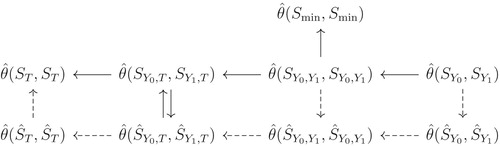?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Quantile treatment effects can be important causal estimands in evaluation of biomedical treatments or interventions for health outcomes such as medical cost and utilisation. We consider their estimation in observational studies with many possible covariates under the assumption that treatment and potential outcomes are independent conditional on all covariates. To obtain valid and efficient treatment effect estimators, we replace the set of all covariates by lower dimensional sets for estimation of the quantiles of potential outcomes. These lower dimensional sets are obtained using sufficient dimension reduction tools and are outcome specific. We justify our choice from efficiency point of view. We prove the asymptotic normality of our estimators and our theory is complemented by some simulation results and an application to data from the University of Wisconsin Health Accountable Care Organization.
1. Introduction
Causal evaluation of treatment or intervention is commonly done by estimating average treatment effect (ATE). However for health outcomes such as medical cost and utilisation, quantile treatment effect (QTE) may be more relevant and informative (Abadie, Angrist, & Imbens, Citation2002; Cattaneo, Citation2010; Chernozhukov & Hansen, Citation2005; Doksum, Citation1974; Firpo, Citation2007; Frölich & Melly, Citation2010, Citation2013; Lehman, Citation1975). As outcomes tend to be highly skewed to the right, ATE may not be a proper representative parameter for location. Furthermore, it is often important to learn about distributional impacts beyond ATE, such as the effects on upper (or lower) quantiles of an outcome, which may be of direct interests to policy makers and other stakeholders of a programme.
Our study of QTE is motivated by the following investigation at the University of Wisconsin (UW) Health System. As of January 1, 2013, the UW Health System became an Accountable Care Organization (ACO), which is a network of doctors, clinics and other health care providers that share financial and medical responsibility for providing coordinated care to patients in hopes of limiting unnecessary spending. One strategy pursued by nearly all ACOs is to manage the care to ‘high-need, high-cost’ patients: those with multiple or complex conditions, often combined with behavioural health problems or socioeconomic challenges. In particular, we are asked to evaluate a particular intervention used by the UW Health System. If the intervention can reduce the upper quantiles of health care utilisation quantified by medical cost, then the next step is to significantly enhance the nurse team so that intervention can be extended to a wider population. In essence, we need to estimate QTEs particularly at an upper level.
To define QTE, we begin with some notation. Let T be a binary treatment indicator, X be a p-dimensional vector of pretreatment covariates, and and
be the potential outcomes under treatments T = 0 and T = 1, respectively. Since only one treatment is applied, either
or
is observed, but not both, i.e. what we observe is
. With a fixed
, the
QTE is defined as
, where
is the τth quantile of
, k = 0, 1; e.g.
, 0.25, and 0.75 give the difference of medians, lower quartiles, and upper quartiles, respectively. We focus on the estimation of θ based on a random sample
of n observations from
.
Because we only observe Z, θ is often not identifiable without any condition. Throughout we assume the following assumption that is believed to be reasonable in many applications (Rosenbaum & Rubin, Citation1983): , i.e. T and the vector of potential outcomes
are independent conditional on X, which is similar to the ignorable missingness assumption when we treat T as a missingness indicator and unobserved
or
as a missing value. Under this assumption, two types of consistent estimators of QTE θ in causal inference or closely related context in missing data have been proposed in the literature. One type is derived through regression on
for k = 0, 1 (Cattaneo, Citation2010; Chen, Wan, & Zhou, Citation2015; Cheng & Chu, Citation1996; Zhou, Wan, & Wang, Citation2008), and the other type is based on inverse propensity weighting with propensity score
(Firpo, Citation2007). A review is given by Cattaneo, Drukker, and Holland (Citation2013). Since parametric methods rely on correct model specifications, nonparametric estimation of the regression functions or propensity is often preferred and therefore considered in what follows.
In our ACO data, however, the dimension p of X is high and nonparametric estimation of regression or propensity function using for example the kernel method is asymptotically inefficient when is related with only a lower dimensional function of X. Unnecessarily using a high dimensional X may also affect kernel estimation numerically. Our main task is studying covariate dimension reduction to facilitate stable and efficient estimation of QTE.
If inverse propensity weighting is applied, it seems that covariate dimension reduction is to find a linear function of X with the smallest dimension such that
. Unfortunately, Hahn (Citation1998) indicated that in the estimation of ATE, using such an
provides no improvement in estimation efficiency over using the entire X. Because the outcome
is involved in the estimation of ATE, Hahn (Citation2004) suggested finding a linear function
of X with the smallest possible dimension such that
, which also implies
. The resulting ATE estimator is asymptotically more efficient than the estimator using the entire X unless
. De Luna, Waernbaum, and Richardson (Citation2011) further considered an
which removes the components in
that are unrelated to T. This
is the smallest dimensional
that satisfies
, which also implies
. However, it is proved in the Appendix that the asymptotic variance using
is larger than that of
unless
; see also Brookhart et al. (Citation2006), Shortreed and Ertefaie (Citation2017).
Note that the estimation of can be done by estimating
and
separately and then taking the difference. If a linear function
of X satisfies
and has the smallest dimension, then
has a dimension no larger than that of
defined in Hahn (Citation2004), k = 0, 1. Hence, our approach alleviates the curse of dimensionality more and it produces asymptotically more efficient estimator of θ.
In applications, and
have to be estimated using observed data. We adopt the existing nonparametric sufficient dimension reduction methods (Cook & Weisberg, Citation1991; Li, Citation1991; Xia, Tong, Li, & Zhu, Citation2002) to construct estimators
of
. We establish the asymptotic normality for our estimator of θ based on
and
, and compare its efficiency with an asymptotic efficiency bound. We also compare the performances of various estimators in simulation studies and apply our method to the medical cost data from the UW Health System.
2. Methods
Without dimension reduction, three types of nonparametric estimators for θ have been proposed in the literature. The inverse propensity weighting (IPW) method (Firpo, Citation2007) is a weighed version of the procedure in Koenker and Bassett (Citation1978) for the quantile estimation problem.
The regression (REG) method (Cattaneo, Citation2010; Chen et al., Citation2015) estimates the function by
using a nonparametric method and data under T = k for k = 0, 1 separately, where
is the check function (Koenker & Bassett, Citation1978) and
is the indicator function. Finally, Cattaneo et al. (Citation2013) and Chen et al. (Citation2015) combined IPW and REG to obtain the so-called augmented inverse propensity weighting (AIPW) estimator.
For each k, let with
, where
denotes the transpose of a
deterministic matrix with the smallest possible
, k = 0, 1. As a consequence of Theorem 2.1 stated below, estimators using
as covariate sets are asymptotically more efficient than those using X as covariate set when
(if
, then
). In the estimation of ATE, Hahn (Citation2004) recommended to replace X by
, but the dimension of
is no smaller than that of
, which leads to efficiency loss as a consequence of Theorem 2.1.
In applications, has to be estimated by
, and we adopt a nonparametric sufficient dimension reduction method to construct
(Cook & Weisberg, Citation1991; Li, Citation1991; Ma and Zhu, 2012; Xia et al., Citation2002). Since the distribution of
is the same as
, we separately estimate
using the observed data
in group T = k. To estimate the dimensions of
and
, we adopt consistent criteria such as BIC-type criteria introduced by Zhu, Zhu, and Feng (Citation2010) and bootstrap based criteria.
Let ,
, k = 0, 1. In our IPW method, we estimate the propensity
by
using a nonparametric method for
separately. The IPW estimator of θ is
, where
(1)
(1) and
,
.
The REG method estimates by
using a nonparametric method for k = 0, 1 separately, and estimates θ by
, where
(2)
(2) We can combine IPW and REG to obtain our AIPW estimator,
, where
(3)
(3) To estimate
and
in (Equation1
(1)
(1) )–(Equation3
(3)
(3) ), we use the nonparametric kernel estimators (Silverman, Citation1986):
where
,
is a
-dimensional kernel function,
is the dimension of
, and
is the bandwidth matrix. When
is standardised, we consider
with scalar bandwidth
and identity matrix
(Hardle, Muller, Sperlich, & Werwatz, Citation2004). As in Hu, Follmann, and Wang (Citation2014), the nonparametric kernel estimators are computed using the rth order Gaussian product kernel with standardised covariates. The bandwidth we used here is
, where
is the order of
, k = 0, 1. To determine the constant C we adopt the J-fold cross validation, i.e. we select C that minimises
where J is the total number of folds and
is the estimator of θ with all data but not those in the jth fold,
. We use J = 10 in our simulations in Section 3.
The following theorem establishes the asymptotic normality of estimators in (Equation1(1)
(1) )–(Equation3
(3)
(3) ) and assesses the efficiency of estimators.
Theorem 2.1
Assume the conditions stated in the Appendix. Let be one of
,
, and
in (Equation1
(1)
(1) )–(Equation3
(3)
(3) ) with
replaced by
satisfying
, k = 0, 1, and let
be the same estimator with
replaced by its estimator
, where
for some functions
with
, k = 0, 1,
is a column vector whose components are elements of a matrix M, and
denotes a quantity converging to 0 in probability. Then we have the following conclusions.
(i) is asymptotically normal with mean 0 and variance
(4)
(4) where
and
is the p.d.f. of
,
.
(ii) is asymptotically normal with mean 0 and variance
(5)
(5) where
and
Theorem 2.1(i) justifies our choice of .
in (EquationA1
(A1)
(A1) ) is in fact the semiparametric efficiency bound of estimating θ following the ideas in Bickel, Klaassen, Ritov, and Wellner (Citation1993), Hahn (Citation1998) and Firpo (Citation2007). Details can be found in Lemma A.1 in the Appendix. However, in practice, the IPW estimator may not have enough estimation efficiency, as it does not fully extract the information contained in the auxiliary variables. While, the REG and AIPW estimators use all observed covariates to improve estimation efficiency.
By (EquationA1(A1)
(A1) ) and Jensen's inequality, among all linear functions
satisfying
,
is minimised when
has the smallest possible dimension, i.e.
, k = 0, 1. In particular, this applies to
proposed in Hahn (Citation2004), since the dimension of
is no smaller than that of
.
The sum of last two terms on the right hand side of (Equation5(5)
(5) ) quantifies the price we may pay for estimating
by
. There is an efficiency loss due to estimating
by
when this sum is positive, while it is possible that this sum is negative so that we have an efficiency gain. If we further include the covariates related to T, i.e. consider
being the smallest possible dimensional
satisfying
and
, k = 0, 1, then
and
, hence,
and
are asymptotically equivalent. However, it is generally not a good idea to use
, because each
has a dimension no smaller than that of
and therefore both
and
is less efficient than
according to Theorem 2.1. Although
may be less efficient than
due to the estimation of
, it may still be more efficient than
. Some simulation results are given in Section 3.
In Theorem 2.1, the condition with
is satisfied for
obtained using some sufficient dimension reduction methods (Hsing & Carroll, Citation1992; Zhu & Ng, Citation1995).
3. Simulation
We investigate the finite-sample performance of three estimators, ,
, and
, with four choices of linear functions
, (1)
, k = 0, 1, (2)
, (3)
, k = 0, 1, and (4)
. For each choice of
, we consider estimators using the true
as well as
by sufficient dimension reduction. Thus, we consider a total of
cases. In each case, we consider the estimation of the QTEs with
,
, and
, under two different sample sizes n = 200 and n = 1000.
In the first simulation, with independent
components,
,
, and
, where
's are independent
and are independent of X. The outcome models are linear in X, the treatment model is logistic, and the log-conditional treatment odds is linear in X. Under this model,
,
, and
are all one-dimensional, while
is two-dimensional.
In the second simulation, with independent
components,
,
, and
, where
's are independent
and are independent of X. The outcome models are nonlinear in X, the treatment model is logistic, and the log-conditional treatment odds is nonlinear in X. Under this setting, each
is two-dimensional,
is three-dimensional, while
,
, and
are four-dimensional and not the same.
Based on 1000 simulation runs, we calculate the simulated relative bias (RB) and standard deviation (SD) in each scenario. The results for simulations are given in Tables –, respectively. The following conclusions can be obtained from the simulation results in Tables –.
When the true
is used,
When estimator
The performances of estimators using the true
Consistent with the asymptotic theory, the performance of estimators using
Regarding the three different estimation methods,
Table 1. Relative bias and standard deviation for simulation 1 with true or estimated and .
Table 2. Relative bias and standard deviation for simulation 2 with true or estimated and .
4. Real data analysis
As we mentioned in the introduction, the University of Wisconsin Health System became an Accountable Care Organization (ACO) and implemented a Complex Care Management (CCM) programme since January 1, 2013. In particular, a team of nurses take responsibility for coordinating and implementing complex patients' care plan. The CCM is very intensive in time and resources and therefore it is important to evaluate its specific value.
We demonstrate the proposed estimation methods in a data set resulted from the University of Wisconsin Health ACO study where the primary outcome Z is the annualised payment amount in thousands. The data set consists of 894 patients with 186 in the CCM group (T = 1) and 708 not in the CCM group (T = 0).
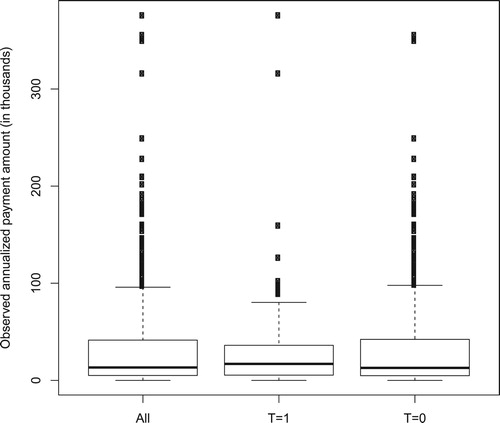
Two issues with this dataset actually motivated our study. First, the distribution of annualised payment is right-skewed as shown by the box plots in Figure for all patients and two groups. The overall median, mean, 75% quantile, and maximum of observed payment are about 13, 31, 41, and 376 thousand dollars, respectively. This suggests the need for estimating quantile treatment effects. Second, the dataset consists of three discrete and ninety-four continuous covariates including medicare status, baseline payments, as well as other baseline characteristics of patients. Thus, dimension reduction is needed in nonparametric kernel estimation.
Figure 1. Boxplots of observed annualised payment amount (in thousands) for overall, CCM group T = 1, and non-CCM group T = 0.
For sufficient dimension reduction, we adopt the semiparametric directional regression method proposed by Ma and Zhu (2012). After sufficient dimension reduction, has 7 dimensions,
has 5 dimensions,
has 8 dimensions, and
has 13 dimensions.
Results for three choices of considered in simulation are shown in Table for estimating ATE and QTE with
, 50%, and 75%. Standard errors (SE) for all estimates are calculated using the bootstrap with 200 replications.
Table 3. Estimates and standard errors (SE) for the University of Wisconsin Health ACO data.
From Table , the 25% and 50% QTEs are not significant by all methods. When or
is used, the 75% QTE is significantly less than 0, and in terms of SE, the estimate using
, k = 0, 1, is more efficient than the estimate using
. However, the estimate of 75% QTE using
is inefficient due to the large variation of using
so that the result is insignificant.
Since 75% QTE is significantly negative, the result indicates that receiving CCM intervention effectively helps reducing medical payment for the high-cost patients. But CCM intervention is not so useful for the low-cost or median-cost patients, as 25% and 50% QTEs are not significant. These results may be useful for decision making in ACO.
For comparison, we also include estimates of ATE and SE. The results in the last block of Table show that ATE is not significant by all methods. It is interesting to see that estimates of ATE are all negative whereas estimates of 50% QTE are all positive although they are not significant, which may be caused by fact that the distribution of annualised payment is right-skewed.
The example shows the usefulness of assessing QTEs with different percentages. If we only estimate ATE, no useful conclusion can be made in this example. Even if we check 50% QTE instead of ATE because of the existing skewness, we still cannot obtain any useful conclusion.
Acknowledgments
We are grateful to the editor, the associate editor, and two anonymous referees for their insightful comments and suggestions, which have led to significant improvements.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Ying Zhang
Ying Zhang is a Ph.D. candidate, Department of Statistics, University of Wisconsin-Madison.
Lei Wang
Dr Lei Wang holds a Ph.D. in statistics from East China Normal University. He is an assistant professor of statistics at Nankai University. His research interests include empirical likelihood and missing data problems.
Menggang Yu
Dr Menggang Yu holds a Ph.D. in biostatistics from the University of Michigan. He is now a professor of biostatistics at the University of Wisconsin-Madison. Besides developing statistical methodology related to cancer research and clinical trials, Dr Yu is also very interested in health services research.
Jun Shao
Dr Jun Shao holds a Ph.D. in statistics from the University of Wisconsin-Madison. He is a professor of statistics at the University of Wisconsin-Madison. His research interests include variable selection and inference with high dimensional data, sample surveys, and missing data problems.
References
- Abadie, A., Angrist, J., & Imbens, G. W. (2002). Instrumental variables estimates of the effect of subsidized training on the quantiles of trainee earnings. Econometrica, 70, 91–117. doi: 10.1111/1468-0262.00270
- Bickel, P. J., Klaassen, C. J., Ritov, Y., & Wellner, J. (1993). Efficient and adaptive inference in semiparametric models. Baltimore: Johns Hopkins University Press.
- Brookhart, M., Schneeweiss, S., Rothman, K., Glynn, R., Avorn, J., & Sturmer, T. (2006). Variable selection for propensity score models. American Journal of Epidemiology, 163, 1149–1156. doi: 10.1093/aje/kwj149
- Cattaneo, M. D. (2010). Efficient semiparametric estimation of multi-valued treatment effects under ignorability. Journal of Econometrics, 155, 138–154. doi: 10.1016/j.jeconom.2009.09.023
- Cattaneo, M. D., Drukker, D. M., & Holland, A. D. (2013). Estimation of multivalued treatment effects under conditional independence. The Stata Journal, 13, 407–450. doi: 10.1177/1536867X1301300301
- Chen, X., Wan, A. T. K., & Zhou, Y. (2015). Efficient quantile regression analysis with missing observations. Journal of the American Statistical Association, 110, 723–741. doi: 10.1080/01621459.2014.928219
- Cheng, P. E., & Chu, C. (1996). Kernel estiamation of distribution functions and quantiles with missing data. Statistica Sinica, 6, 63–78.
- Chernozhukov, V., & Hansen, C. (2005). An IV model of quantile treatment effects. Econometrica, 73, 245–261. doi: 10.1111/j.1468-0262.2005.00570.x
- Cook, R. D., & Weisberg, S. (1991). Discussion of ‘Sliced inverse regression for dimension reduction’. Journal of the American Statistical Association, 86, 328–332.
- De Luna, X., Waernbaum, I., & Richardson, T. S. (2011). Covariate selection for the nonparametric estimation of an average treatment effect. Biometrika, 98, 861–875. doi: 10.1093/biomet/asr041
- Doksum, K. (1974). Empirical probability plots and statistical inference for nonlinear models in the two-sample case. The Annals of Statistics, 2, 267–277. doi: 10.1214/aos/1176342662
- Firpo, S. (2007). Efficient semiparametric estimation of quantile treatment effects. Econometrica, 75, 259–276. doi: 10.1111/j.1468-0262.2007.00738.x
- Frölich, M., & Melly, B. (2010). Estimation of quantile treatment effects with Stata. The Stata Journal, 10, 423–457. doi: 10.1177/1536867X1001000309
- Frölich, M., & Melly, B. (2013). Unconditional quantile treatment effects under endogeneity. Journal of Business and Economic Statistics, 31, 346–357. doi: 10.1080/07350015.2013.803869
- Hahn, J. (1998). On the role of the propensity score in efficient semiparametric estimation of average treatment effects. Econometrica, 66, 315–331. doi: 10.2307/2998560
- Hahn, J. (2004). Functional restriction and efficiency in causal inference. Review of Economics and Statistics, 86, 73–76. doi: 10.1162/003465304323023688
- Hardle, W., Muller, M., Sperlich, S., & Werwatz, A. (2004). Nonparametric and semiparametric models. Heidelberg: Springer-Verlag.
- Hsing, T., & Carroll, R. J. (1992). An asymptotic theory for sliced inverse regression. The Annals of Statistics, 20, 1040–1061. doi: 10.1214/aos/1176348669
- Hu, Z., Follmann, D. A., & Wang, N. (2014). Estimation of mean response via the effective balancing score. Biometrika, 101, 613–624. doi: 10.1093/biomet/asu022
- Koenker, R., & Bassett, G. (1978). Regression quantiles. Econometrica, 46, 33–50. doi: 10.2307/1913643
- Lehman, E. L. (1975). Nonparametrics: Statistical methods based on ranks. San Francisco: Holden-Day.
- Li, K. C. (1991). Sliced inverse regression for dimension reduction. Journal of the American Statistical Association, 86, 316–327. doi: 10.1080/01621459.1991.10475035
- Rosenbaum, P. R., & Rubin, D. B. (1983). The central role of the propensity score in observational studies for causal effects. Biometrika, 70, 41–55. doi: 10.1093/biomet/70.1.41
- Shortreed, S. M., & Ertefaie, A. (2017). Outcome-adaptive Lasso: Variable selection for causal inference. Biometrics, 73, 1111–1122. doi: 10.1111/biom.12679
- Silverman, B. W. (1986). Density estimation for statistics and data analysis. London: Chapman and Hall.
- Xia, Y., Tong, H., Li, W. K., & Zhu, L. X. (2002). An adaptive estimation of dimension reduction space. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 64, 363–410. doi: 10.1111/1467-9868.03411
- Zhou, Y., Wan, A. T. K., & Wang, X. (2008). Estimating equations inference with missing data. Journal of the American Statistical Association, 103, 1187–1199. doi: 10.1198/016214508000000535
- Zhu, L. X., & Ng, K. W. (1995). Asymptotics of sliced inverse regression. Statistica Sinica, 5, 727–736.
- Zhu, L. P., Zhu, L. X., & Feng, Z. H. (2010). Dimension reduction in regressions through cumulative slicing estimation. Journal of the American Statistical Association, 105, 1455–1466. doi: 10.1198/jasa.2010.tm09666
Appendices
Appendix 1. Semiparametric efficiency bound of estimating θ with
Throughout the Appendix, the S, ,
,
,
,
are linear functions of X, i.e.
with B being a
matrix,
with
being a
matrix, etc.
Lemma A.1
Assume and
, and the distribution of
has density
with
, k = 0, 1. A lower bound for the asymptotic variance of any asymptotically normal estimator of
is given by
(A1)
(A1) where
, k = 0, 1. If
,
, and
,
, then
, where
denotes the linear space generated by columns of B for
.
Proof
Proof of Lemma A.1
Our derivation of the efficiency bound mimics the proof in Firpo (Citation2007) which is a direct application of the semiparametric efficiency theory from Bickel et al. (Citation1993). Following the proof of Firpo (Citation2007), one may easily see that knowing won't change the semiparametric efficiency bound, which is similar with the ATE case in Hahn (Citation1998). In our proof for Lemma A.1, one only needs to carefully keep
and
separate in the derivation. The construction of the efficient influence function is more involved algebraically. We only provide a sketch of the proof for the case
here. The density of
at
is
where
denotes the conditional distribution of
given X,
denotes the marginal distribution of X and
. The density of
at
is then equal to
where
,
. The second equality holds because by the definition of
, there exist functions
and
that
and
. For a regular parametric submodel
with parameter w,
The score function of this parametric submodel is
where
. Therefore, the tangent space is equal to
For the parametric submodel with parameter ω under consideration,
, the τ-th quantile for
, k = 0, 1, satisfies
. Let
, and remember
, k = 0, 1. By an application of Leibnitz's rule,
Let
and the true parameter ω is
, i.e.
, then we have
(A2)
(A2) For the three terms in (EquationA2
(A2)
(A2) ), after some algebra, we have, respectively,
Therefore,
The efficiency bound is the expected square of the projection of F on
. Because
, the projection of F on
is itself. The conclusion follows.
For the second part of Lemma A.1, suppose ,
satisfy
,
. Since
We only need to prove
By Jensen's inequity, we have
Thus the conclusion follows from the inequality below.
Appendix 2
Conditions for Theorem 2.1
| (C1) |
| ||||
| (C2) |
| ||||
| (C3) |
| ||||
| (C4) | The function | ||||
| (C5) | The kernel | ||||
| (C6) | The smoothing bandwidth | ||||
Appendix 3
Proof of Theorem 2.1
Proof
Proof of Theorem 2.1
(i) In the case that , Firpo (Citation2007) proved the asymptotics of
using kernel method, Chen et al. (Citation2015) proved the asymptotics of
using kernel method. Following the proofs in their papers and substituting X by
,
is asymptotically equivalent to
(A3)
(A3) where
is the ith observation of
,
for k = 0, 1. By direct but tedious calculation, the covariance of the two summation terms in (EquationA3
(A3)
(A3) ) is
. Their corresponding variances are
Thus the asymptotic variance of
is
(ii) Here we only list the proof for regression type estimator
with
. We only derive the difference of
between using true
and estimated
for regression estimator, the proof for the
is similar. For simplicity, we denote
,
,
,
,
,
as S, B, h,
,
,
respectively and define
in the following proof. Let
, it can be verified that
where
Since
, using a Taylor expansion around
for
and plugging in
, we have
Denote
and
. Note
and
Therefore,
where
It can be seen that the first term in
will equal to 0 if
, while the second term in
will equal to 0 if
. Thus when both
and
hold, we will have
. Let
, we have
Thus we have
, which leads to
For
, we also use a Taylor expansion for
:
We then decompose
by conditioning on index i, j, that is we define
Since
using a similar decomposition method as
, we can also show
and
. Thus we proved that
Note that the REG estimator for
based on estimated S is:
Let
,
, the optimisation will change to
Similar with the proof in Firpo (Citation2007), one may check that the second term equals to
. Hence we have
The last equation follows from the proof in Chen et al. (Citation2015), which is the linearisation for the REG estimator using true S. Repeat all above procedure for
, and plug in the linearisation for
, we could get the linearisation for
, hence Theorem 2.1 is proved.
Appendix 4
Asymptotic variance comparisons between using and using
We first prove that the asymptotic variance using will be larger than using X. Following the proof below, one may also easily prove using
in De Luna et al. (Citation2011) is larger than
unless
, by replacing original covariate set X with
and replacing
with
. Adapting the proof for Theorem 2.1, we can find that for any S that satisfies
, the asymptotic variance for using
in
is
Since
satisfies
, we also have
thus
. Therefore the asymptotic variance for
using
is:
The asymptotic variance for
using X is:
Therefore
(A4)
(A4)
(A5)
(A5)
(A6)
(A6) Let
The expression (EquationA4
(A4)
(A4) ) equals
Similarly, the expression (EquationA5
(A5)
(A5) ) equals
and the expression (EquationA6
(A6)
(A6) ) equals
Since
, therefore
which completes the proof.
See Figure for difference choices of and Figure A1 for the comparisons of efficiency of estimator
based on different
,
.
Appendix 5
Asymptotic variance comparisons between using and using
In this section, we prove that the asymptotic variance of is smaller than asymptotic variance of
, followed by those of
. From the proof of Theorem 2.1, for all
satisfying
, the asymptotic variance of
is
For
and
, the asymptotic variances
and
are
Thus we only need to prove
By Jensen's inequity,
Hence
. Note that from Lemma A.1 we have
, i.e.
. Then the other result follows from
, which is proved in the Appendix 4.
Figure A1. Five choices of in the space of all linear combinations of X. For
and
, the first row are
for estimating
characteristics, the second row are
for estimating
characteristics.
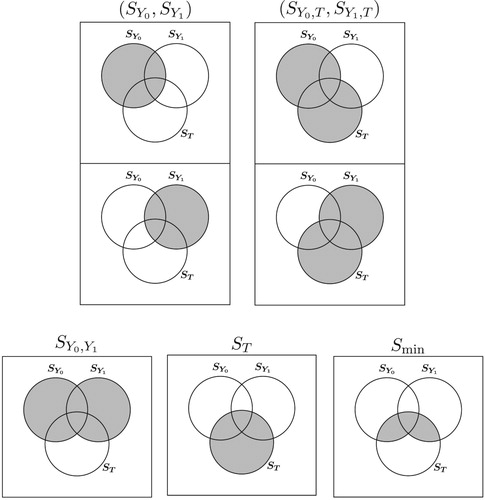
Figure A2. Relative efficiencies of estimators. Solid arrow from A to B means that A is more asymptotically efficient than B. Dashed arrow from A to B means that empirically A is more efficient than B.