
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The multi-armed bandit (MAB) problem studies the sequential decision making in the presence of uncertainty and partial feedback on rewards. Its name comes from imagining a gambler at a row of slot machines who needs to decide the best strategy on the number of times as well as the orders to play each machine. It is a classic reinforcement learning problem which is fundamental to many online learning problems. In many practical applications of the MAB, the reward distributions may change at unknown time steps and the outliers (extreme rewards) often exist. Current sequential design strategies may struggle in such cases, as they tend to infer additional change points to fit the outliers. In this paper, we propose a robust change-detection upper confidence bound (RCD-UCB) algorithm which can distinguish the real change points from the outliers in piecewise-stationary MAB settings. We show that the proposed RCD-UCB algorithm can achieve a nearly optimal regret bound on the order of , where T is the number of time steps, K is the number of arms and S is the number of stationary segments. We demonstrate its superior performance compared to some state-of-the-art algorithms in both simulation experiments and real data analysis. (See https://github.com/woaishufenke/MAB_STRF.git for the codes used in this paper.)
1. Introduction
The multi-armed bandit (MAB) problem, originally introduced by Thompson (Citation1933), studies how a decision-maker adaptively selects one from a series of alternative arms based on the historical observations of each arm and receives a reward accordingly (Lai & Robbins, Citation1985). The MAB is a fundamental problem to many online learning applications, such as the online recommendation system (Li et al., Citation2016), the dynamic spectrum access in communication system (Alaya-Feki et al., Citation2008) and the computational advertisement (Buccapatnam et al., Citation2017). A common goal of the sequential designs, i.e. the bandit algorithms, is to minimise the regret of the decision maker, where the regret refers to the expectation of the difference between the total rewards collected by playing the arm with the highest expected rewards and the total rewards obtained by the algorithms (Auer, Citation2002). To achieve this goal, decision-makers need to make a trade-off between exploring the environment to find the most profitable arms and exploiting the current empirically best arms as often as possible.
There is a rich literature studying classic MAB problems (Lattimore & Szepesvári, Citation2020), including the stochastic bandit models (Lai & Robbins, Citation1985) and the adversarial bandit models (Auer, Cesa-Bianchi, Freund et al., Citation2002). The former assumes that the reward distributions of all arms are time-invariant, and the latter assumes that the reward distributions of all arms change adversarially at all time steps. Yet, neither of these two assumptions may be realistic in many real-world applications, where the reward distributions do vary with time but much less frequently compared to what the adversarial bandit model assumes (Alaya-Feki et al., Citation2008); Yu & Mannor, Citation2009). In this paper, we focus on such piecewise-stationary MAB problems where the reward distributions are piecewise-constant and may shift at some unknown time steps called the change points; that is, we focus on MAB problems with mean changes.
In the current literature, two major approaches are proposed for the piecewise-stationary bandit problems: the passively adaptive policies and the actively adaptive policies (Liu et al., Citation2018). The passively adaptive policies adapt to the changes via adjusting the weights on the rewards. Specifically, the discounted upper confidence bound (D-UCB) algorithm discounts the weights on the old rewards and thus allocates larger weights on the recent ones when computing the UCB index of each arm (Kocsis & Szepesvári, Citation2006). The D-UCB algorithm achieves a regret bound on the order of , where T is the number of time steps, K is the number of arms and S is the number of stationary segments (Garivier & Moulines, Citation2011). Based on the D-UCB, the Sliding-Window UCB (SW-UCB) algorithm chooses only the most recent τ rewards in computing the UCB index, which achieves a regret
(Garivier & Moulines, Citation2011). Other passively adaptive policies include the EXP3.S (Auer, Cesa-Bianchi, Freund et al., Citation2002), the SHIFTBAND (Auer, Citation2002) and the Rexp3 (Besbes et al., Citation2014) algorithms.
The actively adaptive policies monitor the reward distributions by a change-detection (CD) algorithm. Their bandit algorithms will be reset once a change point is detected. The actively adaptive policies often have better performance compared to the passively adaptive policies in practice (Cao et al., Citation2019). For detecting the change points, the CUSUM-UCB algorithm (Liu et al., Citation2018) adopts the CUSUM method, and the Adapt-EvE algorithm (Hartland et al., Citation2007) and the adaptive SW-UCL algorithm (Srivastava et al., Citation2014) employ the Page-Hinkley Test (Hinkley, Citation1971). Some other available actively adaptive policies include the Bayesian CD algorithm (Mellor & Shapiro, Citation2013), the windowed mean-shift detection algorithm (Yu & Mannor, Citation2009) and the EXP3.R algorithm (Allesiardo & Féraud, Citation2015). To our best knowledge, the Monitored-UCB (M-UCB) algorithm by Cao et al. (Citation2019) is the currently most efficient method. The M-UCB achieves a nearly optimal regret bound on the order of without strong parametric assumptions, and performs very well in practical applications. In this paper, we use the M-UCB as the benchmark method.
Unexpected data changes may significantly affect the data quality, which can invalidate the classic MAB algorithms (Cao et al., Citation2019). Such data offsets may come from the trend changes or the outliers. Here an outlier means a data point with an unusually large or small value. In the current literature, most methods on non-stationary MAB problems only consider the former but ignore the latter (Allesiardo & Féraud, Citation2015). In many state-of-the-art algorithms on piecewise-stationary MAB problems (Cao et al., Citation2019; Kaufmann et al., Citation2012; Liu et al., Citation2018), once their CD algorithms identify a change point, the embedded bandit algorithms will reset the current optimal arms and try to learn new ones. Since they often cannot distinguish the real trend changes from large outliers, their CD algorithms tend to infer additional change points to fit the outliers. When there are many scattered outliers, the reset strategy adopted in these algorithms will greatly reduce their efficiency and increase the computational complexity. Specifically, the M-UCB algorithm (Cao et al., Citation2019) relies on comparing the statistical distances between data segments and the thresholds to test the significance of the trend offsets in the local data, which can be very sensitive to the outliers.
In this paper, we propose a robust change-detection upper confidence bound (RCD-UCB) algorithm which can distinguish the real change points from the outliers for non-stationary MAB problems. The proposed RCD-UCB algorithm includes a new trend offset detection using truncated loss functions to eliminate the impacts of outliers. We show that the RCD-UCB algorithm can achieve a nearly optimal regret bound on the order of for piecewise-stationary MAB problems, which is of the same order as the bound in Cao et al. (Citation2019). We demonstrate the superior performance of the RCD-UCB via three simulation studies and a real data analysis on metalwork factory machining, where the proposed algorithm can significantly reduce the cumulative regrets compared to some currently popular methods.
The remainder of this paper is organised as follows. In Section 2, we first formulate the piecewise-stationary MAB problems, then introduce the proposed RCD-UCB algorithm, and finally discuss its theoretical regret bound. In Section 3, we demonstrate the superior performance of the RCD-UCB via three simulation studies and a real data example. Section 4 concludes this work and discusses some future works. A brief description of the classic UCB1 algorithm (Auer, Cesa-Bianchi, Freund et al., Citation2002) and all proofs are relegated to the Appendix.
2. The RCD-UCB algorithm for piecewise-stationary MAB problems in the presence of outliers
2.1. Problem formulation
In an MAB problem, denote as the set of swing arms and
as the set of time slots. At each time slot
, the learning agent chooses an arm
and gets a reward
which can be generalised to any bounded interval. The reward sequence
for the arm
can be seen as a series of independent random variables from potentially different distributions. Let
be the expectation of reward
at the time slot t. Let
be the selector having the maximum expected reward at time t, i.e.
,
. The learning agent wants to make a series of right decisions about the playing arms
to maximise the expected cumulative reward, i.e.
, for the entire T time periods (Srivastava et al., Citation2014). Equivalently, it is to minimise the T-step cumulative regret (Cao et al., Citation2019):
(1)
(1) i.e., the expected total loss of playing arms
.
For the piecewise-stationary MAB scenario, define as the reward distribution of the kth selected arm at time t. The reward
is independently sampled from
, both across arms and across time slots. Here, the
can have various types, such as uniform, Bernoulli and exponential distributions. When outliers exist, unusually small or large rewards are encountered, which may come from the reward distributions with extreme probabilities or simply from collection errors.
Let S be the number of piecewise-stationary segments in the reward sequence:
where
represents the indicator function. Here, we have S−1 change points represented by
, which are defined to be the time slots that the changes occur. For notation consistency, we set
and
. Within the same segments, the rewards follow the same distributions, but among different segments, the reward distributions can be different. Similar to Liu et al. (Citation2018) and Cao et al. (Citation2019), we consider using the means to describe the trends in the non-stationary data. Let
be the mean response for the kth arm in the jth data segment where
and
. We consider the cases where there exists at least one arm
such that
(
) and
is not very small (see Assumption 2.1(b)) for detectability, which excludes infinitesimal mean shift and is a reasonable assumption in practice (Liu et al., Citation2018). There is no requirement on the shape of the reward distribution. Note that, if we set S = 1 in our framework, it becomes the classic stochastic bandit model (Besbes et al., Citation2014); if we set
, it becomes the classic adversarial bandit model (Garivier & Moulines, Citation2011).
2.2. The RCD-UCB algorithm
In this part, we propose a novel algorithm framework for piecewise-stationary MAB problems in the presence of outliers. It improves the current change-detection UCB framework by incorporating a data-driven tail truncation strategy that can distinguish the real change points from the outliers. Current popular tail truncation methods to restrict unexpected changes caused by extreme values include:
(1) Huber loss:
(2) the biweight loss:
and (3) if interest lies in changes in the uth quantile for 0<u<1:
In particular, if u = 0.5, the loss function (3) reduces to
The proposed algorithm framework can incorporate various tail truncation methods. Yet, we do not recommend to use the loss function (3) since the mean changes are of interest here. Compared to the Huber loss, our proposed algorithm with the biweight loss generally have better performance by some simulation explorations. Thus, in this paper, we focus on using the biweight loss in the change point detection, where the parameter a is determined via a data-driven approach.
In Algorithm 1, we show our robust change detection (RCD) method using the biweight loss. It considers a change point detection strategy based on comparing running sample means over a sliding window. Here, the window width w and the statistical distance threshold b are tuning parameters, which can be chosen empirically or based on the theoretical results in Section 2.3. The selected w must be even since the means of the first and second halves of the running samples () are compared. The biweight loss function bounds the absolute differences of sample means at most a, where parameter a is updated through historical data and controlled by the tuning parameter α in Algorithm 2. This simple RCD algorithm has minimum parameter specification and thus is computationally efficient.

Next, we show the proposed RCD-UCB algorithm in Algorithm 2 whose parameters mainly include the total number of time slots T, the number of arms K, the policy rotation parameter γ, the delay parameter D and the outlier truncation probability α. The tuning parameter γ controls the fraction of the uniform sampling used for feeding the RCD algorithm (line 4), which can be determined based on the theoretical results in Section 2.3. For the kth arm, let denote the upper bound for calculating the truncation distance in the biweight loss function (line 3 in Algorithm 1) and
be the list used to record the offset distances (line 15) when each detection is not significant. The tuning parameter
controls the values of
which are updated by the upper α quantiles of
. We set the tuning parameter D to guarantee that
have at least D elements before calculating the quantiles. Let τ indicate the latest moment when the change point was detected. Denote
as the number of observations of the kth arm after time τ.
Here, we briefly introduce the work flow of the RCD-UCB in Algorithm 2. At each time t, the RCD-UCB decides whether to do a uniform sampling exploration (line 4) or a UCB1 exploration (line 6), such that the fraction of time slots used for the uniform sampling is roughly γ. Note that the arms are played sequentially in the first K time slots. When calculating the UCB1 index (Auer, Cesa-Bianchi et al., Citation2002; Lattimore & Szepesvári, Citation2020), only the observations since the last detection time τ (
for the kth arm) are used (line 7). Refer to the Appendix A for some details on the UCB1 algorithm and index. Next, when the cumulative data volume
is greater than the data window width w, we adaptively perform the RCD in Algorithm 1 (line 12). If a change point is detected, the exploration will be reset (line 13); otherwise, the exploration continues and the offset distance is recorded in the list
(line 15). When
includes at least D historical non-significant offset distances, the current value of
will be updated by the
quantiles (line 17). Based on the empirical results, the tuning parameter α can be chosen from
. As α increases, the RCD-UCB becomes more robust against possibly many outliers but less sensitive for identifying change points. Our simulation experiments in Section 3 show that
(or 0.05) often gives satisfactory results.
Same as Cao et al. (Citation2019) and Liu et al. (Citation2018), we assume that the initial w-length data are stable (i.e., no change occurs) and there are reasonably many observations between the two real change points. The parameter is used to truncate the offset distances and is updated through historical data. If the current value of
is zero or smaller than the tuning parameter b, the RCD algorithm will always return to False. This situation occurs at the beginning of each exploration. As the exploration continues, we can expect
gradually increases until finding the next change point.
2.3. Theoretical results on performance analysis
In this part, we analyse the regret upper bound of the proposed RCD-UCB algorithm and specify its tuning parameters. We show the RCD-UCB can achieve a nearly optimal regret bound with the same order as the M-UCB by Cao et al. (Citation2019). Note that the M-UCB assumes no outliers.
For the kth arm on the ith piecewise-stationary data segment, we define the sub-optimal gap as the difference in expected returns between the optimal arm in
and the selected arm:
The sub-optimal gaps can be used to characterise the regret. Let
be the final truncated threshold for the kth arm at the ith change point. Define the amplitude of the change for the kth arm at the ith change point as
Assumption 2.1
The learning agent can choose w and γ such that (a) and
,
, where
, and (b)
,
such that
.
Assumption 2.1 is standard in the existing literature (Cao et al., Citation2019; Liu et al., Citation2018). Intuitively, Assumption 2.1(a) guarantees that we have reasonably many observations (larger than L) between two consecutive change points, where Algorithm 2 can select at least w + D samples from every arm to feed the RCD in Algorithm 1. Assumption 2.1(b) guarantees that at least one arm has a large enough change amplitude at each change point such that the RCD algorithm is able to detect the change quickly with limited information without affecting the false-positive rate and detection delay. We would like to remark that Assumption 2.1 is necessary for proving the theoretical results, but the RCD-UCB algorithm can still perform well in practice (though the theoretical results are not proved) when Assumption 2.1 is not satisfied. Similarly, parameter S is assumed to be known for proving the theoretical results, but the RCD-UCB can perform well with unknown S in practice.
Theorem 2.2
Let the lower bound and assume
. Under the piecewise-stationary scenario, if we run Algorithm 2 with fixed w and D,
and
, the upper bound for the regret
is
, where T is the number of time steps, K is the number of arms and S is the number of stationary segments.
The regret upper bound in Theorem 2.2 has the same order as the one in Cao et al. (Citation2019) and thus it is a nearly optimal one. Theorem 2.2 also provides guidance on the tuning parameters. Here, we set the value of to meet Assumption 2.1(b), and choose b and γ to simplify the regret upper bound in Theorem 2.2. Detailed proofs are relegated to the Appendix.
3. Experimental results
In this section, we apply the proposed RCD-UCB algorithm to three simulation experiments and a real case study where outliers may exist. We choose the currently most popular piecewise-stationary MAB method: the M-UCB algorithm (Cao et al., Citation2019) as the benchmark method. We also list the performance from other existing approaches, including the UCB1 (Auer, Cesa-Bianchi et al., Citation2002), the D-UCB (Kocsis & Szepesvári, Citation2006) and the SW-UCB (Garivier & Moulines, Citation2011) algorithms.
3.1. Simulation experiment 1
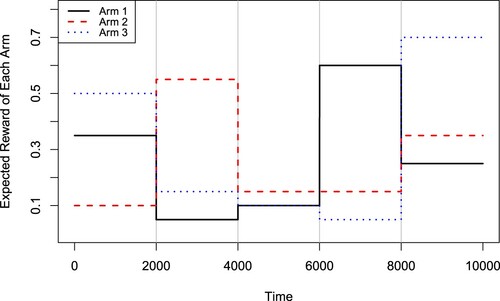
We first consider a piecewise-stationary MAB problem with K = 3 arms, T = 10000 time periods and S = 5 stationary segments (i.e. S−1 = 4 change points). We assume the change points are located evenly over the time horizon, i.e. a change occurs every 2000 time periods. The reward distributions of all arms are assumed to be normal, piecewise-stationary with randomly selected from
(
and
) and having the same standard deviation
. Figure shows the expected rewards for each arm over the time horizon. At each time step t (
), there exists a Bernoulli trial
with the probability
to decide whether to use an outlier
to replace the original reward data at the current moment. That is, the rewards received by the learning agent in this MAB problem are
(2)
(2) where
for
.
Figure 1. Expected rewards for arms in the simulation experiment 1.
We first compare the proposed RCD-UCB with the benchmark method: the M-UCB algorithm (Cao et al., Citation2019). In the RCD-UCB, we set the tuning parameter D = 200 and consider four different settings for α: 0.01, 0.025, 0.05 and 0.1. According to Theorem 2.2 in this paper and Remark 1 in Cao et al. (Citation2019), we set other tuning parameters as w = 100, and
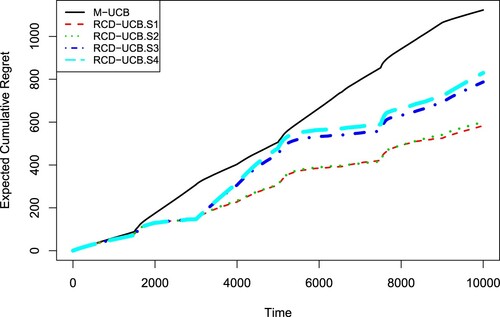
for both the RCD-UCB and the M-UCB algorithms. We replicate the simulation experiments 100 times for all algorithms and show the average results. In Figure , we display the expected cumulative regrets for the M-UCB and the four RCD-UCB policies (RCD-UCB.S1 to RCD-UCB.S4 using
and 0.1, respectively). It is seen that all the four RCD-UCB policies receive much smaller regrets than the M-UCB algorithm. These four policies perform similarly, where the RCD-UCB.S2 and RCD-UCB.S3 are slightly better in terms of the regret at the end time T .
Figure 2. Expected cumulative regrets for the M-UCB and RCD-UCB with different α values in the simulation experiment 1.
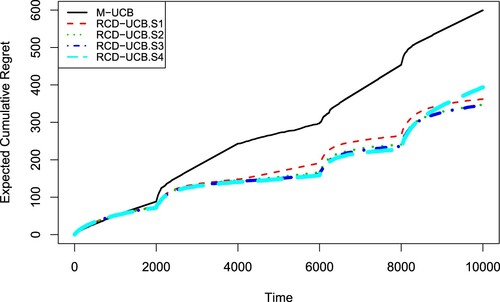
Figure 3. Expected rewards for arms in simulation experiment 2.
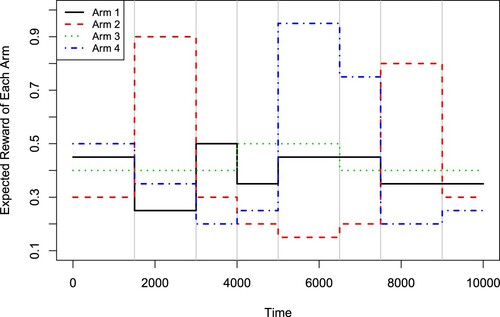
Figure 4. Expected cumulative regrets for M-UCB and RCD-UCB with different α values in the simulation experiment 2.
In Table , we list the average number of detected change points and its standard deviation for each algorithm among the 100 replications. The M-UCB declares about 7 change points, much larger than its true value of 4. When and
, the average numbers of change points detected by the RCD-UCB are close to 4, which explains the superior performance of the RCD-UCB.S2 and RCD-UCB.S3 policies. In the RCD-UCB algorithm, the number of detected change points decreases as α increases. As discussed in Section 2.2, there is a trade-off when choosing the tuning parameter α. Larger α (i.e. larger truncation probability) makes the RCD-UCB more robust towards possibly many outliers, but at the same time makes the algorithm more conservative for identifying change points.
Table 1. Average number (AVE) and standard deviation (SD) of detected change points by each algorithm in the simulation experiment 1.
In addition, we compare the RCD-UCB.S2 () with the UCB1, the D-UCB and the SW-UCB algorithms. In Table , we show the average cumulative regrets at time T and their standard deviations over 100 replications for different algorithms. According to Garivier and Moulines (Citation2011), we set
in the D-UCB and
in the SW-UCB here. From Table , we can see that the RCD-UCB gives much smaller (roughly less than a half) T-step cumulative regrets compared to the UCB1, the D-UCB and the SW-UCB algorithms. In addition, we report the average computational time (in seconds) for each algorithm in Table . All codes were run in R on a laptop with an Intel 1.60GHz I5 CPU. We can see that all algorithms are very fast for running an MAB problem with T = 10000 time periods. The RCD-UCB algorithm spends a bit more time than the other algorithms, but is still fast enough.
Table 2. Average cumulative regrets (AVE), standard deviations (SD) and computational time in seconds (TIME) for different algorithms in the simulation experiment 1.
3.2. Simulation experiment 2
Next, we consider an MAB problem whose reward distributions of all arms are assumed to be Bernoulli, where there are K = 4 arms, T = 10000 time periods and S = 9 stationary segments (i.e. 8 change points). The mean rewards of all arms are randomly selected from
(
and
). Figure shows the expected rewards for each arm over the time horizon. At each time step t
, there exists a Bernoulli trial
with probability
to decide whether we will use an outlier
to replace the original reward data at the current moment. Thus, the rewards received by the learning agent in this MAB problem are
where
for
.
We first compare the proposed RCD-UCB with the benchmark M-UCB. In the RCD-UCB, we set D = 200 and and consider four different settings for α: 0.01, 0.025, 0.05 and 0.1 which are denoted as the RCD-UCB.S1 to RCD-UCB.S4 policies, respectively. Based on Theorem 2.2 in this paper and Remark 1 in Cao et al. (Citation2019), we use w = 100, b = 12 and for both the RCD-UCB and the M-UCB algorithms. In Figure , we display the expected cumulative regrets for the M-UCB and the four RCD-UCB policies. From Figure , it is clear that all the RCD-UCB policies give smaller regrets compared to the M-UCB algorithm. Here, the RCD-UCB.S1 (
) and the RCD-UCB.S2 (
) provide the best performance. We list the average number of detected change points and its standard deviation for each algorithm over the 100 replications in Table . Note that the true number of change points here is S−1 = 8. Due to the existence of outliers, the M-UCB declares about 15 change points, which is much larger than the truth. As a comparison, the RCD-UCB.S1 (
) and the RCD-UCB.S2 (
) identify 8.76 and 7.90 change points on average, respectively, which are very close to the truth.
Table 3. Average number (AVE) and standard deviation (SD) of detected change points by each algorithm in the simulation experiment 2.
In addition, we compare the RCD-UCB.S2 () with the UCB1, the D-UCB and the SW-UCB algorithms in Table which shows the average cumulative regrets at time T, their standard deviations and the average computational time (in seconds) for different algorithms over 100 replications. Here we set
for the D-UCB and
for the SW-UCB according to Garivier and Moulines (Citation2011). From Table , it is clear that the RCD-UCB gives much smaller (nearly one half) T-step cumulative regrets compared to the other methods. The computational efficiency of each algorithm here is similar to that in the simulation experiment 1.
Table 4. Average cumulative regrets (AVE), standard deviations (SD) and average computational time in seconds (TIME) for different algorithms in the simulation experiment 2.
3.3. Simulation experiment 3
In this simulation study, we aim to show the proposed RCD-UCB algorithm can still perform well when there are no outliers. Here we consider the same MAB problem in the simulation experiment 1 except that there are no outliers ( in Equation (Equation2
(2)
(2) )). We run the RCD-UCB (
,
,
,
), M-UCB, UCB1, D-UCB and SW-UCB algorithms with the same settings of tuning parameters as those in the simulation experiment 1.
We list the average number of detected change points and its standard deviation for each of the four RCD-UCB algorithms and the M-UCB algorithm over 100 replications in Table . It is seen that the numbers of detected change points for all the five algorithms are close to the true value 4. In addition, Table shows the average cumulative regrets at time T and their standard deviations over 100 replications for all the eight algorithms. From Table , we can see that the M-UCB algorithm outperforms the UCB1, D-UCB and SW-UCB algorithms. The four RCD-UCB algorithms give similar T-step cumulative regrets as the M-UCB algorithm; while, their standard deviations are slightly larger. This meets our expectation that the proposed RCD-UCB algorithm can also provide desirable performances for cases with no outliers, though they are designed for the cases having outliers.
Table 5. Average number (AVE) and standard deviation (SD) of detected change points by each algorithm in the simulation experiment 3.
Table 6. Average cumulative regrets (AVE) and standard deviations (SD) by each algorithm in the simulation experiment 3.
3.4. A real data analysis
We consider a real data example from a metalwork factory in China, which had a task for machining a type of cold-rolled alloy products. There are several parallel production lines machining the same products. The cold-rolled alloys will be annealed, reduced, strengthened and reshaped through the production lines. The elongation rate is one of the key indexes for evaluating the quality of cold-rolled alloy products. It measures the rate of elongation at breaking under the maximum load on the alloy. Larger elongation rate is preferred. In this case study, the original data set includes the elongation rates of the cold-rolled alloys produced by K = 6 parallel production lines over a long time period . At each time t
, six cold-rolled alloys of the same type from the six production lines are available, and we want to adaptively select one from the six to use. The aim is to maximise the overall elongation rate for the selected products. If we view the elongation rates as rewards, this is an MAB problem with K = 6 arms.
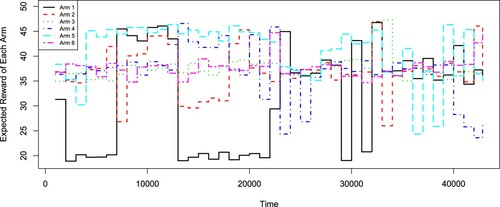
Based on the original data, we group the elongation values of every 1000 successive times for each arm. Figure shows the average rewards for each arm over the time horizon, which ranges from 18.68 to 49.98. All the six arms have non-stationary rewards and there are possibly many change points. Here, unexpected events (e.g. recording errors) may happen which will cause the rewards to be zero. Such outliers can significantly bias the detection of change points in the existing piecewise-stationary algorithms.
Figure 5. Average rewards for arms in the elongation data analysis.
For analysing this real data, we run the proposed RCD-UCB, the benchmark M-UCB, the UCB1, the D-UCB and the SW-UCB algorithms. Specifically, we set the tuning parameters w = 200, b = 80 and for the RCD-UCB and the M-UCB algorithms. Based on the simulation experiments in Sections 3.1 and 3.2, we can see
is a good choice. We set
and D = 100 in the RCD-UCB. According to Garivier and Moulines (Citation2011), we set the tuning parameters
and
for the D-UCB and SW-UCB, respectively.
Table lists the values of T-step cumulative regrets for all algorithms. It is seen that the proposed RCD-UCB method performs the best among all algorithms and it achieves a nearly 50% reduction in cumulative regrets compared to the M-UCB algorithm. The M-UCB performs slightly better than the D-UCB and SW-UCB algorithms. The UCB1 policy yields the largest regret and is much worse than the others. This is because the UCB1 does not take the non-stationary scenario into consideration. Figure further plots the cumulative regrets for the D-UCB, the SW-UCB, the M-UCB and the RCD-UCB algorithms. From Figure , we can also see that the RCD-UCB outperforms all other methods.
Figure 6. Cumulative regrets for different algorithms in the real data analysis.
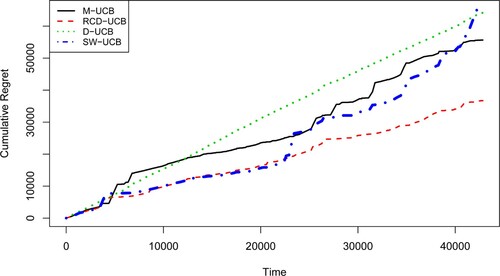
Table 7. Cumulative regrets for different algorithms in the elongation data analysis.
4. Conclusion
In this paper, we consider a general setting of piecewise-stationary MAB problems and propose a RCD-UCB algorithm that is robust to outliers. The RCD-UCB has a simple formulation and is computationally efficient in practice. It can achieve a nearly optimal regret bound on the order of under some common assumptions. Most tuning parameters in the RCD-UCB can be specified based on the theoretical results. Yet, if some prior information on the MAB (e.g. the number of piecewise-stationary segments S and the lower bound δ) is unknown in practice, the tuning parameters, including the window width w, the statistical distance threshold b, the exploration probability γ, the truncation probability α and the delay D, need to be chosen based on the practitioner's experience, which is typical in the existing literature (Cao et al., Citation2019; Liu et al., Citation2018). Specifically, larger parameter α will make the RCD-UCB more robust towards outliers, but at the same time more likely to miss real change points. Based on the simulation studies in this paper, a choice of
or 0.05 may be appropriate. Larger parameter D will lead to more stable initial estimates of truncated thresholds, but may also result in longer detection delay. As D is often much smaller than the number of observations between consecutive change points, its impact is usually small in practice. In the current works on the piecewise-stationary MAB problems (Cao et al., Citation2019; Liu et al., Citation2018), there lacks a systematic and automatic way to handle tuning parameters when no prior information is available, and it will be an interesting topic for the future research.
Acknowledgments
Wang was supported in part by NSFC (11901199 and 71931004) and Shanghai Sailing Program (19YF1412800). Zhang was supported in part by NSFC (11831008 and 11971171), the National Social Science Foundation Key Program (17ZDA091), and the 111 Project of China (B14019).
The authors thank the editor, the associate editor and the reviewers for their helpful comments.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Yaping Wang
Dr. Yaping Wang is an assistant professor in school of statistics at East China Normal University.
Zhicheng Peng
Mr. Zhicheng Peng received his master's degree in statistics from East China Normal University in 2020 and is now a researcher at the Ant Group.
Riquan Zhang
Dr. Riquan Zhang is a professor in school of statistics at East China Normal University.
Qian Xiao
Dr. Qian Xiao is an assistant professor in department of statistics at University of Georgia.
References
- Alaya-Feki, A. B. H., Moulines, E., & LeCornec, A. (2008). Dynamic spectrum access with non-stationary multi-armed bandit. In 2008 IEEE 9th Workshop on Signal Processing Advances in Wireless Communications. (pp. 416–420). IEEE.
- Allesiardo, R., & Féraud, R. (2015). Exp3 with drift detection for the switching bandit problem. In 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA) (pp. 1–7). IEEE.
- Auer, P. (2002). Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research, 3, 397–422. https://doi.org/10.5555/944919.944941
- Auer, P., Cesa-Bianchi, N., & Fischer, P. (2002). Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47, 235–256. https://doi.org/10.1023/A:1013689704352
- Auer, P., Cesa-Bianchi, N., Freund, Y., & Schapire, R. E. (2002). The nonstochastic multiarmed bandit problem. SIAM Journal on Computing, 32, 48–77. https://doi.org/10.1137/S0097539701398375
- Besbes, O., Gur, Y., & Zeevi, A. (2014). Stochastic multi-armed-bandit problem with non-stationary rewards. In Advances in Neural Information Processing Systems (pp. 199–207). MIT Press.
- Buccapatnam, S., Liu, F., Eryilmaz, A., & Shroff, N. B. (2017). Reward maximization under uncertainty: leveraging side-observations on networks. Journal of Machine Learning Research, 18, 7947–7980. https://doi.org/10.5555/3122009.3242073
- Cao, Y., Wen, Z., Kveton, B., & Xie, Y. (2019). Nearly optimal adaptive procedure with change detection for piecewise-stationary bandit. In Proceedings of Machine Learning Research (pp. 418–427). PMLR.
- Garivier, A., & Moulines, E. (2011). On upper-confidence bound policies for switching bandit problems. In International Conference on Algorithmic Learning Theory (pp. 174–188). Springer.
- Hartland, C., Baskiotis, N., Gelly, S., Sebag, M., & Teytaud, O. (2007). Change point detection and meta-bandits for online learning in dynamic environments. In CAp 2007: 9è Conférence francophone sur l'apprentissage automatique (pp. 237–250). CEPADUES.
- Hinkley, D. V. (1971). Inference about the change-point from cumulative sum tests. Biometrika, 58, 509–523. https://doi.org/10.1093/biomet/58.3.509
- Kaufmann, E., Korda, N., & Munos, R. (2012). Thompson sampling: An asymptotically optimal finite-time analysis. In International Conference on Algorithmic Learning Theory (pp. 199–213). Springer.
- Kocsis, L., & Szepesvári, C. (2006). Discounted UCB. In 2nd PASCAL Challenges Workshop (Vol. 2). http://videolectures.net/pcw06_kocsis_diu/
- Lai, T. L., & Robbins, H. (1985). Asymptotically efficient adaptive allocation rules. Advances in Applied Mathematics, 6, 4–22. https://doi.org/10.1016/0196-8858(85)90002-8
- Lattimore, T., & Szepesvári, C. (2020). Bandit algorithms. Cambridge University Press.
- Li, S., Karatzoglou, A., & Gentile, C. (2016). Collaborative filtering bandits. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 539–548). New York, NY: Association for Computing Machinery.
- Liu, F., Lee, J., & Shroff, N. (2018). A change-detection based framework for piecewise-stationary multi-armed bandit problem. In Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press.
- Mellor, J., & Shapiro, J. (2013). Thompson sampling in switching environments with Bayesian online change detection. In Artificial Intelligence and Statistics (pp. 442–450). Springer.
- Srivastava, V., Reverdy, P., & Leonard, N. E. (2014). Surveillance in an abruptly changing world via multiarmed bandits. In 53rd IEEE Conference on Decision and Control (pp. 692–697). IEEE.
- Thompson, W. R. (1933). On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25, 285–294. https://doi.org/10.1093/biomet/25.3-4.285
- Yu, J. Y., & Mannor, S. (2009). Piecewise-stationary bandit problems with side observations. In Proceedings of the 26th Annual International Conference on Machine Learning (pp. 1177–1184). New York, NY: Association for Computing Machinery.
Appendices
Appendix 1. The UCB1 Algorithm
Auer, Cesa-Bianchi, Freund et al. (Citation2002) proposed an upper confidence bound algorithm, denoted as the UCB1 policy, which becomes a step stone for MAB problems. Following the notations in Section 2.1, we describe the UCB1 policy in Algorithm 3. To balance the exploitation and exploration, the UCB1 algorithm first tries all arms once and then sequentially select the arms with the highest upper bound on its confidence interval, i.e. the UCB1 index (line 7 in Algorithm 3).
Here we briefly summarise its mathematical background. If are independent and 1-subgaussian, we have
Let the right-hand side of this equation be δ and we solve for ϵ. Then, we have
Following the notations in this paper, when the learner is deciding its action in the time slot t, a good candidate for the largest plausible estimate of the mean for the arm k is
According to Auer, Cesa-Bianchi, Freund et al. (Citation2002), a good choice for the time dependent δ is
. Thus, we have the UCB1 index for the kth arm as
. Please refer to Auer, Cesa-Bianchi, Freund et al. (Citation2002) for more details on the UCB1 algorithm.

Appendix 2.
Proof of Theorem 2.2
The basic idea of this proof follows the same line of that for classic change detection MAB algorithms. The following lemmas from Cao et al. (Citation2019) are needed and rephrased with our notations.
Lemma A.1
Regret bound in stationary scenarios
Consider a stationary scenario with S = 1, and
. Then under Algorithm 2 with parameter w, b and γ, we have that
where
is the first detection time and
Note that the RCD-UCB in Algorithm 2 is stricter than the M-UCB algorithm by Cao et al. (Citation2019) for detecting change points. The probability of raising false alarms in the stationary scenario for the RCD-UCB cannot exceed that for the M-UCB. Thus, the following Lemma A.2 (Lemma 2 of Cao et al. (Citation2019)) holds for the RCD-UCB.
Lemma A.2
Probability of raising false alarms in the stationary scenario
Consider a stationary scenario with S = 1. Then under Algorithm 2 with parameter w<T, b and γ, we have that
where
is the first detection time.
When L = w + 2D, the uniformity sampling scheme (line 4 of Algorithm 2) guarantees that each arm is sampled at least times in any time. Thus, the following Lemma A.3 (Lemma 3 of Cao et al. (Citation2019)) holds, which ensures the detection delay is no more than L/2 with a large probability.
Lemma A.3
Probability of achieving a successful detection with S = 2
Consider a stationary scenario with M = 2 and . Assume that
. For any
and
satisfying
for some
and c>0, under Algorithm 2, we have that
Lemma A.4
Expected detection delay
Consider a piecewise-stationary scenario with M = 2 and . Assume that
. For any
and
satisfying
for some
and c>0, under Algorithm 2, we have that
Based on Lemmas A.1–A.4 and Theorem 1 in Cao et al. (Citation2019), it holds that
For each
,
is a classic regret bound for the UCB1 algorithm with time length
. The term
is of order
(Cao et al., Citation2019). The term
cannot exceed
. The term
cannot exceed
and the term
is of order
. Thus the result follows.