?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Smoothing spline is a popular method in non-parametric function estimation. For the analysis of data from real applications, specific shapes on the estimated function are often required to ensure the estimated function undeviating from the domain knowledge. In this work, we focus on constructing the exact shape constrained smoothing spline with efficient estimation. The ‘exact’ here is referred as to impose the shape constraint on an infinite set such as an interval in one-dimensional case. Thus the estimation becomes a so-called semi-infinite optimisation problem with an infinite number of constraints. The proposed method is able to establish a sufficient and necessary condition for transforming the exact shape constraints to a finite number of constraints, leading to efficient estimation of the shape constrained functions. The performance of the proposed methods is evaluated by both simulation and real case studies.
1. Introduction
In recent years, non-parametric smoothing methods have gained popularity in various science and engineering areas such as economics, biology, smart manufacturing, etc. One advantage of these methods is that they do not assume strong parametric structure for the underlying model. While in the analysis of data from real applications, researchers often demand a specific shape on the estimated function to ensure the estimated function undeviating from their domain knowledge. For example, shape with monotonicity are often required in the estimation of dose-response function (Kelly & Rice, Citation1990) in medicine. The degradation curve of scaffolds in engineered scaffold fabrication often requires to be monotonic and concave (Zeng, Deng, & Yang, Citation2016). The estimation of human growth curve (Ducharme & Fontez, Citation2004) in biometrics and estimation of utility function (Matzkin, Citation1991) in economics often needs the concavity in shape.
Among various non-parametric smoothers, spline smoothing and kernel smoothing are quite popular. Theoretical and numerical properties of these techniques have been well studied. See Wahba (Citation1990) and Green and Silverman (Citation1993) for thorough discussions of the spline smoothing problem, and Fan and Gijbels (Citation1996) and Wand and Jones (Citation1995) for the kernel smoothing problem. Unlike its unconstrained counterpart, shape constrained smoother has not received large attentions in the statistics literature. As pointed in Delecroix and Thomas-Agnan (Citation2000), most of the isotonic estimates are based on splines rather than on kernels since enforcing the restrictions at the minimisation step appears to be a natural solution.
There are various splines to enable the shape constraints. For example, B-spline is a popular approach because of its special properties: non-decreasing coefficients imply non-decreasing resulting function (Brezger & Steiner, Citation2003; Dierckx, Citation1980; He & Shi, Citation1998; Kelly & Rice, Citation1990). There are also I-spline methods (Curry & Schoenberg, Citation1966; Ramsay, Citation1988) to integrate over non-negative M-splines for constructing monotone smoothers. Meyer (Citation2008) defined the C-splines that at each observation to impose the shape constraint. Combinations of monotonicity and convexity can be imposed by the regression splines. Meyer (Citation2012) also developed penalised splines under shape constraints. (Liao & Meyer, Citation2017) proposed estimators of change-point based on constrained splines. Meyer (Citation2018) proposed the constrained generalised additive model using iteratively reweighted cone projection algorithm. The smoothing spline is another popular approach, of which the most notable works include (Wang & Li, Citation2008)'s second order cone programming to create monotone smoothing spline and (Turlach, Citation2005)'s approach of adaptively adding constraints to create shape constrained smoothing spline.
In this work, we consider the smoothing spline to study the exact shape constraints. Here the meaning of ‘exact’ is referred as to impose the shape constraint on an infinite set such as an interval in one-dimensional case. It leads to a so-called semi-infinite optimisation problem with an infinite number of constraints. Suppose that the observational data are for
, and we assume
. The exact shape constrained smoothing spline is defined as the solution of the following optimisation problem:
(1a)
(1a)
(1b)
(1b) where
is the rth derivative of
and
is a tuning parameter. The formulation in (Equation1a
(1a)
(1a) ) without constraint is the well-known smoothing spline problem, the solution of which is known as the cubic smoothing spline over the class of twice differential functions. The framework for r = 1 and r = 2 corresponds to the monotone non-decreasing and convex shape constraint, respectively. The monotone decreasing or concave constraint can be easily obtained by reversing the inequality sign in (Equation1b
(1b)
(1b) ). One can pursue either one of the constraints or some of them under this framework. For example, non-global constraint, such as convex for
and concave for x>0 is possible. A mixed constraint, such as combination of concave and monotone increasing, can also be applied.
The challenges for the estimation in (Equation1(1a)
(1a) ) is the constraints are defined on an infinite set, which implies an infinite number of constraints. By taking advantage of the close connection between the natural cubic spline and the smoothing spline, the proposed method utilises a good representation of smoothing spline to establish a sufficient and necessary condition for transforming the exact shape constraints in (Equation1b
(1b)
(1b) ) to a finite number of constraints. The resultant solution to the case of r = 2 is straightforward, and the challenge arises when r = 1. To the best of our knowledge, an exact solution for r = 1 has yet to be found in the literature. To facilitate the computation of parameter estimation, we also develop efficient algorithm based on matrix approximation for the large data.
The remaining paper is organised as follows. Section 2 revisits the connection between the natural cubic splines and smoothing splines. The proposed exact shape-constraint smoothing spline is detailed in Section 3. An efficient computation algorithm for parameter estimation are developed in Section 4. Sections 5 and 6 evaluate the performance of the proposed method from a simulation study and an application to real life data. We conclude this work with some discussion in Section 7.
2. Revisit of natural cubic spline and smoothing spline
The natural cubic spline (NCS) plays an essential role for the smoothing spline. Suppose that the observed data are with
. An NCS function
with knots at
is a piecewise polynomial of degree up to three with breakpoints at
. In addition,
is twice continuously differentiable at the knots and linear beyond the boundary.
Let be a NCS with knots at
. By definition,
can be expressed as
(2a)
(2a)
(2b)
(2b) The derivatives of
can be obtained by taking derivative on each polynomial and maintaining the relevant constraints. Please refer to Appendix 1 for explicit expressions. This piecewise polynomial representation of an NCS in (Equation2
(2a)
(2a) ) is a key for formulating the shape constraints in Section 3. For estimation of
, however, there exists another presentation for computational purpose. Specifically, we first estimate
by writing them as a linear combination of specific basis functions and estimate the corresponding coefficients. Then we can utilise the value-second derivative representation (Green & Silverman, Citation1993) to recover the entire function
. As a result, the problem in (Equation1a
(1a)
(1a) ) can be converted into a ridge regression-like problem that can be efficiently solved.
Let be length-n vector of ones,
and
. Without loss of generality, we assume
is centred with zero mean. We can construct the banded matrices
and
according to Equations (EquationA1
(A1)
(A1) ) and (EquationA2
(A2)
(A2) ) in Appendix A.2. The linear mixed model representation described in Appendix A.3 allows us to rewrite the NCS formulation in (Equation2
(2a)
(2a) ) as
(3)
(3) here
. The
and
are parameters. By construction, matrix
has full rank. It is easy to check that
,
and
. Hence
form a basis of the n-dimensional euclidean space. Furthermore, if we define matrix
, then we get:
(4)
(4) It is worth to pointing out that the underlying model for the smoothing spline can be considered as a natural cubic spline with knots at
and at most
additional knots of which the locations are unknown (Utreras, Citation1985). Here we made a mild assumption that
is a natural cubic spline with knots at
. Combining this assumption with results in (Equation3
(3)
(3) ) and (Equation4
(4)
(4) ), the smoothing spline expressed in (Equation1a
(1a)
(1a) ) is equivalent to the problem of
(5a)
(5a) where
is the ith row of matrix
. This is simply a ridge regression problem with response vector
and covariates matrix
without penalising
and
.
When one obtain the estimate of , the entire estimated function can be constructed by following the procedure in Appendix A.3. one can actually obtain the piecewise polynomial representation of the estimated function by following the steps in Appendix A.4. That is, the piecewise polynomial representation is fully specified when
are known.
3. Exact shape-constrained smoothing spline
To have the exact shape constraint, one major difficulty is that the inequality constraint in (Equation1b(1b)
(1b) ) cannot be guaranteed by simply enforcing constraints at
. Due to these challenges, many computable ‘solutions’ to the shape constrained smoothing spline problem described in ((Equation1a
(1a)
(1a) ) and (Equation1b
(1b)
(1b) )) are approximations of some kind. Some approximate by assuming the resulting function being a natural cubic spline with knots at all data points (Turlach, Citation2005; Wang & Li, Citation2008), others approximate by discretisation of infinite constraint (Equation1b
(1b)
(1b) ) to a finite number of constraints (Mammen & Thomas-Agnan, Citation1999; Nagahara & Martin, Citation2013; Villalobos & Wahba, Citation1987).
It is known that the solution to the exact shape-constraint smoothing spline in (1a) and (1b) is a natural cubic spline with knots at and at most
additional knots of which the locations are unknown as proved in Theorem 3.3 in (Utreras, Citation1985). Unfortunately, it does not provide much practical use because of the unknown locations of those additional knots. However, it sheds some lights that a natural cubic spline with knots at all data points is an adequate approximation to the theoretically correct model proved by Utreras (Citation1985). Therefore, we develop our proposed method under the consideration that the estimated model is a natural cubic spline with knots at all data points. Specifically, we propose a representation only using n−1 constraints that is equivalent to the infinite constraint (Equation1b
(1b)
(1b) ) for
. Compared to Turlach (Citation2005) who took an adaptive approach to adding constraints and thus changing the underlying quadratic program for parameter estimation, the proposed method optimises over a larger underlying model space yet it maintains the exactness of the shape constraint. Different from Wang Li (Citation2008) who only works on monotonicity constraint (r = 1), our proposed method also works on convexity constraint (r = 2) and can easily be extended to mixed and non-global constraint.
The key idea of our proposed method is to utilise the piecewise polynomial representation of NCS to provide a sufficient and necessary condition in converting constraint (Equation1b(1b)
(1b) ) for r = 2 and r = 1 to the form of
, where we define notation ≽ as element-wise greater than or equal to. Then we can express the shape constrained smoothing spline problem as
(5a)
(5a)
(5b)
(5b) The formulation above can be optimised by many standard optimisation methods that take non-linear constraints.
The shape constraint (Equation1b(1b)
(1b) ) for r = 1 (monotonicity) and r = 2 (convexity) are presented below as Theorems 3.1 and 3.2, respectively. The mixed constraints can be achieved by combining the corresponding constraints.
Theorem 3.1
For the smoothing spline, the monotone non-decreasing constraint, defined as holds if and only if constraint (Equation5b
(5b)
(5b) ) with
(6)
(6) holds.
Proof.
Based on the polynomial representation of NCS, it is easy to get the first derivative as
(7)
(7) Clearly,
is a continuous piecewise polynomial of at most second order on each interval
,…,
, and constant on the boundary interval
, and
. For
, if
,
is a linear function on
, so
on the interval. If
,
is a parabola on
with stationary point at
, specifically
if
,
if
If the stationary point is not on the interval,
If the stationary point is on the interval, global minimum could be at either the boundary or the stationary point, so
Non-negativity on the boundary interval and
hold if
and
. But no extra constraint is needed because by continuity of
,
and
, non-negativitiy is already ensured by
and
.
If , then each piecewise polynomial,
for
, is non-negative, which in turn implies that the whole function
must be non-negative. Therefore, validity of inequality (Equation6b
(5b)
(5b) ) implies the monotone non-decreasing constraint.
The other direction is obvious by definition.
Theorem 3.2
For the smoothing spline, the convexity constraint, defined as , holds if and only if constraint (Equation5b
(5b)
(5b) ) with
(8)
(8) holds.
Proof.
Based on the polynomial representation of NCS, it is easy to get the first derivative as
(9)
(9) The
is a continuous piecewise linear polynomial on each interval
,
,…,
and
. Since
for any
and
, we only need to consider
when
. For any i, linearity of
implies
on interval
. If
, each piecewise polynomial,
for
, is non-negative, which in turn implies that the whole function
is non-negative. Therefore, inequality (Equation6b
(5b)
(5b) ) implies convexity constraint.
The other direction is obvious by definition.
The above theorems are defined for global constraint, i.e. constraint that holds on the entire domain of the function . To extend the results to mixed constraint and non-global constraint, we can easily apply Theorem 3.2 and Theorem 3.1 to different local intervals
, where
. In addition, we can impose up to second-order smooth constraint on the boundary of local intervals. A general procedure is described as follows:
Let
For each interval, impose constraint according to Theorem 3.2 and Theorem 3.1.
For
The importance of Step 3 is that it can prevent the stationary/inflection point of the estimated function from floating between the knots immediately smaller and larger than the point where monotonicity/convexity changes.
4. Efficient algorithm for parameter estimation
Note that the optimisation problem described in (Equation6a(5a)
(5a) ) and (Equation6b
(5b)
(5b) ) is a quadratic programming with non-linear constraints. Using Python, our implementation algorithm is based on the ralg solver under the OpenOPT platform. The ralg solver resembles the quasi-Newton Method with adaptive space dilation developed by Shor and Zhurbenko (Citation1971). Two advantages for this choice are that it accepts user-provided first-derivative and allows large number of constraints.
4.1. Computation of large data
When the number of observation n is large, the growing dimension of the matrix
and vector of constraints
are the bottleneck for efficient computation. To address this challenge, we consider to approximate the matrix
by a
dimensional matrix
, where
is independent of n. It also allows the dimension of
to be some fixed integer
.
Following Wand and Ormerod's (Citation2008) mixed model formulation in the semiparametric regression, we adopt a good way to approximate with
, where
is an
matrix and
is an
matrix.
The construction of is described as follows. First we define
as
Then we construct B-spline basis functions (Hastie, Tibshirani, & Friedman, Citation2001)
based on knots sequence
as
for
, and
for m = 2, 3, 4 and
. Consequently, the matrix
is constructed with its
entry
.
The construction of matrix is described as follows. First we define an
matrix
with its
entry as
(10)
(10) where function
is the second derivative function of
for
as following:
Based on the spectral decomposition,
can be written as
, where
is an orthogonal matrix and
is diagonal matrix with K + 2 positive entries and two zero entries on the diagonal. Let
be a vector that contains the K + 2 positive entries in matrix
, and matrix
contains the columns in
of which their positions correspond to those positive entries in
. Then
is constructed as
, where
denotes a diagonal matrix with diagonal entries equal to vector
.
Wand and Ormerod (Citation2008) shows that when K = n−2, . When K<n−2, by substituting matrix
by
, the length of parameter vector
reduces to K + 2 since the length of vector
is K. Another advantage of using
is that other than the fact that
, the choice of K is independent to n.
The essence of this approximation attributes to the construction of matrix in Step 1(c) above. The choice of K controls the length of knots sequence being used in the construction of the B-spline basis functions. When K is at its maximum of n−2, all data are used as the knots sequence. Then no approximation will occur. When K<n−2, a proper subset of data is used as the knots sequence. One can understand this reduction in the length of knots sequence as approximating the full data with a properly chosen (equally spaced in terms of percentile) subset of data. As a result of this approximation, there is a reduction in dimension from
to
. For a proper choice of K, a large value of K close to n may not lead to significant computational gain. While a small value of K could make the approximation low accurate. From our empirical experience, K = 30 provides a good balance between computational gain and approximation quality.
4.2. Tuning parameter selection
The tuning parameter λ controls the smoothness of the estimated function. As , the estimated function approaches linearity (smoothest); whereas when
, the estimated function tends to the natural cubic spline interpolant (roughest). Although the incorporation of appropriate monotonicity and/or convexity constraints helps smooth out unnecessary roughness in the estimated function, the choice of tuning parameter λ for the exact shape constrained smoothing spline is still important in obtaining a good fit. In this work, we select the optimal value of λ that minimises mean squared error using k-fold cross-validation.
5. Simulations
In this section, we evaluate the performance of our proposed method, the shape constraint smoothing spline (SCSS), under various non-linear functions and error combinations. The methods of comparison include the Brunk's isotonic non-parametric estimator (Brunk), the unconstrained smoothing spline (SS), the proposed SSCS with global monotone non-decreasing constraint (SSCS-Monotone), the proposed SSCS with problem specific convexity constraint (SSCS-Convex), and the proposed SSCS with global monotone non-decreasing and problem specific convexity constraints (SSCS-Mixed). In addition, we also compare the regression spline under the aforementioned three types of constraints, respectively, denoted as RS-Monotone, RS-Convex, and RS-Mixed. We also compare the B-spline method under the monotone non-decreasing constraint (BS-Monotone) and problem specific convexity constraint (BS-Convex). The regression spline and the B-spline methods are implemented using R Package cgam and spline2, respectively. Note that Wang and Li (Citation2008) kindly provided their code for comparison, but requires a commercial optimiser, MOSEK, which we currently have no access to.
The simulation data are generated from the following model:
where
distributes uniformly between -10 to 10. The function
varies among examples as follows:
Example 1:
Example 2:
Example 3:
Example 4:
Example 5:
Figure shows the visualisation of above functions. For each example above, three different distributions for ε are considered: 1) the normal distribution ; 2) student t distribution with 10 degree of freedom; and 3) Beta distribution
. These error distributions have zero mean and standard deviation
. These simulation setup is identical to Wang and Li (Citation2008), except we added a globally convex function in Example 5. For each setting, the simulation is repeated for 500 times. The mean squared prediction error
is used as an evaluation criterion.
Figure 1. Comparison of the five true functions used in simulation studies.
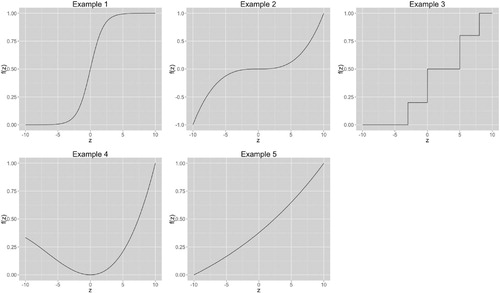
Table reports the averaged MSPE () and its standard error (
) over 500 repetitions for methods in comparison. It is clear that the proposed methods with appropriate constraint have smaller MSPE than other methods in comparison. Note that it is important to impose appropriate constraint. In Example 4 which has a quadratic-shaped function, The performance of SCSS-Monotone is not as good as the SS since the monotone constraint is not proper here. When imposing the convexity constraint, the SCSS-convex performs much better than other methods. It is worth pointing out the B-spline method has comparable performance to the proposed method in Example 1, but not as good as the proposed method in other examples.
Table 1. Simulation studies comparing SCSS and other estimators under different functions and errors settings.Averaged MSPE () and its standard error () over 500 repetitions are reported. NA entries correspond to methods with no applicable settings.
Figure 5 to 10 in Appendix 3 report the estimator percentiles ( and
) of SCSS and other estimators for Example 4 and Example 5. The SCSS-Monotone, SCSS-Convex and SCSS-Mixed produce slightly smoother percentile intervals compared to other methods, especially at the left and right boundaries on the x axis. Example 4 reveals the behaviour of SCSS under a mis-specified monotone constraint. On the interval
, the true function in Example 4 is monotone decreasing but SCSS-Monotone is constrained to be non-decreasing.
To further examine the rate of convergence, we consider a numerical study to check the proposed method's convergence as the sample size gets large. Taking Example 5 for elaboration, we allow the same size increasing gradually from to n = 300. At each given sample size, we compare the discrepancy between
and
by
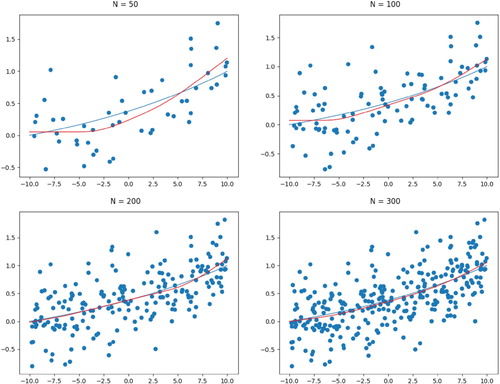
, Table shows that as sample size increases, the function estimated by SCSS is getting closer to the true function. Figure reports the convergence of the estimated function in Example 5 under the normal error and convex constraint. Results for the other two constraints can be found in the Appendix 3.
Figure 2. SCSS convergence for function in Example 5 under normal error and convex constraint.
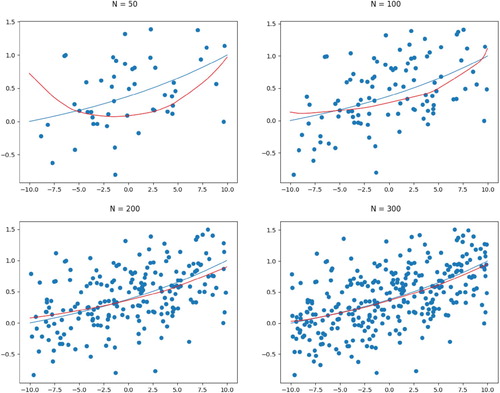
Table 2. Simulation studies measuring the convergence of SCSS based on the integrated mean squared errors.
6. Real data analysis
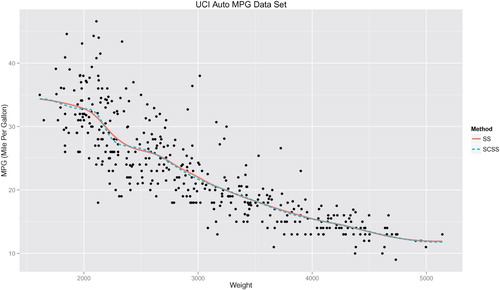
In this section, we evaluate the performance of the proposed SCSS methods in comparison with the regular smoothing spline (SS). The Auto MPG Data from UCI Machine Learning Repository (Lichman, Citation2013) is used for our demonstration. This dataset concerning fuel consumption contains 398 observations with nine attributes: fuel consumption (miles per gallon), number of cylinders, engine displacement (cubic inches), horsepower, vehicle weight (pounds), time to accelerate from 0 to 60 mph (sec.), model year (modulo 100), origin of car (1. American, 2. European, 3. Japanese) and car names. For both methods, the optimal value of tuning parameter λ by minimising the average mean squared error from 10-fold cross-validation.
We first analyse relationship between the weight (weight) and the fuel consumption (mpg) of vehicles. Figure confirms the intuition of a negative correlation between weight and mpg. Without any constraint, SS provided a monotone estimate that is consistent with the intuition. On the other hand, it is assuring to see that SCSS-Monotone provides an estimate that almost overlaps its unconstrained counterpart.
Figure 3. Comparison between unconstrained (SS) and monotone constrained (SCSS) smoothing spline for the Auto MPG Data. The response is mpg, modelled as a function of weight.
Next we consider the vehicle's volume (displacement) to be the predictor variable instead of weight. In general, one would expect a negative correlation between mpg and displacement. Figure reveals the potential problem when prior knowledge on the function shape is not incorporated. The wiggly function estimated by SS contradicts the expectation of a monotone decreasing relationship between mpg and displacement. While the proposed SCSS-monotone capture the pattern of data quite well.
Figure 4. Comparison between unconstrained (SS) and monotone constrained (SCSS) smoothing spline for the Auto MPG Data. The response is mpg, modelled as a function of displacement.
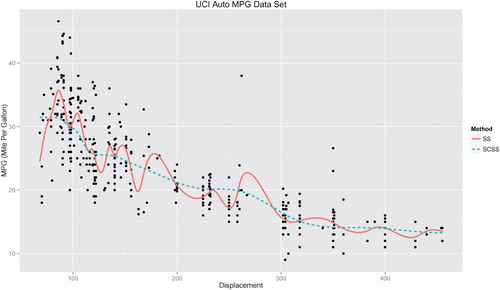
In a short summary, when one has prior shape information about the function to be estimated, it would be better to incorporate it into the estimation process. The proposed shape constraint smoothing spline can effectively help avoid unexpected results from non-parametric method.
7. Discussion
In this work, we proposed to impose the exact shape constraint on the smoothing spline, and enable efficient estimation. Compared to other methods also based on the fundamental assumption that the resulted function is a NCS with knots at all data points, the proposed SCSS method guarantees constraints to be followed exactly and also allows mixed and/or non-global constraints.
The technique developed in the SSCS method can be extended for the additive model, partially linear regression model, the non-parametric model with covaraites, etc. The theoretical investigation of the asymptotic convergence of SSCS can be quite challenging due to the exact (i.e. over an interval) constraint. Some theoretical results are available for functional ANOVA using spline with shape constraint at given finite locations (Dai & Chien, Citation2017). However, such results can not be easily extended to the smoothing spline with exact constraint. Another future study is to formulate necessary and sufficient conditions for function bound constraint and log-convexity constraint. In addition, efficient optimisation methods that take advantage of a quadratic program with non-linear constraints could be useful for further enhance our proposed method.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Vincent Chan
Vincent Chan obtained his Ph.D. from the department of statistics at University of Wisconsin-Madison. His research interests include single index model and regularization.
Kam-Wah Tsui
Kam-Wah Tsui is a professor in the department of statistics at University of Wisconsin-Madison. His research interests include Bayesian analysis, decision theory, survey sampling, and statistical inference.
Yanran Wei
Yanran Wei is a Ph.D. student in the department of statistics at Virginia Tech. Her research interests include Big Data analytics, and statistical modeling in financial application.
Zhiyang Zhang
Zhiyang Zhang is a faculty in the department of statistics at Virginia Tech. Her research interests include modeling complex data, and statistical modeling in chemistry applications.
Xinwei Deng
Xinwei Deng is an associate professor in the department of statistics at Virginia Tech. His research interests include machine learning, design of experiment, and interface between machine learning and experimental design.
References
- Brezger, A., & Steiner, W. J. (2003). Monotonic regression based on Bayesian P-splines: An application to estimating price response functions from store-level scanner data. Tech. rep., Discussion paper//Sonderforschungsbereich 386 der Ludwig-Maximilians-Universität München.
- Curry, H. B., & Schoenberg, I. J. (1966). On Pólya frequency functions IV: The fundamental spline functions and their limits. Journal D'analyse Mathématique, 17, 71–107. doi: 10.1007/BF02788653
- Dai, X., & Chien, P. (2017). Minimax optimal rates of estimation in functional anova models with derivatives. arXiv:1706.00850.
- Delecroix, M., & Thomas-Agnan, C. (2000). Spline and Kernel regression under shape restrictions. In Smoothing and Regression: Approaches, Computation, and Application (pp. 109–133).
- Dierckx, I. P (1980). Algorithm/algorithmus 42 an algorithm for cubic spline fitting with convexity constraints. Computing, 24, 349–371. doi: 10.1007/BF02237820
- Ducharme, G. R., & Fontez, B. (2004). A smooth test of goodness-of-fit for growth curves and monotonic nonlinear regression models. Biometrics, 60, 977–986. doi: 10.1111/j.0006-341X.2004.00253.x
- Fan, J., & Gijbels, I. (1996). Local polynomial modelling and its applications: Monographs on statistics and applied probability. New York: CRC Press.
- Green, P. J. (1987). Penalized likelihood for general semi-parametric regression models. International Statistical Review / Revue Internationale de Statistique, 55(3), 245.
- Green, P. J., & Silverman, B. W. (1993). Nonparametric regression and generalized linear models: A roughness penalty approach. New York: CRC Press.
- Hastie, T., Tibshirani, R., & Friedman, J, The elements of statistical learning, Springer series in statistics Springer (Vol. 1). Berlin, 2001.
- He, X., & Shi, P. (1998). Monotone B-spline smoothing. Journal of the American Statistical Association, 93, 643–650.
- Kelly, C., & Rice, J. (1990). Monotone smoothing with application to dose-response curves and the assessment of synergism. Biometrics, 46(4), 1071–1085. doi: 10.2307/2532449
- Liao, X., & Meyer, M. C. (2017). Change-point estimation using shape-restricted regression splines. Journal of Statistical Planning and Inference, 188, 8–21. doi: 10.1016/j.jspi.2017.03.007
- Lichman, M. (2013), UCI machine learning repository.
- Mammen, E., & Thomas-Agnan, C. (1999). Smoothing splines and shape restrictions. Scandinavian Journal of Statistics, 26, 239–252. doi: 10.1111/1467-9469.00147
- Matzkin, R. L. (1991). Semiparametric estimation of monotone and concave utility functions for polychotomous choice models. Econometrica: Journal of the Econometric Society, 59,1315–1327. doi: 10.2307/2938369
- Meyer, M. C. (2008). Inference using shape-restricted regression splines. The Annals of Applied Statistics, 2, 1013–1033. doi: 10.1214/08-AOAS167
- Meyer, M. C. (2012). Constrained penalized splines. Canadian Journal of Statistics, 40, 190–206. doi: 10.1002/cjs.10137
- Meyer, M. C. (2018). Constrained partial linear regression splines. Statistica Sinica, 28, 277–292.
- Nagahara, M., & Martin, C. F. (2013). Monotone smoothing splines using general linear systems. Asian Journal of Control, 15, 461–468. doi: 10.1002/asjc.557
- Ramsay, J. O. (1988). Monotone regression splines in action. Statistical Science, 3,425–441. doi: 10.1214/ss/1177012761
- Shor, N. Z., & Zhurbenko, N. (1971). The minimization method using space dilatation in direction of difference of two sequential gradients. Kibernetika, 3, 51–59.
- Turlach, B. A. (2005). Shape constrained smoothing using smoothing splines. Computational Statistics, 20, 81–104. doi: 10.1007/BF02736124
- Utreras, F. I. (1985). Smoothing noisy data under monotonicity constraints existence, characterization and convergence rates. Numerische Mathematik, 47, 611–625. doi: 10.1007/BF01389460
- Villalobos, M., & Wahba, G. (1987). Inequality-constrained multivariate smoothing splines with application to the estimation of posterior probabilities. Journal of the American Statistical Association, 82, 239–248. doi: 10.1080/01621459.1987.10478426
- Wahba, G. (1990). Spline models for observational data. Philadelphia, Pennsylvania: Siam.
- Wand, M., & Jones, M.. (1995), Kernel smoothing. Vol. 60 of Monographs on statistics and applied probability.
- Wand, M. P., & Ormerod, J. T. (2008). On Semiparametric regression with O'sullivan penalized splines. Australian & New Zealand Journal of Statistics, 50(2), 179–198. doi: 10.1111/j.1467-842X.2008.00507.x
- Wang, X., & Li, F. (2008). Isotonic smoothing spline regression. Journal of Computational and Graphical Statistics, 17, 21–37. doi: 10.1198/106186008X285627
- Zeng, L., Deng, X., & Yang, J. (2016). Constrained hierarchical modeling of degradation data in tissue-engineered scaffold fabrication. IIE Transactions, 48, 16–33. doi: 10.1080/0740817X.2015.1019164
- Zhang, D., Lin, X., Raz, J., & Sowers, M. (1998). Semiparametric stochastic mixed models for longitudinal data. Journal of the American Statistical Association, 93(442), 710. doi: 10.1080/01621459.1998.10473723
Appendices
Appendix 1
We provide some preliminary materials about natural cubic spline (NCS) and smoothing spline. Readers of interest can refer to Wahba (Citation1990) and Green and Silverman (Citation1993) for details.
A.1. Value-second derivative representation
The value-second derivative representation allows specification of a NCS simply by its value and second derivative at each knots. This representation provides a link between the entire NCS and
for
. Let us define
Also, let vector
and
. Note that due to the natural boundary conditions of a NCS,
. In addition, construct
matrix
and
matrix
as follows:
(A1)
(A1)
(A2)
(A2) where
. By construction, matrix
is strictly positive-definite.
Lemma A.1
Theorem 2.1 in Green and Silverman (Citation1993)
The vectors and
specify a natural cubic spline f if and only if the condition
(A3)
(A3) is satified. If (EquationA3
(A3)
(A3) ) is satified then the roughness penalty will satisfy
(A4)
(A4) where
.
This value-second derivative representation provides a formula to recover the entire NCS with and
for
.
A.2. Linear mixed model representation
The linear mixed model representation of an NCS allows us to express as a linear combination of a specific basis functions. Let function f be an NCS on interval
. Denote
the space of square integrable functions on interval
. Let
are absolutely continuous,
be a second-order Sobolev space of the NCS functions. Under the following definition of norm
Wahba (Citation1990) shows that
is a reproducing kernel Hilbert space that can be decomposed into a direct sum of three orthogonal subspaces:
where
is the mean subspace,
is the linear contrast subspace and
is the non-linear subspace. This decomposition means that any NCS function
can be uniquely decomposed into a sum of a constant part, a linear part and a non-linear part as follows:
(A5)
(A5) for some functions
.
Knowing that the solution is necessarily a NCS with knots at , one particular form of Equation (EquationA5
(A5)
(A5) ) is given by the linear mixed model representation (Green Citation1987; Zhang et al. Citation1998) as follows:
(A6)
(A6) where
is a
matrix,
is a length-n vector of ones and
.
Appendix 2
The linear mixed model representation is used for efficient computation of NCS. Meanwhile, the piecewise polynomial representation is used for formulating shape constraint on NCS for the same problem. The connection between linear mixed model representation and piecewise polynomial representation are stated as follows.
A.3. Specifying the NCS function f from and
Given , matrice
and
can be constructed as shown in Appendix A.2. The second derivative vector
, can be obtained by Theorem A.1 as follows,
(A7)
(A7) since
is of full rank by construction. From Section 2.4.1 in Green and Silverman (Citation1993), the derivate of
at knot
and
are
respectively. Finally, with
, the following formula summarised from Section 2.4.2 in Green and Silverman (Citation1993) gives the entire NCS function f:
Hence the NCS function f is fully specified. That is, we can reconstruct NCS function f from
and
.
A.4. Specifying the piecewise polynomial representation given f
The resulting function f can be used to estimate all coefficients ,
,
and
under the piecewise polynomial representation of f. The steps are as follows:
Given
Calculate
Obtain
Using the fact
With
From previous steps with
Obtain
Appendix 3
Figure A1. The estimator percentiles ( and
) of SCSS for function
in Example 4 under normal error.
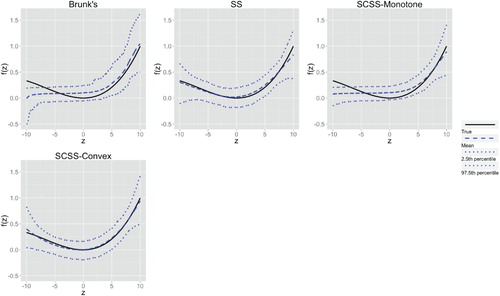
Figure A2. The estimator percentiles ( and
) of SCSS for function
in Example 4 under t error.
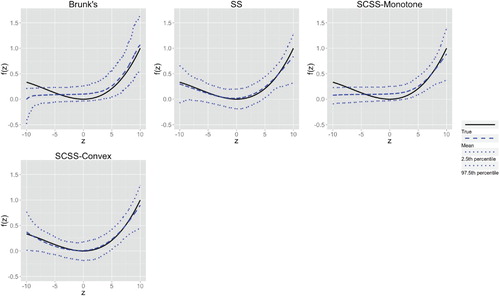
Figure A3. The estimator percentiles ( and
) of SCSS for function
in Example 4 under beta error.
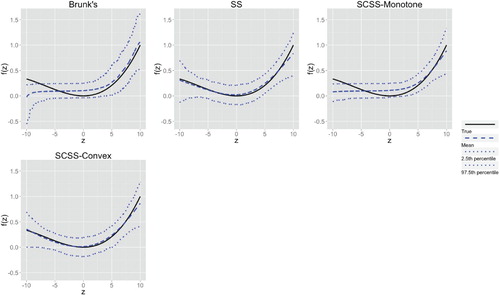
Figure A4. The estimator percentiles ( and
) of SCSS for function
in Example 5 under normal error.
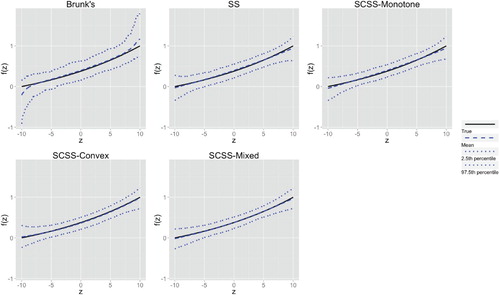
Figure A5. The estimator percentiles ( and
) of SCSS for function
in Example 5 under t error.
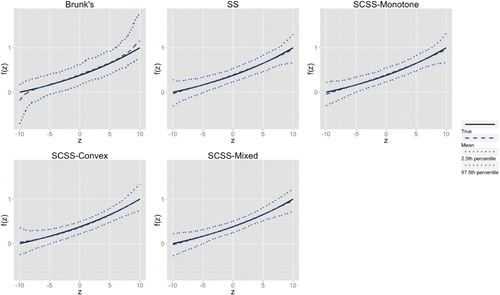
Figure A6. The estimator percentiles ( and
) of SCSS for function
in Example 5 under beta error.
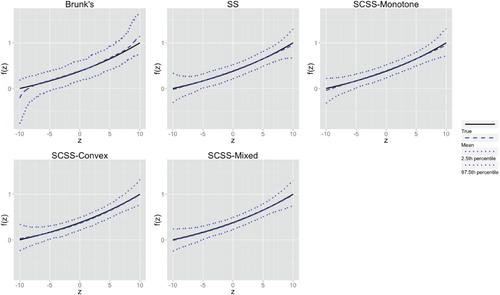
Figure A7. SCSS convergence for function in Example 5 under normal error and monotone constraint.
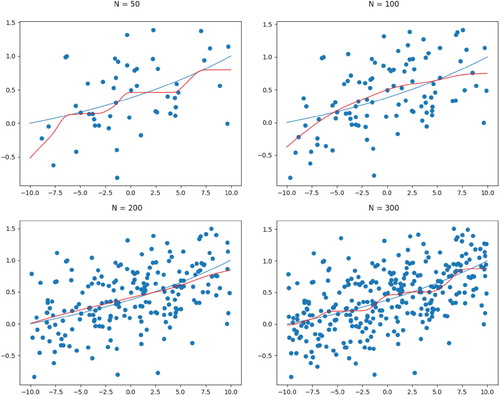
Figure A8. SCSS convergence for function in Example 5 under normal error and mixed constraint.