
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper develops the empirical likelihood () inference procedure for parameters in autoregressive models with the error variances scaled by an unknown nonparametric time-varying function. Compared with existing methods based on non-parametric and semi-parametric estimation, the proposed test statistic avoids estimating the variance function, while maintaining the asymptotic chi-square distribution under the null. Simulation studies demonstrate that the proposed
procedure (a) is more stable, i.e., depending less on the change points in the error variances, and (b) gets closer to the desired confidence level, than the traditional test statistic.
1. Introduction
In the literature of the macroeconomics and financial applications, the assumption of heteroscedasticity in many time series models revealed the facts that ignoring the issue of heteroscedasticity often leads to the inefficient estimation and unreliable inference. Thus, heteroscedasticity has been focused mainly on the effect of violations of homoscedasticity, usually in two forms, ‘conditional heteroscedasticity’ and ‘unconditional heteroscedasticity’.
Non-constant volatility will be identified by ‘conditional heteroscedasticity’, when future periods of high and low volatility cannot be identified. Bollerslev (Citation1986) and Engle (Citation1982) proposed ARCH or GARCH models and provided the efficient estimation of the mean function by quasi-maximum likelihood based on other adaptive procedures. More complicated GARCH models had been proposed to allow for conditional heteroscedasticity, for instance, varying coefficient GARCH models (see Polzehl & Spokoiny, Citation2006) and spline GARCH models (see Engle & Rangel, Citation2008). The time-varying volatility is often used to describe the conditional heteroscedasticity. Drees and Starica (Citation2002) and Starica (Citation2003) made use of a non-stationary framework to analyse time series of S&P 500 returns, and found that this approach outperformed the GARCH-type models.
‘Unconditional heteroscedasticity’ will be used, when variables that have identifiable seasonal variability, such as electricity usage, are discussed. Hansen (Citation1995) considered the linear regression model with deterministically trending regressors only, in which the error is an process scaled by a continuous function of time. Nesting autoregressive model is also a special case when the conditional error variance of the model is a function of a covariate that has a form of a nearly integrated stochastic process with no deterministic drift. For the constant coefficient autoregressive model with time-varying variances (
) which will be discussed in this article, Phillips and Xu (Citation2006) utilised the ordinary least squares method and the nonparametric estimation of the variance function to provide three heteroscedasticity-robust test statistics, and proved their asymptotic standard normal distributions. Xu and Phillips (Citation2008) proposed the heteroscedasticity-robust adaptive estimation for
. Meanwhile, performances of methods in Phillips and Xu (Citation2006) and Xu and Phillips (Citation2008) relied on appropriately selecting the bandwidth used in the non-parametric function estimation.
Motivated from the ‘empirical likelihood’ () approach, this article aims to develop a test statistic which is more stable, namely, depending less on the change points in the error variances, and avoiding the problem of selecting the bandwidth. In the literature, the
approach was introduced by Owen (Citation1988), Owen (Citation1990) and Owen (Citation1991) to construct confidence intervals in a nonparametric setting, which can be seen in Owen (Citation2001). Since an
approach possesses nonparametric properties, the distribution for the data is not required to be specified, and meanwhile more efficient estimates of the parameters can be yielded. The
approach allows data to decide the shape of confidence regions without estimating the variance of the test statistic, and also is Bartlett correctable in DiCiccio et al. (Citation1991). The
approach has been applied to various situations, such as generalised linear models in Kolaczyk (Citation1994), local linear smoother in Chen and Qin (Citation2000), partially linear models in Shi and Lau (Citation2000), parametric and semi-parametric models in multi response regression in Chen and Ingrid (Citation2009); linear regression with censored data in Zhou and Li (Citation2008), plug-in estimates of nuisance parameters in estimating equations in the context of survival analysis in Li and Wang (Citation2003) and Qin and Jing (Citation2001), heteroscedastic partially linear models in Lu (Citation2009); GARCH models in Chan and Ling (Citation2006); variable selection in Han et al. (Citation2013) and Variyath and Chen (Citation2010); analysis of longitudinal data in Qiu and Wu (Citation2015). Qin and Lawless (Citation1994) linked the
with finitely many estimating equations, which served as finitely many equality constraints. To the best of our knowledge, there is no existing published work in the literature using the
approach in the constant coefficient autoregressive models with time-varying variances. This article will also consider the constant coefficient autoregressive models with time-varying innovation variance by using the
approach.
The remainder of the paper proceeds as follows. Section 2 describes the autoregressive model with time-varying variances and discusses main assumptions. Section 3 reviews the existing methods. Section 4 develops the empirical likelihood inference procedure with theoretical guarantees. Section 5 conducts simulation studies to evaluate the finite sample performance of the proposed method when compared with alternative methods. Section 6 briefly concludes. Technical details and proofs of the main results are relegated to Appendix.
2. Autoregressive model with time-varying variances
The constant coefficient autoregressive model with time-varying variances is described as follows, (1)
(1)
(2)
(2)
where
denotes transpose,
is the vector of covariates, and
is the true parameter vector of interest, with
, and the lag order p finite and known. We assume that
is a deterministic sequence of time t, satisfying
(3)
(3)
and
is a martingale difference sequence with respect to
, where
is the σ-field generated by
with
,
, for all t. Thus, the conditional variance of
is fully characterised by the multiplicative factor
in (Equation2
(2)
(2) ), i.e.,
(4)
(4)
Suppose that the data are generated from models (Equation1
(1)
(1) )–(Equation2
(2)
(2) ), and we observe a sample containing T + p observations, denoted by
. The main goals are to make inferences about the true parameter vector
in models (Equation1
(1)
(1) )–(Equation2
(2)
(2) ), i.e., testing the null hypothesis,
(5)
(5)
where
, and constructing a confidence region for
.
Section 4 will present our proposed empirical likelihood inference, after Section 3 describes the estimation methods in Phillips and Xu (Citation2006).
To facilitate the discussion of main results and comparison with related existing methods, the following conditions provided in Phillips and Xu (Citation2006); Xu and Phillips (Citation2008) are considered.
Conditions
in (Equation3
Suppose that L is the lag operator. Then
Remark 2.1
In condition (A1), the function g is integrable on the interval
Condition (A2) satisfies the stability conditions which, for a constant
Condition (A3) ensures that
3. Existing methods
Regarding the estimation of in models (Equation1
(1)
(1) )–(Equation2
(2)
(2) ), Phillips and Xu (Citation2006) reviewed the ordinary least squares (
) estimator
, and showed that under the stated conditions, as
,
(6)
(6)
where
stands for converges in distribution,
,
and
are defined as the
matrices,
(7)
(7)
is a vector of ones, and μ and Ω are as defined in Remark 2.1.
Since g is typically unknown, the asymptotic covariance matrix Λ in (Equation6(6)
(6) ) must be estimated and this can be done in several ways. First, by applying the weighted sum of squared
residuals using kernel smoothing, originally proposed by Nadaraya (Citation1964) and Watson (Citation1964) for estimation of regression functions, they proposed the consistent estimator of the function
non-parametrically for
,
(8)
(8)
where
is the
residual and the weights
,
, are defined as
(9)
(9)
where the kernel function
is assumed to satisfy
uniformly in z and
for some constant
and
;
is a bandwidth parameter depending on T. The selection of bandwidth parameter
uses the cross-validation procedure, i.e., minimises the averaged squared prediction errors (see Wong, Citation1983),
(10)
(10)
with respect to b, where
Phillips and Xu (Citation2006) suggested the following three consistent estimators of the asymptotic covariance matrix Λ when g is unknown.
The first estimator of the asymptotic covariance matrix is
The second estimator of the asymptotic covariance matrix is
The third estimator of the asymptotic covariance matrix is
Based on the above three estimators of the true covariance matrix Λ, Phillips and Xu (Citation2006) constructed three test statistics
, j = 1, 2, 3, for the true parameter vector
, stated as follows.
Lemma 3.1
Theorem 2(ii) in Phillips and Xu (Citation2006)
Assume that is the
estimator of
. Then, under the above assumptions and null hypothesis (Equation5
(5)
(5) ), it follows that
(14)
(14)
where
is the
-th element of the matrix
, j = 1, 2, 3, defined in (Equation11
(11)
(11) ), (Equation12
(12)
(12) ) and (Equation13
(13)
(13) ), respectively.
Hence, a large sample level confidence region for
based on the above Normal approximation (Equation14
(14)
(14) ) is given by
(15)
(15)
where
is the main diagonal matrix of
, j = 1, 2, 3, and
denotes the
th quantile of the chi-square distribution
with p degrees of freedom.
4. Proposed method
In terms of the practical performance of the three tests in (Equation14
(14)
(14) ), however, simulation results reveal two major issues arising from the estimation of the asymptotic covariance matrix and the selection of the bandwidth. In order to solve these problems, the proposed empirical likelihood approach will be applied to test parameters in models (Equation1
(1)
(1) )–(Equation2
(2)
(2) ).
To construct an empirical likelihood function, the estimation equations will be defined by means of,
(16)
(16)
for a generic model parameter
. According to condition (A3), we have that
holds for the true parameter vector
. Based on (Equation16
(16)
(16) ), we define the empirical likelihood for the parameter
by
By using the Lagrange multiplier, we have
where
is the solution of equations,
(17)
(17)
We also note that
, subject to constraints
and
, attains its maximum
at
. Thus, the empirical likelihood ratio at
is defined by
Taking the log transformation of the above equation, we get the corresponding empirical log-likelihood ratio,
(18)
(18)
In addition, Theorem 4.1 below provides the asymptotic null distribution of
.
Theorem 4.1
Assume that conditions (A1)–(A4) hold. Then, under the null hypothesis (Equation5(5)
(5) ), the limiting distribution of
is the chi-square distribution with p degrees of freedom, i.e.,
(19)
(19)
According to Theorem 4.1, the empirical likelihood ratio confidence interval for the true value can be constructed as follows:
(20)
(20)
where
is defined below (Equation15
(15)
(15) ). Combined with (Equation20
(20)
(20) ), Theorem 4.1 implies Corollary 4.1.
Corollary 4.1
Under the conditions of Theorem 4.1,
5. Simulation evaluation
In this section, simulation studies are conducted to compare the finite sample performance of five methods described in Sections 3–4:
Ordinary least squares without the heteroscedasticity correction (
the proposed empirical likelihood (
The zero-mean with the time-varying variance is considered as follows:
where
. The kernel function
is the standard Normal density function,
and the bandwidth parameter is selected by the cross-validation criterion (Equation10
(10)
(10) ). We consider
with known values of
.
Three kinds of the variance functions are considered in the following simulations: a single abrupt point model, two abrupt points model, continuous function variance model as follows.
Model 1: A single abrupt point model,
Model 1 corresponds to the case of a single abrupt change of the error variance from
to
at time
, where κ is the break point within the value set
. The ratio of post-break and pre-break standard deviations
is within the value set
where
.
Model 2: Two abrupt points model,
Model 2 corresponds to the case of two abrupt points model which has the change of the error variance from
to
and
to
. The time break points
take the values
;
are from the set
.
Model 3: Continuous function variance model,
Model 3 considers that the variance of the errors is the continuous function from
to
. We suppose m to be within the value set
and
within the value set
where
.
Model 1 and Model 3 are the same as in Cavaliere (Citation2004), Cavaliere and Taylor (Citation2007) and Phillips and Xu (Citation2006). Simulations are done when the parameter of interest increases on the set
, and the nominal size is
. The sample size T is from
respectively. The number of Monte Carlo replications is 5000.
Simulation results include two parts. The first part displayed in Tables , and assesses the rejection rates of five methods under the null hypothesis.
Table 1. Comparison of the rejection rates of five methods in Model 1 for ,
,
and the sample size
, based on 5000 replications.
Table 2. Comparison of the rejection rates of five methods in Model 2 for ,
,
and the sample size
, based on 5000 replications.
Table 3. Comparison of the rejection rates of five methods in Model 3 for ,
,
and the sample size
, based on 5000 replications.
The second part includes Figures – to evaluate the rejection rates of methods ,
,
,
and
as the parameter
under the alternatives increases.
Figure 1. The relationship between the rejection rates of ,
,
,
,
and the true coefficient
in Model 1
a single abrupt point model
. The abrupt point
,
. The true parameter
increases gradually from 0.1 to 0.9. (a) The sample T = 60; (b) the sample T = 200.
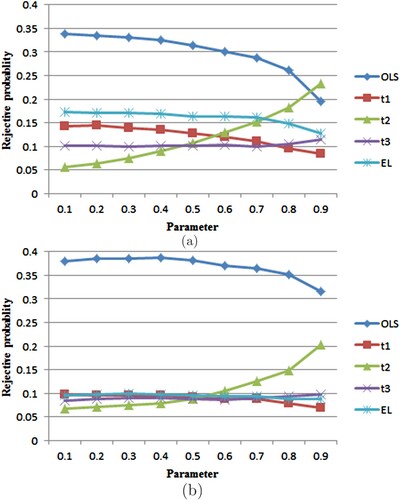
From these simulations, we draw the following conclusions.
First, the
Second, the performance of
Third, both
Figure 2. The relationship between the rejection rates of ,
,
,
,
and the true coefficient
in Model 2
two abrupt points model
. The abrupt points
,
,
. The true parameter
increases gradually from 0.1 to 0.9. (a) The sample T = 60; (b) the sample T = 200.
![Figure 2. The relationship between the rejection rates of OLS, t1, t2, t3, EL and the true coefficient β1 in Model 2 (two abrupt points model). The abrupt points κ1=0.1, κ2=0.9, [σ0,σ1,σ2]=[0.2,5,0.2]. The true parameter β1 increases gradually from 0.1 to 0.9. (a) The sample T = 60; (b) the sample T = 200.](/cms/asset/8ca5d0a9-b685-4bfa-921f-f47d8eb4c136/tstf_a_1913977_f0002_oc.jpg)
Figure 3. The relationship between the rejection rates of ,
,
,
,
corresponding to the true coefficient
in Model 3
continuous function variance model
, and m = 1,
. The true parameter
increases gradually from 0.1 to 0.9. (a) The sample T = 60; (b) the sample T = 200.
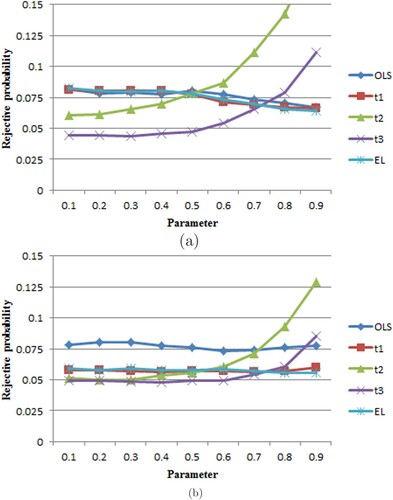
6. Conclusion
This article focuses on the empirical likelihood approach for autoregressive models with error terms scaled by an unknown nonparametric time-varying function. The empirical likelihood ratio test statistic avoids estimating the unknown variance function, in the presence of heteroscedastic error terms. The results of simulations of three different models show that the empirical likelihood is more stable than the other four test statistics. In addition, some extensions include improving the efficiency of statistic based on the different equations, and locating the abrupt time points when they exist.
Acknowledgments
The authors thank the editor, Prof. Jun Shao, and two anonymous reviewers for helpful comments. Yu Han was supported by the Scientific Research Foundation of Jilin Education (JJKH20200102KJ). The work of C. Zhang was partially supported by U.S. National Science Foundation grants DMS-2013486 and DMS-1712418, and provided by the University of Wisconsin-Madison Office of the Vice Chancellor for Research and Graduate Education with funding from the Wisconsin Alumni Research Foundation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Yu Han
Yu Han, received Ph.D. degree in mathematical statistics from Jilin University in 2012. He is currently an associate research fellow in the Educational Supervision and Evaluation Center of Northeast Electrical Power University. His current research interests are Time Series Analysis, Non-parametric and semi-parametric estimation & inference. He worked at Department of Statistics, Wisconsin University-Madison between 2013 and 2014 as a visiting scholar. He has published 12 papers. He has accomplished 3 projects as a principle investigator and as a participator. One was accomplished, and two are ongoing.
Chunming Zhang
Chunming Zhang is Professor of Statistics at the University of Wisconsin-Madison. Her research interests range from statistical learning and data mining, statistical methods with applications to imaging data, neuroinformatics and bioinformatics, multiple testing, large-scale simultaneous inference and applications, statistical methods in financial econometrics, non- and semi-parametric estimation and inference, to functional and longitudinal data analysis.
References
- Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31, 307–327. https://doi.org/https://doi.org/10.1016/0304-4076(86)90063-1
- Cavaliere, G. (2004). Unit root tests under time-varying variance shifts. Econometric Reviews, 23, 259–292. https://doi.org/https://doi.org/10.1081/ETC-200028215
- Cavaliere, G., & Taylor, A. M. R. (2007). Testing for unit roots in time series models with nonstationary volatility. Journal of Econometrics, 140(2), 919–947. https://doi.org/https://doi.org/10.1016/j.jeconom.2006.07.019
- Chan, N. H., & Ling, S. Q. (2006). Empirical likelihood for Garch models. Econometric Theory, 3, 403–428. https://doi.org/https://doi.org/10.1017/S0266466606060208
- Chen, S. X., & Ingrid, V. K. (2009). A review on empirical likelihood methods for regression. Test, 18(3), 415–447. https://doi.org/https://doi.org/10.1007/s11749-009-0159-5
- Chen, S. X., & Qin, Y. (2000). Empirical likelihood confidence intervals for local linear smoothers. Biometrika, 87, 946–953. https://doi.org/https://doi.org/10.1093/biomet/87.4.946
- DiCiccio, T., Hall, P., & Romano, J. (1991). Empirical likelihood is Bartlett-Correctable. Annals of Statistics, 19(2), 1053–1061. https://doi.org/https://doi.org/10.1214/aos/1176348137
- Drees, H., & Starica, C. (2002). A simple non-stationary model for stock returns (Working paper). Chalmers University of Technology.
- Engle, R. F. (1982). Autoregressive conditional heteroskedasticity with estimates of the variance of U.K. inflation. Econometrica, 50, 987–1008. https://doi.org/https://doi.org/10.2307/1912773
- Engle, R. F., & Rangel, J. G. (2008). The spline-GARCH model for low-frequency volatility and its global macroeconomic causes. The Review of Financial Studies, 21(3), 1187–1222. https://doi.org/https://doi.org/10.1093/rfs/hhn004
- Han, Y., Jin, Y. H., & Chen, M. (2013). Empirical likelihood-based subset selection for partially linear autoregressive models. Acta Mathematicae Applicatae Sinica, English Series, 29(4), 793–808. https://doi.org/https://doi.org/10.1007/s10255-013-0256-9
- Hansen, B. E. (1995). Regression with nonstationary volatility. Econometrica, 63, 1113–1132. https://doi.org/https://doi.org/10.2307/2171723
- Kolaczyk, E. D. (1994). Empirical likelihood for generalized linear models. Statistica Sinica, 4, 199–218. http://www3.stat.sinica.edu.tw/statistica/oldpdf/A4n111.pdf
- Li, G., & Wang, Q. H. (2003). Empirical likelihood regression analysis for right censored data. Statistica Sinica, 13, 51–68. https://www.jstor.org/stable/24307094?seq=1
- Lu, X. W. (2009). Empirical likelihood for heteroscedastic partially linear models. Journal of Multivariate Analysis, 100, 387–396. https://doi.org/https://doi.org/10.1016/j.jmva.2008.05.006
- Nadaraya, E. A. (1964). On estimating regression. Theory of Probability and Its Applications, 9(1), 141–142. https://doi.org/https://doi.org/10.1137/1109020
- Owen, A. B. (1988). Empirical likelihood ratio confidence intervals for a single functional. Biometrika, 75, 237–249. https://doi.org/https://doi.org/10.1093/biomet/75.2.237
- Owen, A. B. (1990). Empirical likelihood ratio confidence regions. Annals of Statistics, 18, 90–120. https://doi.org/https://doi.org/10.1214/aos/1176347494
- Owen, A. B. (1991). Empirical likelihood for linear models. Annals of Statistics, 19(4), 1725–1747. https://doi.org/https://doi.org/10.1214/aos/1176348368
- Owen, A. B. (2001). Empirical Likelihood. Chapman and Hall.
- Phillips, P. C. B., & Xu, K. L. (2006). Inference in autoregression under heteroskedasticity. Journal of Time Series Analysis, 27, 289–308. https://doi.org/https://doi.org/10.1111/jtsa.2006.27.issue-2
- Polzehl, J., & Spokoiny, V. (2006). Varying coefficient GARCH versus local constant volatility modeling: Comparison of predictive power (Working paper). Weierstrass Institute for Applied Analysis and Stochastics.
- Qiu, J., & Wu, L. (2015). A moving blocks empirical likelihood method for longitudinal data. Biometrics, 71, 616–624. https://doi.org/https://doi.org/10.1111/biom.12317
- Qin, G., & Jing, B. Y. (2001). Empirical likelihood for censored linear regression. Scandinavian Journal of Statistics, 28, 661–673. https://doi.org/https://doi.org/10.1111/sjos.2001.28.issue-4
- Qin, J., & Lawless, J. (1994). Empirical likelihood and general estimating equations. Annals of Statistics, 22, 300–325. https://doi.org/https://doi.org/10.1214/aos/1176325370
- Shi, J., & Lau, T. S. (2000). Empirical likelihood for partially linear models. Journal of Multivariate Analysis, 72(1), 132–148. https://doi.org/https://doi.org/10.1006/jmva.1999.1866
- Starica, C. (2003). Is GARCH (1,1) as good a model as the Nobel prize accolades would imply (Working paper). Chalmers University of Technology.
- Xu, K. L., & Phillips, P. C. B. (2008). Adaptive estimation of autroregressive models with time-varying variances. Journal of Econometrics, 142, 265–280. https://doi.org/https://doi.org/10.1016/j.jeconom.2007.06.001
- Variyath, A. M., & Chen, J. H. (2010). Abraham B. Empirical likelihood based variable selection. Journal of Statistical Planning and Inference, 140, 971–981. https://doi.org/https://doi.org/10.1016/j.jspi.2009.09.025
- Watson, G. S. (1964). Smooth regression analysis. Sankhya Series A, 26, 359–372.
- Wong, W. H. (1983). On the consistency of cross validation in kernel nonparametric regression. Annals of Statistics, 11, 1136–1141. https://doi.org/https://doi.org/10.1214/aos/1176346327
- Zhou, M., & Li, G. (2008). Empirical likelihood analysis of the Buckley-James estimator. Journal of Multivariate Analysis, 99, 649–664. https://doi.org/https://doi.org/10.1016/j.jmva.2007.02.007
Appendix. Proofs of main results
Before proving Theorem 4.1, we first show Lemmas A.1–A.2. To simplify notations, we denote and
.
Lemma A.1
Assume that conditions (A1)–(A4) hold. Then (A1)
(A1)
(A2)
(A2)
where
denotes converges in probability.
Proof.
According to Phillips and Xu (Citation2006) (Lemma 1(iii) –(iv)), the proof of Lemma A.1 completes.
Lemma A.2
Assume that conditions (A1)–(A3) hold. Then
Proof.
From (Equation17(17)
(17) ), we have
By (EquationA1
(A1)
(A1) ) of Lemma 3.1,
According to conditions (A1) and (A4), we have
for some
, and then
(A3)
(A3)
From (EquationA2
(A2)
(A2) ) of Lemma A.1 and a similar argument used in Owen (Citation1991), the proof of Lemma A.2 is completed.
Proof of Theorem 4.1.
Noticing that if is the true parameters, applying Taylor's expansion to (Equation18
(18)
(18) ), we have
(A4)
(A4)
where
, in probability, satisfies the following inequality in light of Lemma A.1 (EquationA2
(A2)
(A2) ) and Lemma A.2 for some constant C>0,
By Lemma A.1 (EquationA2
(A2)
(A2) ), Lemma A.2 and similar arguments as above, we have
(A5)
(A5)
By (Equation17
(17)
(17) ), we obtain
(A6)
(A6)
By (EquationA5
(A5)
(A5) ) and (EquationA6
(A6)
(A6) ), we obtain
(A7)
(A7)
Again by (Equation17
(17)
(17) ), we obtain
By Lemma A.1 and (EquationA3
(A3)
(A3) ), we have
Thus, we have
By substituting
of the above equation into (EquationA4
(A4)
(A4) ) and (EquationA7
(A7)
(A7) ), we have
The proof of Theorem 4.1 is completed by using Lemma A.1.