individual response probability. According to assumption (C3) and by using similar techniques as Wu and Rao (Citation2006), we can show that
Assumption (C4) and Taylor linearisation can establish
Therefore,
(A1) We know that
is the solution of the following estimating equation:
In addition, we have
(A2) and
(A3) Based on Equations (EquationA2
(A2) ) and (EquationA3
(A3) ), by using Taylor linearisation, we have
(A4) According to Equations (EquationA1
(A1) )–(EquationA4
(A4) ) and after some algebra, it can be shown that
(A5) where σ2 is the variance for the residuals. With condition (C6), it can be shown that
In addition, we have
(A6)
(A7) and
(A8) where
and
with
Define
then by using Taylor linearisation,
with E(S) = E{(1 − δ)U(η0; x, y)} and
According to the Hoeffding decomposition,
Therefore,
(A9) According to Taylor linearisation, we have
(A10) By Equations (EquationA1
(A1) ), (EquationA5
(A5) )–(EquationA10
(A10) ), after some algebra, we can show that
where ζi is defined in Equation (Equation12
(12) ) of Theorem 3.1.
Appendix 2. Proof of Theorem 4.1
We replace regularity conditions (C7)–(C10) in Appendix 1 with the following regularity conditions:
| (C14) |
| ||||
| (C15) | There exists a measurable function L(δ, x, y) with E{L2(δ, x, y)} < ∞ and for every θ1 and θ2 in the neighbourhood of the true value θ0, | ||||
| (C16) | Assume that | ||||
| (C17) |
| ||||
Similar to Conditions (C4) and (C8), Condition (C14) ensures the consistency of proposed estimator. Conditions (C15) and (C16) are required to derive asymptotic expansion of proposed estimator. See Van der Vaart (Citation1998, Ch. 5) for more details of those conditions. Similar to Conditions (C6) and (C10), Condition (C17) is used to derive the central limit theory.
The proof of the consistency of and
is similar to the relevant proof in Theorem 3.1. According to the regularity conditions (C10)–(C12) and by using similar techniques as that of Theorem 19.26 of Van der Vaart (Citation1998), we can show that
(B1) In addition, we have
(B2) and
(B3) where D* is defined in Theorem 4.1. According to Equations (EquationA1
(A1) ), (EquationA5
(A5) ), (EquationA6
(A6) ), (EquationA9
(A9) ), (EquationB1
(B1) )–(EquationB3
(B3) ), we have
where ζi is defined in Theorem 4.1.