
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we investigate the problem of estimating the probability density function. The kernel density estimation with bias reduced is nowadays a standard technique in explorative data analysis, there is still a big dispute on how to assess the quality of the estimate and which choice of bandwidth is optimal. This framework examines the most important bandwidth selection methods for kernel density estimation in the context of with bias reduction. Normal reference, least squares cross-validation, biased cross-validation and β-divergence loss methods are described and expressions are presented. In order to assess the performance of our various bandwidth selectors, numerical simulations and environmental data are carried out.
1. Introduction
Selecting an appropriate bandwidth for a kernel density estimator is of crucial importance, and the purpose of the estimation may be an influential factor in the selection method. In many situations, it is sufficient to subjectively choose the smoothing parameter by looking at the density estimates produced by a range of bandwidths. A good overview on kernel density estimators is supplied by Silverman (Citation1986), Scott (Citation1992), Mugdadi and Ibrahim (Citation2004). Let be a sample of size n identically distributed with unknown probability density function (p.d.f) f. The kernel density estimator was introduced by Parzen (Citation1962). Let K be a kernel function on real line, and let h be a positive value called bandwidth. Then kernel density estimator of f is defined as
(1)
(1)
To make the estimator meaningful, the kernel function is usually required to satisfy conditions ,
,
and
. Note that the bandwidth
, as
. The choice of this bandwidth is very important. Several approaches are known for the choice of bandwidth in the kernel smoothing methods, via cross validation or by minimising a measure of error.
Studies are shown that the kernel density estimation of f in (Equation1(1)
(1) ) is biased. Recently, Xie and Wu (Citation2014) studied a bias reduced version of
and proved its performances comparing it to the usual methods. If the density f is twice continuously differentiable, this bias reduced estimator is given as follows
(2)
(2) The bandwidth h is the most dominant parameter in the kernel density estimator. This parameter controls the amount of smoothing and is analogous to the bandwidth in a histogram. Even though the kernel estimator depends on the kernel and the bandwidth in a rather complicated way, a graphical representation clearly illustrates the difference in importance between these two parameters, see Figure 3.3 and 2.6(a) in Wand and Jones (Citation1995). To explore the most relevant bandwidth selection methods in density estimation for complete data see the reviews of Turlach (Citation1993), Cao et al. (Citation1994), Jones et al. (Citation1996) or Mammen et al. (Citation2011) and Mammen et al. (Citation2014), and the recent work on β-divergence for Bandwidth Selection by Dhaker et al. (Citation2018).
It should be noticed that nonparametric estimation procedures have been recently applied in environmental data, e.g., Schmalensee et al. (Citation1998), Taskin and Zaim (Citation2000), Millimet and Stengos (Citation2000), and Millimet et al. (Citation2003). However, the nonparametric modelling used in this paper is for another purpose which is to study the dynamics of the entire distribution of CO2 emissions per capita.
Our aim in this paper is to propose and compare several bandwidth selection procedures for the kernel density estimator in (Equation2(2)
(2) ). The procedures we study are bandwidth selector based on the criterion of β-divergence with different β values. A simulation study is then carried out to assess the finite sample behaviour of these bandwidth selectors.
The remainder of the paper is organised as follows. In Section 2, we state our main results which presents the proposal method for bandwidth selector based on β-divergence . Section 3 gives the estimation of the optimal bandwidth selection. Section 4 is devoted to our simulation results, Section 5 applies the methods to real datasets and finally, we conclude the paper in Section 6.
2. Bandwidth selection based on β-divergence
The β-divergence (see, e.g., Basu et al., Citation1998; Cichocki et al., Citation2006; Eguchi & Kano, Citation2001) is a general framework of similarity measures induced from various statistical models, such as Poisson, Gamma, Gaussian, Inverse Gaussian and compound Poisson distribution. For the connection between the β-divergence and various statistical distributions, see Jorgensen (Citation1997). Beta divergence was proposed in Basu et al. (Citation1998) and Minami and Eguchi (Citation2002) and is defined as dissimilarity between the density function and its estimator as In the case where
, we have
Before we start our results, we introduce the following assumptions on the probability density function f and on the kernel K:
| (F1) | f is compactly supported on I. | ||||
| (F2) | f is four times continuously differentiable on I. | ||||
| (F3) |
| ||||
Proposition 2.1
Under assumptions the mean of
is given by
(3)
(3) where
is the asymptotic mean of
expressed as
(4)
(4)
For the proof of the Proposition 2.1, see appendix in Section A. The following theorem allows us to give the analytical value of bandwidth which minimises the asymptotic mean of .
Theorem 2.2
Assume that hold, then the bandwidth
that minimises
is
(5)
(5)
The proof of Theorem 2.2 is derived from Proposition 2.1. From Theorem 2.2, we deduce the particular case where of optimal bandwidth selection.
Corollary 2.3
Assuming that the assumptions in Theorem 2.2 hold. Then, we have for
with
is the asymptotic
and its corresponding optimal bandwidth is
(6)
(6) where
3. The choice of the bandwidth h
In this section, we describe bandwidth selection methods for the density estimator defined in (Equation2(2)
(2) ). These methods are adapted to common automatic selectors for kernel density estimation. We propose two selection methods a Normal reference and the cross-validation method. The Normal reference bandwidth is based on estimating the infeasible optimal expression (Equation6
(6)
(6) ), in which the unknown element is
.
3.1. Rule-of-thumb for bandwidth selection
This method is based on the rule-of-thumb for complete data (see, e.g., Silverman, Citation1986). The idea is to assume that the underlying distribution is normal, , and in this situation, we have
Proposition 3.1
If f is Normal density function with mean μ and variance then the asymptotically optimal bandwidth
in (Equation5
(5)
(5) ) becomes the normal reference bandwidth as
(7)
(7)
In the particular case where , we have
The standard deviation σ can be estimated by the sample standard deviation (S) or by the standardised interquartile range
for robustness against outliers
, but a better rule of thumb (e.g., Silverman, Citation1986, pp. 45–47; Härdle, Citation1991, p. 91) is to use
and to define the following estimator of
as
Proof: See Appendix.
3.2. Cross-Validation
The method previously defined is based on minimising estimations of the mean , more precisely of the asymptotic mean
. The least squares Cross-Validation is the most popular method and is related on the minimising procedure of the ISE (integrated squared error), i.e., the particular case of β-divergence with
(see, e.g., Bowman (Citation1984) and Rudemo (Citation1982)). As a generalisation of the ISE, we introduce a β-Divergence Cross Validation (
) method. Recall that
Since
does not depend on h, our β-Divergence Cross Validation approach is based on the minimising procedure likes the ISE method, of the following loss function:
Using the same methodology as the least squares cross-validation method we estimate
from the data and minimise it over h. Considering the following estimator of
:
with
Hence, the optimal bandwidth that minimises the estimator
is
Remark 3.1
In the preceding section three bandwidths and
were presented as possible optimal choices for density estimation. However, in practice none of them is known since they depend on the unknown parameter β. In the article Dhaker et al. (Citation2018) the authors have shown that optimal β verifies:
For a β value close to 1 we obtain optimal h obtained using the Kullback-Leibler criteria, and for beta close to 2 we obtain that of the mean integrated square error.
Remark 3.2
From Theorem 2.1 in Xie and Wu (Citation2014), we have
(8)
(8) this variance decreasing in h, while the optimal h for
is given by:
more reference see Dhaker et al. (Citation2018). The optimal
of the ordinary kernel estimator
is asymptotically inferior to the bias reduced kernel density estimator,
, since its convergence rate is
compared to the bias reduced kernel density estimator's
rate, which results in a decrease in variance (Equation8
(8)
(8) ).
4. Simulations
In this section, we evaluate the performance of the bandwidth selection procedures presented in Section 2. To this goal we have carried out a simulation study including rule-of-thumb (), the Least Squares Cross-Validation bandwidth (
) and the β-Divergence Cross Validation (
with
). Two simulation studies are carried out to evaluate different situations. First of all, as the population density, we used a normal mixture. In the second place, we used a lognormal mixture, who is a heavy-tailed distribution is subexponential.
4.1. Simulation study 1
For consideration of computation and generality, assume that the true density f is a normal mixture
(9)
(9) where
and
. One thousand Monte Carlo samples of size n are generated from the normal mixture model in Equation (Equation9
(9)
(9) ) for each combination of
. The results of our different sets of experiments are presented in Tables . The Table gives the exhibits simulated relative efficiency
of the kernel estimator, with
takes the bandwidth estimators
,
and
, it is lower than 1, because the optimal bandwidth
minimise MISE. Each bandwidth, mean
and mean relation error
are obtained, these values are given by respectively, Tables and .
For all situations, each relative efficiency
because the optimal bandwidth
The normal reference bandwidth
We have to remark that in Table ,
The bandwidth
Table 1. for normal mixture
.
Table 2. for normal mixture
.
Table 3. for normal mixture
.
Figure compare, for densities with and
, the results of the five bandwidth selection
,
and
(discussed in Section 3), relatively to the results obtained by using the MISE optimal bandwidth (
). These figures present boxplots of the ratio
, where
takes the estimators
,
and
, with
. We see the LSCV and
(with
) methods gave overall the bests ratios across all simulations, and that this ratio was rather large in general.
Figure 1. Boxplots of the relative values RE for the bandwidth selectors for the estimation of densities and
. The sample size varies from 100 to 2000.

4.2. Simulation study 2
As the populational density, we used a lognormal mixture.
(10)
(10) Where
and
, with μ and σ are the means and standard deviations, respectively. Similar to the previous subsection for each combination of n = 50, 200, 700,
, and
. For each case, Table exhibits the simulated relative efficiency RE, Tables and give the
and
corresponding each bandwidth.
A summary of the results is provided below.
Firstly, in Table showed that the REs values for and
increased as n increased and close to 1, but the performance is not so good in the case
. However
outperform others, especially
which has RE values close to 1 in all situations.
Table 4. for lognormal mixture
.
Table 5. for lognormal mixture
.
Table 6. for lognormal mixture
.
5. Real data analysis
A very natural use of density estimates is in the informal investigation of the properties of a given set of data. Density estimates can give valuable indication of such features as skewness, multimodality and heavy tail in the data. In some cases, they will yield conclusions that may then be regarded as self-evidently true, while in others all they will do is to point the way to further analysis and data collection.
Three examples of data are provided to illustrate the performance of kernel density estimation with different bandwidths, where the Gaussian kernel is used. All of them are classical examples of unimodal, bimodal distributions and heavy tail respectively.
5.1. Application 1
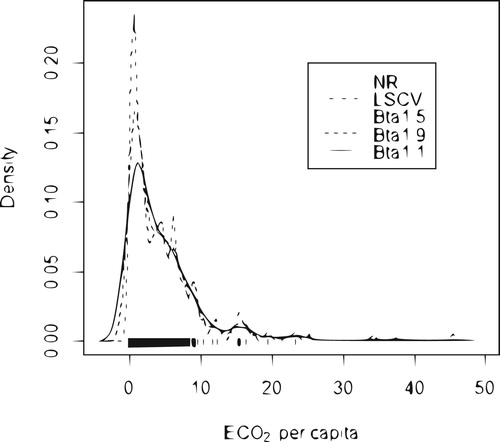
The first data set comprises the per capita in the year of 2014. This data set is available in the world bank website. Figure shows the estimated density of
per capita in the year of 2014 computing with bandwidths estimators
,
,
,
and
. The data set that the estimated density that was computed with the
and
bandwidths captures the peak that characterises the mode, while the estimated density with the bandwidths that
,
and
smoothes out this peak. This happens because the outliers at the tail of the distribution contribute to
,
and
be larger than the other bandwidths.
Figure 2. Estimated density of per capita in 2008 using the different bandwidths.
(solid line);
(dashed line);
(dotted line);
, (dotdash line) and
(longdash line).
5.2. Application 2
We use the time between eruptions set for the Old Faithful geyser in Yellowstone National Park, Wyoming, USA (107 sample data, source: Silverman, Citation1986). Figure plots the data points and the kernel density estimates for old faithful geyser data, using bandwidths ,
,
,
and
.
Figure 3. Estimated density of repair times (hours) for an airborne communication transceiver: (solid line);
(dashed line);
(dotted line);
, (dotdash line) and
, normal reference (longdash line).
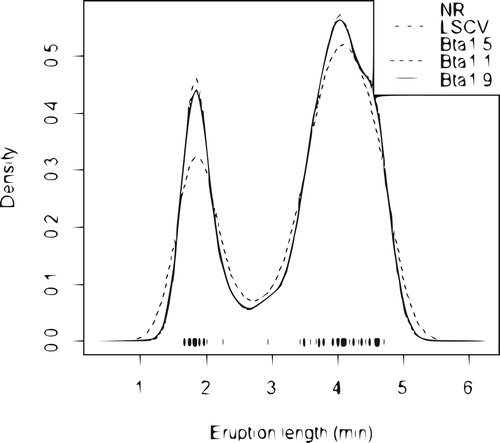
An important point to note that the density curve for eruption length is similar to bimodal normal density (normal mixture). From our Application 2, we see that the is always larger than the others bandwidths, he heavily oversmoothes its kernel density curve, underestimating the two peaks of the curve but overestimating the valley between them. About
,
and
seems to undersmooth the curve too much, overestimating the two peaks but underestimating for the valley. However
is proper bandwidth for their density estimate to be able to capture the feature of the true density curve.
5.3. Application 3
Maintenance data on 46 active repair times in hours for an airborne communication transceiver reported by Von Alven (Citation1964) have been analysed by Sultan and Al-Moisheer (Citation2015) who conclude that mixture of inverse Weibull and lognormal model was a good fit. The estimated density function of maintenance data is presented in Figure , using commonly used bandwidths ,
, as well as the newly developed bandwidth
,
and
.
Figure 4. Estimated density of repair times (hours) for an airborne communication transceiver using the different bandwidths: (solid line);
(dashed line);
(dotted line);
, (dotdash line) and
, normal reference (longdash line).
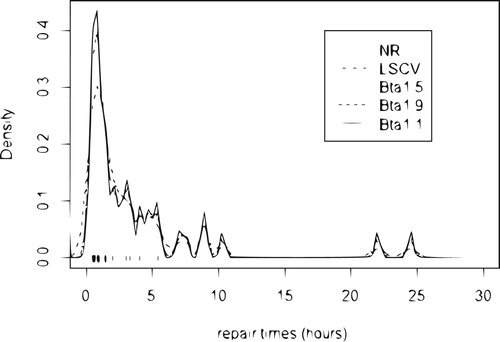
As expected, the normal reference bandwidth heavily oversmoothes its kernel density curve. It seems that
and
, especially the later, are appropriate bandwidths for their density estimates to be able to capture the feature of the true density curve.
As expected, the normal reference bandwidth heavily oversmoothes its kernel density curve. It seems that
is appropriate bandwidth for their density estimate to be able to capture the feature of the true density curve.
6. Conclusion
This paper proposed the method for bandwidth selection of bias reduction kernel density estimator, given in (Equation2(2)
(2) ). A various bandwidth selection strategies have been proposed such as normal reference
, least squares cross-validation
and the β-Divergence Cross Validation
, with
and 1.9. The normal reference bandwidth method is a simple and quick selector, but limited the practical use, since they are restricted to situations where a pre-specified family of densities is correctly selected. The least squared cross validation method do not provide a smooth density estimation, although asymptotically optimal, the finite sample behaviour of
is disappointing for its variability and undersmoothing. We have attempted to evaluate choice of the optimal bandwidth
and
, using β-divergence. Compared to traditional bandwidth selection methods designed for kernel density estimation, our proposed
bandwidth selection method is always one of the best for having large
and small
. Simulation studies showed that our proposed optimal bandwidth
method designed for kernel density estimation adapts to different situations, and out-performs other bandwidths. We conclude that the choice of the bandwidth based on the real data is consistent with the one based on simulations which is the
(
and 1.5 ) method gives us a smoother density estimation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Hamza Dhaker
Hamza Dhaker (PhD), is Assistant Professor in Probability and Statistic at the Faculty of Sciences of Université de Monctoon (Canada). His work revolves around Non-parametric Statistic, Extreme value statistic, Divergence Measures, Risk Measures.
El Hadji Deme
El Hadji Deme (PhD), is Associate Professor in Probablity and Statistic at the Faculty of Applied Sciences and Technology of Gaston Berger University in Saint-Louis (Senegal). His work revolves around Non-parametric Statistic, Extreme value statistic, Empirical process, Divergence Measures, Risk Measures (in finance and insurance), Inequality index and social well-being.
Youssou Ciss
Youssou Ciss (PhD) is Doctor of Applied Mathmatics Probabily and Statistics at the Faculty of Sciences and Technology in Gaston Berger University (Senegal). Field of work: Non parametric statistics.
References
- Basu, A., Harris, I. R., Hjort, N. L., & Jones, M. C. (1998). Robust and efficient estimation by minimising a density power divergence. Biometrika, 85(3), 549–559. https://doi.org/https://doi.org/10.1093/biomet/85.3.549
- Bowman, A. W. (1984). An alternative method of cross-validation for the smoothing of density estimates. Biometrika, 71(2), 353–360. https://doi.org/https://doi.org/10.1093/biomet/71.2.353
- Cao, R., Cuevas, A., & Gonalez-Manteiga, W. (1994). A comparative study of several smoothing methods in density estimation? Computational Statistics and Data Analysis, 17(2), 153–176. https://doi.org/https://doi.org/10.1016/0167-9473(92)00066-Z
- Cichocki, A., Zdunek, R., & Amari, S. (2006). Csiszar's divergences for nonnegative matrix factorization: Family of new algorithms. In Lecture notes in computer science (pp. 32–39). Springer.
- Dhaker, H., Ngom, P., Deme, E., & Mbodj, M. (2018). New approach for bandwidth selection in the kernel density estimation based on β-divergence. Journal of Mathematical Sciences: Advances and Applications, 51(1), 57–83. https://doi.org/10.18642/jmsaa_7100121962
- Eguchi, S., & Kano, Y. (2001). Robustifying maximum likelihood estimation (Technical Report). Institute of Statistical Mathematics, June.
- Eugene, F. S. (1969). Estimation of a probability density function and its derivatives. The Annals of Mathematical Statistics, 40(4), 1187–1195. https://doi.org/https://doi.org/10.1214/aoms/1177697495
- Härdle, W. K. (1991). Smoothing techniques: With implementation in S. Springer Science and Business Media.
- Jones, M. C., Marron, J. S., & Sheather, S. J. (1996). A brief survey of bandwidth selection for density estimation. Journal of the American Statistical Association, 91(433), 401–407. https://doi.org/https://doi.org/10.1080/01621459.1996.10476701
- Jorgensen, B. (1997). The Theory of Dispersion Models. Chapman Hall/CRC Monographs on Statistics and Applied Probability.
- Kanazawa, Y. (1993). Hellinger distance and Kullback-Leibler loss for the kernel density estimator. Statistics and Probability Letters, 18(4), 315–321. https://doi.org/https://doi.org/10.1016/0167-7152(93)90022-B
- Mammen, E., Martinez-Miranda, M. D., Nielsen, J. P., & Sperlich, S. (2011). Do-validation for kernel density estimatio? Journal of the American Statistical Association, 106(494), 651–660. https://doi.org/https://doi.org/10.1198/jasa.2011.tm08687
- Mammen, E., Martinez-Miranda, M. D., Nielsen, J. P., & Sperlich, S. (2014). Further theoretical and practical insight to the do-validated bandwidth selector. Journal of the Korean Statistical Society, 43(3), 355–365. https://doi.org/https://doi.org/10.1016/j.jkss.2013.11.001
- Millimet, D. L., List, J. A., & Stengos, T. (2003). The Environmental Kuznets Curve: Real Progress or Misspecified Models. Review of Economics and Statistics, 85(4), 1038–1047. https://doi.org/https://doi.org/10.1162/003465303772815916
- Millimet, D. L., & Stengos, T. (2000). A semiparametric approach to modelling the environmental kuznets curve across U.S. States Department of Economics working paper, Southern Methodist University.
- Minami, M., & Eguchi, S. (2002). Robust blind source separation by Beta-divergence. Neural Comput., 14(8), 1859–1886. https://doi.org/https://doi.org/10.1162/089976602760128045
- Mugdadi, A. R., & Ibrahim, A. A. (2004). A bandwidth selection for kernel density estimation of functions of random variables. Computational Statistics and Data Analysis, 47(1), 49–62. https://doi.org/https://doi.org/10.1016/j.csda.2003.10.013
- Parzen, E. (1962). On estimation of a probability density function and mode. Annals of Mathematical Statistics, 33(3), 1065–1076. https://doi.org/https://doi.org/10.1214/aoms/1177704472
- Rudemo, M. (1982). Empirical choice of histograms and kernel density estimators. Scandinavia Journal of Statistics, 9(2), 65–78.
- Schmalensee, R., Stoker, T. M., & Judson, R. A. (1998). World Carbon Dioxide Emissions, 1950–2050. The Review of Economics and Statistics, 80(1), 15–27. https://doi.org/https://doi.org/10.1162/003465398557294
- Scott, W. D. (1992). Multivariate density estimation theory, practice, and visualization. Wiley.
- Silverman, B. W. (1986). Density estimation for statistics and data analysis. Chapman and Hall.
- Sultan, K. S., & Al-Moisheer, A. S. (2015). Mixture of inverse Weibull and lognormal distributions: Properties, estimation, and illustration. Mathematical Problems in Engineering, 2015. https://doi.org/https://doi.org/10.1155/2015/526786
- Taskin, F., & Zaim, O. (2000). Searching for a Kuznets Curve in Environmental Efficiency Using Kernel Estimation. Economics Letters, 68(2), 217–223. https://doi.org/https://doi.org/10.1016/S0165-1765(00)00250-0
- Turlach, B. A. (1993). Bandwidth selection in kernel density estimation: A review (Technical Report). Universite catholique de Louvain.
- Von Alven, W. H. (Ed.). (1964). Reliability engineering. Prentice Hall.
- Wand, M. P., & Jones, M. C. (1995). Kernel smoothing. Chapman and Hall.
- Xie, X., & Wu, J. (2014). Some Improvement on Convergence Rates of Kernel Density Estimator. Applied Mathematics, 5(11), 1684–1696. https://doi.org/https://doi.org/10.4236/am.2014.511161
Appendix
Proof of Proposition 2.1
With a random variable whose expectation is 0 and variance 1, we can write
as (see Kanazawa, Citation1993),
(A1)
(A1)
Using the result of the Corollary 2.6 (Eugene, Citation1969),
we have,
Where the
terms depend upon x. Using
,
and
Proof of Proposition 3.1
so
and
In that case the asymptotically optimal bandwidth in Equation (Equation5
(5)
(5) ) becomes the normal reference bandwidth.
with σ being the standard deviation of f.
For the Gaussian kernel, and
so that
in the particular case for
(A2)
(A2) The standard deviation σ can be estimated by the sample standard deviation s or by the standardised interquartile range
for robustness against outliers
, but a better rule of thumb is (e.g., Silverman, Citation1986, pp. 45–47; Härdle, Citation1991, p. 91).
(A3)
(A3) with