
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In Bayesian quantile smoothing spline [Thompson, P., Cai, Y., Moyeed, R., Reeve, D., & Stander, J. (2010). Bayesian nonparametric quantile regression using splines. Computational Statistics and Data Analysis, 54, 1138–1150.], a fixed-scale parameter in the asymmetric Laplace likelihood tends to result in misleading fitted curves. To solve this problem, we propose a new Bayesian quantile smoothing spline (NBQSS), which considers a random scale parameter. To begin with, we justify its objective prior options by establishing one sufficient and one necessary condition of the posterior propriety under two classes of general priors including the invariant prior for the scale component. We then develop partially collapsed Gibbs sampling to facilitate the computation. Out of a practical concern, we extend the theoretical results to NBQSS with unobserved knots. Finally, simulation studies and two real data analyses reveal three main findings. Firstly, NBQSS usually outperforms other competing curve fitting methods. Secondly, NBQSS considering unobserved knots behaves better than the NBQSS without unobserved knots in terms of estimation accuracy and precision. Thirdly, NBQSS is robust to possible outliers and could provide accurate estimation.
1. Introduction
While mean regression has been widely used in statistics, quantile regression, first proposed by Koenker and Bassett (Citation1978), is regarded as a powerful supplement of mean regression. It models the conditional quantiles of the dependent variable as a function of the covariates. There is an extensive literature on quantile regression in classic statistics from various fields including the works of Koenker (Citation2004), Chernozhukov (Citation2005), Wang et al. (Citation2007), Li and Zhu (Citation2008) and Wu and Liu (Citation2009). We recommend Koenker (Citation2005) for a comprehensive review on quantile regression. Suppose that we have N samples , the linear quantile regression model for the pth quantile is
, where
are independent with pth quantile zero. Koenker and Bassett (Citation1978) proposed to obtain the estimators of the coefficient
by solving the following minimisation
(1)
(1) where
is called a check function with
(2)
(2) From a frequentist view, the consistency and the asymptotic normality of the estimators have been well established (Koenker, Citation2005). However, the Bayesian approach is preferred when the priority is making inference with a small sample size or obtaining credible intervals for all the parameters simultaneously. Under the Bayesian framework, Yu and Moyeed (Citation2001) assumed that the distribution of error term
follows the asymmetric Laplace distribution (ALD). This choice has received tremendous attention for its guaranteed posterior consistency of Bayesian estimators (Sriram et al., Citation2013) and robustness (Yu & Moyeed, Citation2001) even if the random errors do not follow ALD. The density of ALD with location parameter
, scale parameter
and pth quantile, ALD
, is
(3)
(3) With ALD, the likelihood function of
is
(4)
(4)
Clearly, with a constant prior on , the posterior mode of
given σ is the minimiser of (Equation1
(1)
(1) ).
Notice that (Equation4(4)
(4) ) is based on a linear relationship between the response variable and a set of predictors. In reality, the underlying relationship between univariate covariate x and y may be a nonlinear function
. In the discussion of Cole (Citation1988) and Jone (Citation1988) proposed to estimate quantile smoothing spline by
(5)
(5) where
controls the smoothness of the spline. Koenker et al. (Citation1994) pointed out that the resulting quadratic program in (Equation5
(5)
(5) ) poses some serious computational issues and they estimated
by minimising
(6)
(6) where
belongs to the space
defined as follows,
(7)
(7) They showed that the solution is the linear spline with the knots at
and the computation enjoys linear programming virtues. However, the frequentist approaches cannot easily provide uncertainty evaluations for the estimation of
or a stable estimator of η. From a Bayesian perspective, Thompson et al. (Citation2010) proposed original Bayesian quantile smoothing spline to solve (Equation5
(5)
(5) ). Using ALD in (Equation3
(3)
(3) ) with
serving as the likelihood, they imposed the prior on
(8)
(8) where
is a smoothing matrix (See Section 2) and
are the inverse of N−2 non-zero eigenvalues of
. However, two undesirable issues exist in this method. Firstly, as demonstrated by Santos and Bolfarine (Citation2016), the likelihood with σ fixed is not flexible enough to capture the variability of the data, especially when p is away from 0.5, which leads to inaccurate estimates. Secondly, worse still, our extensive simulation studies and one real data example (Section 4) show that this method automatically poses either an extremely large or small value on η, hence the resulting curve tends to either too flat or overly fitted and fails to capture the true trend of the underlying curve.
One natural consideration to alleviate this problem is employing a random σ instead of a fixed value. We probe this option for Bayesian quantile smoothing spline using the likelihood (Equation4(4)
(4) ) and we refer to this option as the new Bayesian quantile smoothing spline (NBQSS). In fact, a random σ has been studied in other Bayesian quantile curve fitting methods. For instance, Yue and Rue (Citation2011) proposed Bayesian quantile regression for additive mixed models. Hu et al. (Citation2015) established semiparametric Bayesian quantile regression for partially linear additive models. However, they all employed the proper conjugate prior on scale parameter, which is not favourable when little information is available. In this paper, we explore the objective prior for the scale parameter σ and investigate the posterior propriety of the joint posterior with one general type prior including the invariant prior on σ. We also develop the partially collapsed Gibbs sampling algorithm for the joint posterior. Furthermore, to deal with the unobserved knots in some intervals, we extend our framework to the unobserved knots case seamlessly.
The remainder of paper is organised as follows. In Section 2, we present NBQSS and establish the corresponding conditions of posterior propriety under two common prior specifications. We also develop the related ready-to-use partially collapsed Gibbs sampling. In Section 3, we extend our conclusions to the case with unobserved knots out of practical consideration. In Section 4, to evaluate the performance of our method, we compare NBQSS with the other four competing curve fitting methods through extensive simulation studies. In addition, in the case of the unobserved knots, we investigate the behaviour of NBQSS under two unobserved mechanisms. In Section 5, we conclude with highlights in this paper, recommendations for the priors and research priorities in the future.
2. Bayesian quantile smoothing spline
2.1. Prior specification and posterior propriety
We formally address the minimisation (Equation5(5)
(5) ). To be more specific, we assume the knots
are arranged in an increasing order,
. Suppose that
is the number of observations at the knot
,
with
and
is the jth observation at
,
. Then, (Equation5
(5)
(5) ) can be rewritten as
(9)
(9) where
. The solution to (Equation9
(9)
(9) ) is the natural cubic spline and the knots are
(Koenker et al., Citation1994; Wahba, Citation1990). Therefore, solving (Equation9
(9)
(9) ) is equivalent to solving
(10)
(10) where
is a
positive matrix with
element
and
is a reproducing kernel (Gu, Citation2013) with the following form,
(11)
(11) where
,
,
and
is the penalty term corresponding to
in (Equation9
(9)
(9) ).
To handle the minimisation in (Equation10(10)
(10) ) under the Bayesian framework, we assume the likelihood of
based on
is
(12)
(12) Define
, we assign the prior for
to be
(13)
(13) Note that with the likelihood (Equation12
(12)
(12) ) and the prior (Equation13
(13)
(13) ), the posterior mode of
is the solution to (Equation10
(10)
(10) ).
As our primary interest lies in the fitted curves instead of the estimation of , inspired by Speckman and Sun (Citation2003), we alternatively unify the prior of
as the prior of the unknown functional value,
. Here, we denote
then the likelihood (Equation12
(12)
(12) ) can be written in the following way,
(14)
(14) where
and
Notice that the reparameterisation reduces the number of parameters in the model.
Utilising (Equation13(13)
(13) ) and the relationship between
and
, we can obtain that the prior distribution of
is a partial information normal prior (PIN) (Speckman & Sun, Citation2003) with density,
(15)
(15)
where is a positive semi-definite matrix with rank n−2 and
is the product of the positive eigenvalues of
. According to Sun et al. (Citation1999), PIN can be interpreted as two parts, a constant prior on the null space of
and a proper multivariate normal prior on the range of
.
For the fully Bayesian analysis, one common prior of is the independent conjugate priors as follows,
(16)
(16) (Equation16
(16)
(16) ) has been widely used in Bayesian P-spline (Lang & Brezger, Citation2004) and Bayesian hierarchical linear mixed models (Hobert & Casella, Citation1996). Lang and Brezger (Citation2004) suggested the invariant prior (
) on σ,
and
is a small quantity (such as
). However, there are two undesirable issues for introducing this specification in NBQSS. To start with, the posterior estimates may be sensitive to the choice of hyperparameter
(see Section 4). More importantly, the joint posterior could be improper in some important cases. To demonstrate this point, we allow
to be the real and
to be nonnegative so that some limiting cases of Gamma priors such as the invariant prior could be included. With the likelihood (Equation14
(14)
(14) ), priors (Equation15
(15)
(15) ) and (Equation16
(16)
(16) ), the following theorem establishes the corresponding sufficient and necessary conditions for posterior propriety.
Theorem 2.1
Define , the posterior of
is proper if Conditions A, B and C hold.
Condition A. One of the following holds:
.
Condition B. One of the following holds:
Condition C.
By Theorem 2.1, the posterior of does not exist for
and SSE = 0 or equivalently each
corresponds to only one observation, since Condition (B2) in Theorem 2.1 is violated.
To overcome deficiencies in (Equation16(16)
(16) ), instead of
, we could consider priors on σ and the smoothing parameter
. To include a slightly more general class of independent priors of
, we specify
(17)
(17) where
is fixed and
is one general prior for η. This idea of using prior
rather than
is actually motivated by the prior in Bayesian additive smoothing splines (Sun & Speckman, Citation2008). With the likelihood (Equation14
(14)
(14) ), the priors (Equation15
(15)
(15) ) and (Equation17
(17)
(17) ), we have the following theorem.
Theorem 2.2
We have the following two cases,
Under the priors (Equation15
When SSE>0, suppose there exist L>0, b>0 such that
Theorem 2.2 establishes the sufficient condition for the posterior propriety of the joint posterior. Based on Theorem 2.2(a), when we use the invariant prior for σ , despite of SSE = 0 or
, the joint posterior is proper when
is proper and there are at least three knots. When SSE>0, Theorem 2.2(b) allows an improper prior on η. With a small quantity on a and b, for example a = 0 and b = 0.01, the joint posterior is proper when there are at least three knots and four total observations. For the necessary condition, we have the following theorem.
Theorem 2.3
Necessary condition
When SSE = 0, the necessary condition for the propriety of joint posterior is n>2 + a and there exists a positive ϵ such that
(19)
(19)
By Theorem 2.2(a) and 2.3, when SSE = 0 and the invariant prior is imposed on σ , a proper
is sufficient and necessary condition for the propriety of joint posterior
.
Remark 2.1
When SSE = 0 and a = 0, the condition for the posterior propriety is the same as the case in the Bayesian smoothing spline (Tong et al., Citation2018).
Here, we imposed the invariant prior on σ for an objective purpose. At last, we need to specify a prior for η to complete the fully Bayesian analysis. In accordance with Theorem 2.2, when the invariant prior is used for σ, we need a proper prior for η to ensure a proper joint posterior. We adopt the scaled Pareto prior for η,
(20)
(20) In point of fact, (Equation20
(20)
(20) ) has been widely used in Bayesian smoothing spline (Cheng & Speckman, Citation2012; Tong et al., Citation2018) due to its heavy tail and straightforward explanation of hyperparameter c, which is the median of this distribution. Furthermore, (Equation20
(20)
(20) ) is equivalent to the hierarchical structure below
(21)
(21) where s is the latent variable. This hierarchical structure offers computation benefits by the resulting conjugacy of the full conditional distribution of η. For the choice of the hyperparameter c, we select c to be the tuned smoothing parameter
by generalised approximate cross-validation (GACV) (Yuan, Citation2006). The sensitivity test of hyperparameters c suggests the fitted curves are quite robust to the choice of c (see Section 4).
2.2. Partially collapsed gibbs sampling
To facilitate the Gibbs sampling involving ALD, we decomposed ALD as a mixture of an exponential and a scaled normal distribution (Kozumi & Kobayashi, Citation2011). To be specific, if Y is distributed as ,
(22)
(22) where
, ν and z are independent. This representation allows us to express the quantile regression model as the normal regression with the latent variable ν distributed as exponential. Incorporating the latent variables s and
through (Equation21
(21)
(21) ) and (Equation22
(22)
(22) ), we can obtain the full conditional distributions of the unknown parameter including latent variables. We further applied partially collapsed Gibbs sampling (van Dyk & Park, Citation2008) by marginalising the latent variable
in
to achieve a better mixing property. The sampling procedure for the joint distribution of
is as follows.
Sample σ from
Sample
Sample η from
Sample s from
The density of
3. Smoothing spline with unobserved knots
In practice, it is crucial to consider situations where knots may be unobserved in several intervals but we are interested in the fitted values at some given knots. Here, the unobserved knots refer to the case where there is no observation at the knots. This situation is common. For instance, in the bond transaction data, the trading data for the short term is more abundant due to its good fluidity than the long term. However, we still need to know some fitted values at key knots without observations in the long term. Notice that a regular NBQSS could provide the whole fitted curve based on the observed knots and hence obtain an estimate for any given knot, including the unobserved. In contrast, in this section, we directly incorporate the functional values at the unobserved knots as unknown parameters into the model. Therefore, it is feasible to borrow the information from observed knots. It is within our expectation that NBQSS with unobserved knots exhibits less uncertainty compared with a regular NBQSS and give a better prediction at unobserved knots. We prespecified position and the number of the unobserved knots. Admittedly, the choice for optimal locations or the number of added knots remains a challenging problem but it is beyond the scope of our paper.
Consider as the complete knots, assume that there are m unobserved knots, say
in
and the rest observed knots are marked as
. We still assume that there exist
observations at
,
and
.
Notice that one nice aspect of the priors associated with smoothing spline is that they extend naturally to for arbitrary unobserved knots (Nychka, Citation2000). Therefore, we introduce the incidence matrix, denoted as
, to the likelihood of
with kernel
(23)
(23) where
is the unknown functional value at the knots
and
corresponds to the knots
.
and
is positive when
corresponds to the observed knot, zero otherwise.
is utilised to indicate the corresponding response variable for
. For an intuitive understanding, we provide an illustration for
. Suppose there are three knots
, there are 2 observations at
, 2 observations at
, and no observation at
. Then,
is
and
.
The following theorem establishes the posterior propriety for NBQSS with unobserved knots.
Theorem 3.1
Under the likelihood (Equation23(23)
(23) ) and PIN prior (Equation15
(15)
(15) ) on
, the conditional posterior of
or
after integrating
has the same structure as the case where there is no additional knot.
By Theorem 3.1, it follows immediately that, if we specify the prior for or
, the conditions for posterior propriety of the joint posterior of all the parameters is the same as the regular NBQSS.
4. Numerical analysis
4.1. Sensitivity analyses of the hyperparameters
In this section, we perform the sensitivity analyses in NBQSS with respect to its two candidate prior specifications including the Gamma prior (Equation16(16)
(16) ) for δ and the scaled Pareto prior (Equation20
(20)
(20) ) for η. Assume the data are generated from
(24)
(24) with
(25)
(25) We equally divide
into 50 pieces and the knots are
. For the knots
, we generate one observation. For the knot
, we generate 2 observations to ensure the existence of the posterior of
. The function (Equation25
(25)
(25) ) is also utilised by Jullion and Lambert (Citation2007) to check the sensitivity of the hyperparameter for Gamma prior in Bayesian P-spline. In Figure , we may find that the fitted curves fluctuate a lot to the choice of the hyperparameter
in Gamma prior (Equation16
(16)
(16) ) while they are quite robust to the choice of c in the scaled Pareto prior (Equation20
(20)
(20) ). Additionally, we compare the estimation performances using Gamma prior for δ with the scaled Pareto prior for η by integrated square error (ISE) defined as,
(26)
(26) A smaller ISE indicates a better estimation for
. The results are summarised in Table . From Table , we may find using scaled Pareto prior for η outperforms Gamma prior for δ, especially when the hyperparameter is chosen small.
Figure 1. The curves are fitted when p = 0.5 and the true curves are the solid lines. Graph (a): Gamma prior, Ga(), for δ with
and
(dash-dotted),
(dotted),
(dashed); Graph (b): Scaled Pareto prior for η with c = 0.05 (dash-dotted), c = 0.1 (dashed) and c = 0.5 (dotted).
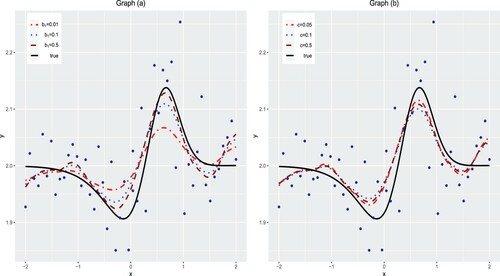
Table 1. ISEs for Gamma prior on δ and scaled Pareto prior on η.
4.2. Comparsion studies
Our comparison studies are conducted from two perspectives. For one thing, we evaluate the performance of our method by comparing with other four popular competing methods. For another, we investigate how the proposed method works when there are unobserved knots. We generate the data by,
(27)
(27) where
is a prespecified function and
is the tuning number to ensure the pth quantile zero. We consider the following three distributions for the error term:
Normal distribution, N
ALD
Cauchy distribution with the location parameter 0 and the scale parameter 0.013, C
Given a quantile p and an error distribution above, we simulate 200 datasets. Within each dataset, we split it into one training dataset and one validation dataset. For the training dataset, we equally divide (0,1) into 20 spaces and simulate 5 observations at each knot. For the validation dataset, we equally divide (0,1) into 30 spaces and generate one observation at each knot. The validation dataset is employed to obtain the optimal regularisation parameter. We compare the different procedures by median of integrated absolute error (MIAE) and median of integrated square error (MISE),
where median is taken over 200 simulation studies.
4.2.1. Comparison with candidate approaches
The Monte Carlo method is used to compare our method with other approaches including,
New Bayesian quantile smoothing spline (NBQSS);
Original Bayesian quantile smoothing spline (OBQSS) (Thompson et al., Citation2010);
Quantile smoothing spline (QSS) (Koenker et al., Citation1994);
Bayesian smoothing spline (BSS) (Tong et al., Citation2018);
Smoothing spline (SS) (Wahba, Citation1990).
We generate the data by (Equation27(27)
(27) ) with the following two underlying curves
(28)
(28)
(29)
(29) The underlying Curve I is monotone and Curve II is a little bit twisted. For the smoothing parameter η in NBQSS, we adopt the scaled Pareto prior (Equation20
(20)
(20) ) and the hyperparameter is chosen by GACV. For the smoothing parameter η in OBQSS, a Gamma
prior is utilised and its hyperparamters are selected in accordance with Thompson et al. (Citation2010)'s suggestion. Specifically,
(mean spline) and
(mean spline)
, where GCV(mean spline) is the value of η chosen by the generalised cross-validation (Craven & Wahba, Citation1978). The numerical results for Curves I and II are listed in Tables and , respectively.
Table 2. MIAEs and MISEs for Curve I with p = 0.1, 0.3 and 0.5.
Table 3. MIAEs and MISEs for Curve II with p = 0.1, 0.3 and 0.5.
From Tables and , NBQSS uniformly outperforms OBQSS, which indicates our method serves as an efficient improvement over the original method. Among three quantile methods (NBQSS, OBQSS and QSS), NBQSS performs best with the lowest MIAE and MISE in 8 out of 9 comparisons. However, when the error is the normal distribution, two mean regression methods (BSS and SS) perform better than three quantile regression methods with lower MIAE and MISE. In contrast, when the error is the ALD or the Cauchy, two quantile approaches (NBQSS and QSS) have better performances for all the selected quantiles. In addition, OBQSS has the worst performance among the five candidate methods no matter which quantiles or random errors are used. Also, OBQSS tends to perform worse as p is away from 0.5, which echoes the findings in Santos and Bolfarine (Citation2016). Although a similar trend appears in all quantile methods, compared with other candidate models, our method still shows considerable advantages.
We also demonstrate the behaviours of fitted curves for Curves I and II with ALD error and p = 0.3. In the 200 simulation studies, we can obtain the fitted value for any point . We treated the median of the 200 simulation studies at the point x as the estimation and draw the fitted curves in Figures and . We also plot the pointwise empirical 2.5% and 97.5% quantiles of the 200 estimates to display the variability in estimation.
Figure 2. The curves are fitted for Curve I under p = 0.3 and ALD error. Graph (a) NBQSS method; Graph (b) OBQSS method; Graph (c) QSS method; Graph (d) BSS method; Graph (e) SS method. The solid lines are the true curve and the fitted curve. Two dashed lines are 2.5% and 97.5% pointwise empirical quantiles.
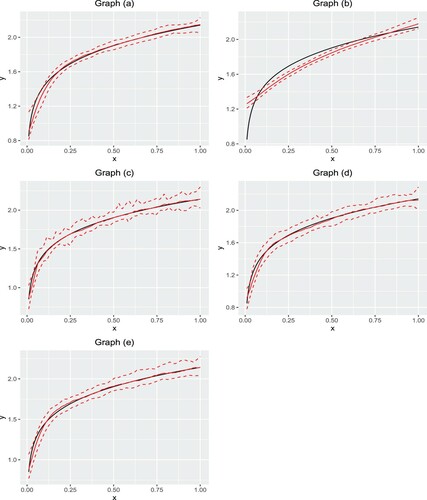
Figure 3. The curves are fitted for Curve II under p = 0.3 and ALD error. Graph (a) NBQSS method; Graph (b) OBQSS method; Graph (c) QSS method; Graph (d) BSS method; Graph (e) SS method. The solid lines are the true curve and the fitted curve. Two dashed lines are 2.5% and 97.5% pointwise empirical quantiles.
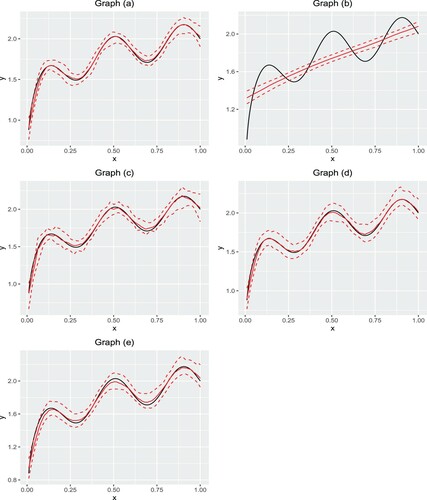
From Figures and , we may find that OBQSS tends to give a relatively flat curve, which fails to capture the true trend in the curve, especially when the curve is twisted. Based on our experience, in this case, OBQSS chooses large values for η, which results in a flat fitted curve. For example, for Curve I with p = 0.3 and ALD distributed random errors, the posterior median of η in NBQSS is 0.004 while in OBQSS is 1.135. This phenomenon requires further investigation.
4.2.2. Comparison of NBQSS with and without unobserved knots
We investigate how NBQSS performs with unobserved knots. We generate the data by (Equation27(27)
(27) ) with the underlying curve
(30)
(30) We equally divide (0,1) into 20 spaces and regard it as the complete knots. Two representative unobserved knots mechanisms are considered,
Mechanism I: α% of the complete knots are unobserved in the middle.
Mechanism II: two knots around 0.5 have observations and
We take 30%, 50% and 70% to represent low, medium and high unobserved proportion. For each observed knot, we randomly generate 5 observations. We illustrate the above two mechanisms in Figure . We implement the regular NBQSS (without unobserved knots) and NBQSS with unobserved knots (we refer it to NBQSSK, ‘K’ is for knot). For Mechanism I, we add 6 uniformly distributed knots in total for the interval without knots. For Mechanism II, we add 3 uniformly distributed knots in each of two intervals without knots, hence 6 unobserved knots in total. We consider p = 0.1, 0.5 and 0.9. MIAEs and MISEs are recorded in Tables and .
Figure 4. One illustration for Mechanisms I and II. Graphs (a)–(c) correspond to Mechanism I with and 70%. Graphs (d) and (e) correspond to Mechanism II with
30%, 50% and 70%.
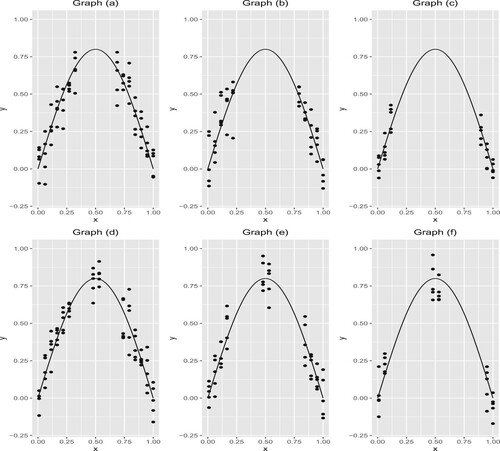
Table 4. MIAEs and MISEs for Mechanism I with quantiles p = 0.1, 0.5, 0.9 and unobserved proportions .
Table 5. MIAEs and MISEs for Mechanism II with quantiles p = 0.1, 0.5, 0.9 and unobserved proportions .
In Tables and , we may find two similarities for NBQSS and NBQSSK. Firstly, as α increases, the prediction errors increase for two methods. Secondly, both methods perform the best for p = 0.5 compared with other selected quantiles. In addition, based on Tables and , for brevity, Table summarises the percentage where NBQSSK outperforms NBQSS in each cell across different combinations of unobserved proportions and error distributions. From Table , we may find that NBQSSK defeats NBQSS in all the scenarios, especially for a large α, which substantiates that NBQSSK can provide the better prediction compared with regular NBQSS.
Table 6. Summary of cases where NBQSSK outperforms NBQSS.
Furthermore, to offer a more intuitive comparison of NBQSS and NBQSSK, we present the fitted curves and their empirical 95% credible intervals with quantile p = 0.1, ALD random error for Mechanisms I and II setting the unobserved proportion =50% and 70%. From Figure , we have several main findings. Firstly, NBQSSK performs similarly compared with NBQSS in the interval with observed knots. Secondly, two methods provide wider empirical credible intervals for Mechanism I than Mechanism II. It implies that the uncertainty surges when there is no guided information in the middle. Thirdly, for Mechanism I, the empirical 95% credible intervals of the NBQSSK are shorter than the NBQSS, especially in the middle interval. It reveals that NBQSSK can provide a more efficient uncertainty evaluation for the unobserved knots. However, the advantage of NBQSSK is less obvious for Mechanism II. Besides, for Mechanism I, NBQSSK is more advantageous than NBQSS when the unobserved proportion
compared with
, which echoes our findings in Tables and . At last, for Mechanism I or II, compared with
,
has wider empirical 95% credible interval widths.
Figure 5. The solid lines are the true curve and fitted curves. The curves are fitted with p = 0.1, ALD random error. Dashed lines are empirical 95% credible interval corresponding to NBQSSK and dotted lines are empirical 95% credible interval corresponding to NBQSS. Graph (a): Mechanism I, ; Graph (b): corresponds to Mechanism II,
; Graph (c): Mechanism I,
; Graph (d): Mechanism II,
.
Remark 4.1
Notice that the above simulation studies are based on 5 observations at each observed knot. In fact, we have also conducted simulation studies with unequal number of observations at each observed knot. The main findings are similar to Tables and . This implies that the relative performance of NBQSSK and NBQSS is irrespective of the number of observations at each observed knot.
4.3. Real dataset
4.3.1. Motorcycle dataset
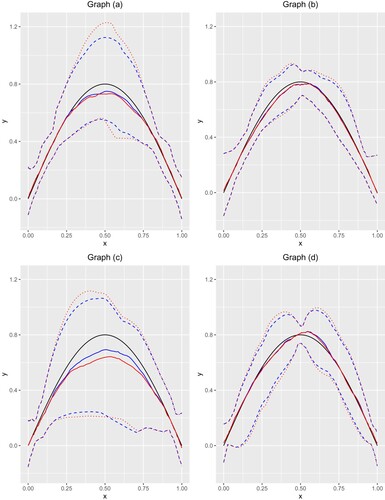
We analysed the well-known data utilised by Silverman (Citation1985) to demonstrate nonparametric regression curve fitting. It has been frequently used to motivate and demonstrate the spline-based methodology, since the underlying curve makes polynomial modelling inappropriate. There are 113 observations in the data including accelerometer readings taken through time in an experiment on the efficacy of crash helmet. For NBQSS, we fit the quantile curves with p = 0.1, 0.5 and 0.9. To assess their performances, we fit the median curve with OBQSS and the mean curves with BSS and SS. Figure shows the fitted curves of these methods. In Graph (a), with p = 0.5, NBQSS captures the general trend. With more quantiles, NBQSS offers an overview of the distribution. Interestingly, in Graph (b), the curve fitted using OBQSS is jittering very much, which tends to overfit. Similar results can be found in OBQSS when p = 0.1 and 0.9 (not shown here). Compared with NBQSS, the estimation of smoothing parameter is while is 0.068 in NBQSS. Compared with two mean curve fitting methods, we record the median of absolute deviation (MAD) defined as
(31)
(31) for each method. The MAD for NBQSS with p = 0.5, BSS and SS is 8.755, 12.979 and 13.02781, respectively. It indicates that the median curve fitted by NBQSS are relatively robust to the points with big deviation compared with mean curve fitting methods.
Figure 6. Graph (a): NBQSS method with p = 0.1, 0.5 and 0.9; Graph (b): OBQSS method with p = 0.5; Graph (c): BSS method; Graph (d): SS method.
4.3.2. China bond medium term note
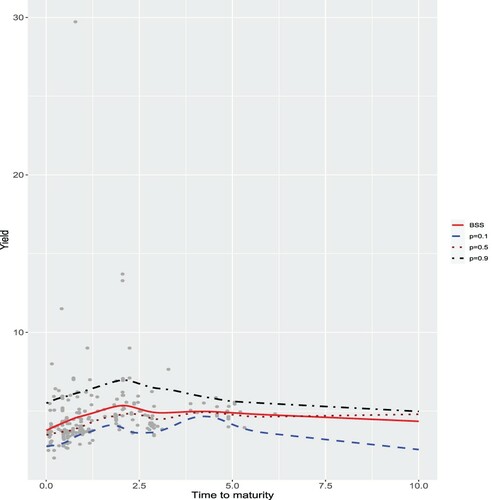
The term structure of interest rates is the series of interest rates ordered by time to maturity at a given time. It is a fundamental concept in economic and financial theory such as fixed-income securities analysis, pricing derivatives, performing hedging operations, etc. The ‘term structure of interest rates’ is also known as a yield curve. In financial markets, there are a limited number of bonds traded, so an interpolation method is necessary to estimate the yield cuvre across the whole maturity spectrum. Tong et al. (Citation2018) employed the BSS to fit China bond yield curve and the simulation studies show that BSS outperforms the traditional yield curve fitting methods such as Nelson-Siegel model (Nelson & Siegel, Citation1987) and Svensson extension model (Svensson, Citation1994). However, when fitting the yield curve for China Bond Medium Term Note (CBMTN), which is one kind of bond issued by corporation or company to collect the capital, there always exist some underlying outliers disturbing the signals. In comparison to BSS, we employ NBQSS to obtain the quantile curves for CBMTN. The data set is downloaded from Wind (https://www.wind.com.cn/). This analysis focuses on the yield curve of CBMTN rating ‘CAAA’ on 25 September 2018, which is the highest rating of this bond and associated with lowest yield but lowest risk. There are 282 transaction data in CBMTN and there exist some obvious abnormal transactions in the data. Figure shows us the NBQSS curves for p = 0.1, 0.5 and 0.9 along with BSS curve. The transaction data are marked as grey points. We may find that the BSS curve is overall lifted up by the outliers compared with the NBQSS using p = 0.5, especially when the time to maturity belongs to [0,5]. The results imply that the quantile curves using NBQSS are robust to the possible outliers while BSS is not. In addition, we record MAD for NBQSS with p = 0.5 and BSS. The MAD for NBQSS with p = 0.5 is 0.451 and for BSS is 0.79, which indicates that NBQSS provides more accurate estimation compared with BSS.
Figure 7. BSS curve (solid) and NBQSS with 0.1 (dashed), 0.5 (dotted) and 0.9 (dotted-dash) curves on 25 September 2018.
5. Comments
In this paper, we numerically demonstrate the issue associated with a fixed σ in OBQSS. To serve as a solution, we systematically investigate NBQSS with a random scale parameter. We establish conditions for the posterior propriety of the NBQSS under two common prior options, conjugate priors for and one general prior
on
. These conditions are easy for practitioners to verify, hence serve as a guide to specify priors. We recommend imposing the prior on
rather than
to an ensured proper joint posterior and a relatively robust hyperparameter specification. In practice, it is often for researchers to face unobserved knots when dealing with curve fitting. Therefore, we extend our theoretical results to NBQSS with unobserved knots. Finally, our simulation studies imply that our NBQSS performs the best in candidate quantile methods and NBQSS with unobserved knots perform better than regular NBQSS for most of cases. As with any simulation study, these cannot cover all possibilities, but we believe that they are sufficiently wide ranging to provide useful insights into the comparative performance of the different procedures.
Several unsolved issues in our work still worth investigating. For example, as shown in the simulation studies, all quantile methods perform relatively worse near the boundary, such as p = 0.1, and more work is encouraged to improve their boundary behaviours under the Bayesian framework. Also, when there are unobserved knots, how to choose the positions of added knots and how to decide the number of added knots to obtain better fitted curves are of interest in NBQSS. Furthermore, we do not consider the crossing problem for different quantiles in this article. Without special restriction, quantile regression functions estimated at different orders can cross each other, which disobeys the rule of the probability. Therefore, another concern is to develop the theoretical results for the non-crossing Bayesian regularised regression quantile (Liu & Wu, Citation2011).
Acknowledgements
The authors sincerely thank two anonymous reviewers for the thoughtful and constructive suggestions they provided that led to considerable improvements in the presentation of our work.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Zhongheng Cai
Zhongheng Cai is a PhD candidate in the school of statistics, East China Normal University, Shanghai, China. His research interests include Bayesian statistics.
Dongchu Sun
Dr. Dongchu Sun received his PhD. in 1991 from Department of Statistics, Purdue University, under the guidance of Professor James O. Berger.
References
- Andrews, D. F., & Mallows, C. L. (1974). Scale mixtures of normal distributions. Journal of the Royal Statistical Society. Series B (Methodological), 36(3), 99–102. https://doi.org/https://doi.org/10.1111/rssb.1974.36
- Cheng, C. I., & Speckman, P. L. (2012). Bayesian smoothing spline analysis of variance. Computational Statistics and Data Analysis, 56(12), 3945–3958. https://doi.org/https://doi.org/10.1016/j.csda.2012.05.020
- Chernozhukov, V. (2005). Extremal quantile regression. Annals of Statistics, 33(2), 806–839. https://doi.org/https://doi.org/10.1214/009053604000001165
- Cole, T. J. (1988). Fitting smoothed centile curves to reference data. Journal of the Royal Statistical Society. Series A, 151(3), 385–418. https://doi.org/https://doi.org/10.2307/2982992
- Craven, P., & Wahba, G. (1978). Smoothing noisy data with spline functions. Numerische Mathematik, 31(4), 377–403. https://doi.org/https://doi.org/10.1007/BF01404567
- de Oliveira, V. (2007). Objective Bayesian analysis of spatial data with measurement error. The Canadian Journal of Statistics , 35(2), 283–301. https://doi.org/https://doi.org/10.1002/cjs.v35:2
- Gordon, P. (1941). Values of Mills' ratio of area to bounding ordinate and of the normal probability integral for large values of the argument. Annals of Mathematical Statistics, 12(3), 364–366. https://doi.org/https://doi.org/10.1214/aoms/1177731721
- Gu, C. (2013). Smoothing spline ANOVA models (2nd ed.). Springer.
- Hobert, J. P., & Casella, G. (1996). The effect of improper priors on Gibbs sampling in hierarchical linear mixed models. Journal of the American Statistical Association, 91(436), 1461–1473. https://doi.org/https://doi.org/10.1080/01621459.1996.10476714
- Hu, Y., Zhao, K., & Lian, H. (2015). Bayesian quantile regression for partially linear additive models. Statistics and Computing, 25(3), 651–668. https://doi.org/https://doi.org/10.1007/s11222-013-9446-9
- Jone, M. C. (1988). Discussion of paper by T. J. Cole. Journal of the Royal Statistical Society. Series A, 151(3), 412–413. https://doi.org/https://doi.org/10.2307/2982992
- Jørgensen, B. (1982). Statistical properties of the generalized inverse Gaussian distribution. Springer-Verlag New York Inc.
- Jullion, R., & Lambert, P. (2007). Robust specification of the roughness penalty prior distribution in spatially adaptive Bayesian P-splines models. Computational Statistics and Data Analysis, 51(5), 2542–2558. https://doi.org/https://doi.org/10.1016/j.csda.2006.09.027
- Koenker, R. (2004). Quantile regression for longitudinal data. Journal of Multivariate Analysis, 91(1), 74–89. https://doi.org/https://doi.org/10.1016/j.jmva.2004.05.006
- Koenker, R. (2005). Quantile regression. Cambridge University Press.
- Koenker, R., & Bassett, G. (1978). Regression quantiles. Econometrica, 46(1), 33–50. https://doi.org/https://doi.org/10.2307/1913643
- Koenker, R., Ng, P., & Portnoy, S. (1994). Quantile smoothing splines. Biometrika, 81(4), 673–680. https://doi.org/https://doi.org/10.1093/biomet/81.4.673
- Kozumi, H., & Kobayashi, G. (2011). Gibbs sampling methods for Bayesian quantile regression. Journal of Statistical Computation and Simulation, 81(11), 1565–1578. https://doi.org/https://doi.org/10.1080/00949655.2010.496117
- Lang, S., & Brezger, A. (2004). Bayesian P-Splines. Journal of Computational and Graphical Statistics, 13(1), 183–212. https://doi.org/https://doi.org/10.1198/1061860043010
- Li, Y, & Zhu, J. (2008). L1-Norm quantile regression. Journal of Computational and Graphical Statistics, 17(1), 163–185. https://doi.org/https://doi.org/10.1198/106186008X289155
- Liu, Y., & Wu, Y. (2011). Simultaneous multiple non-crossing quantile regression estimation using kernel constraints. Journal of Nonparametric Statistic, 23(2), 415–437. https://doi.org/https://doi.org/10.1080/10485252.2010.537336
- Nelson, C. B., & Siegel, A. F. (1987). Parsimonious modeling of yield curves. Journal of Business, 60(4), 473–489. https://doi.org/https://doi.org/10.1086/jb.1987.60
- Nychka, D. (2000). Smoothing and regression: approaches, computation, and application. Wiley.
- Santos, B, & Bolfarine, H. (2016). On Bayesian quantile regression and outliers. https://arxiv.org/pdf/1601.07344.pdf
- Silverman, B. (1985). Some aspects of the spline smoothing approach to non-parametric regression curve fitting. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 47(1), 1–52. https://doi.org/https://doi.org/10.1111/j.2517-6161.1985.tb01327.x
- Speckman, L. P., & Sun, D. (2003). Fully Bayesian spline smoothing and intrinsic autoregressive prior. Biometrika, 90(2), 289–302. https://doi.org/https://doi.org/10.1093/biomet/90.2.289
- Sriram, K., Ramamoorthi, R. V., & Ghosh, P. (2013). Posterior consistency of bayesian quantile regression based on the misspecified asymmetric laplace density. Bayesian Analysis, 8(2), 479–504. https://doi.org/https://doi.org/10.1214/13-BA817
- Sun, D., & Speckman, L. P. (2008). Bayesian hierarchical linear mixed models for additive smoothing splines. Annals of the Institute of Statistical Mathematics, 60(3), 499–517. https://doi.org/https://doi.org/10.1007/s10463-007-0127-3
- Sun, D., Tsutakawa, R. K., & Speckman, P. L. (1999). Posterior distribution of hierarchical models using CAR(1) distributions. Biometrika, 86(2), 41–50. https://doi.org/https://doi.org/10.1093/biomet/86.2.341
- Svensson, L. E. (1994). Estimating and interpreting forward interest rates: Sweden 1992–1994. Technical Report, NBER Working Paper, 4871, 1–27. https://doi.org/https://doi.org/10.3386/w4871
- Thompson, P., Cai, Y., Moyeed, R., Reeve, D., & Stander, J. (2010). Bayesian nonparametric quantile regression using splines. Computational Statistics and Data Analysis, 54(4), 1138–1150. https://doi.org/https://doi.org/10.1016/j.csda.2009.09.004
- Tong, X., He, Z., & Sun, D. (2018). Estimating Chinese treasury yield curves with Bayesian smoothing splines. Econometrics and Statistics, 8, 94–124. https://doi.org/https://doi.org/10.1016/j.ecosta.2017.10.001
- van Dyk, D. A., & Park, T. (2008). Partially collapsed gibbs samplers. Journal of the American Statistical Association, 103(482), 790–796. https://doi.org/https://doi.org/10.1198/016214508000000409
- Wahba, G. (1990). Spline models for observational data. Society for Industrial and Applied Mathematics.
- Wang, H., Li, G., & Jiang, G. (2007). Robust regression shrinkage and consistent variable selection through the LAD-Lasso. Journal of Business and Economic Statistics, 25(3), 347–355. https://doi.org/https://doi.org/10.1198/073500106000000251
- Wu, Y, & Liu, Y. (2009). Variable selection in quantile regression. Statistica Sinica, 19(2), 801–817.
- Yu, K., & Moyeed, R. A. (2001). Bayesian quantile regression. Statistics and Probability Letters, 54(4), 437–447. https://doi.org/https://doi.org/10.1016/S0167-7152(01)00124-9
- Yuan, M. (2006). GACV for quantile smoothing splines. Computational Statistics and Data Analysis, 5(3), 813–829. https://doi.org/https://doi.org/10.1016/j.csda.2004.10.008
- Yue, Y. R., & Rue, H. (2011). Bayesian inference for additive mixed quantile regression models. Computational Statistics and Data Analysis, 55(1), 84–96. https://doi.org/https://doi.org/10.1016/j.csda.2010.05.006
- Zhang, F. (2011). Matrix theory-basic results and techniques. Springer.
Appendices
Appendix 1. Proof of Theorem 2.1
Proof.
With the likelihood (Equation14(14)
(14) ) and priors (Equation15
(15)
(15) ), (Equation16
(16)
(16) ), the posterior of
is proportional to
(A1)
(A1) Integrate σ, (EquationA1
(A1)
(A1) ) is proportional to
(A2)
(A2) We only prove the sufficiency, the necessity can be proved in the similar way.
Since and
there exists a positive number
such that
(A3)
(A3) Moreover, there exist
such that
(A4)
(A4) Hence, we just need to consider,
(A5)
(A5) We consider
(A6)
(A6) since the integration with respect to
is proportional to (EquationA5
(A5)
(A5) ). Now, set
, (EquationA6
(A6)
(A6) ) becomes
which agrees with the case for normal error in Speckman and Sun (Citation2003), the results follow.
Appendix 2. Proof of Theorem 2.2
For , the following lemma is needed,
Lemma A.1
Assume , for any
,
Proof.
For (1), the third inequality is trivial, we focus on the other two inequalities. For the first one, we have,
By arithmetic-geometric mean inequality,
. Hence,
We can obtain
where Φ, ϕ are standard normal c.d.f and p.d.f respectively. By the inequality (Gordon, Citation1941)
the first inequality holds. For the second inequality, we need the hierarchical structure of the Laplace distribution. Andrews and Mallows (Citation1974) proposed that
(A9)
(A9) Hence, by Fubini's theorem,
(A10)
(A10) Since
,
, we have the marginal distribution of
is
. The inner integral equals
(A11)
(A11) Since the function
is unimodal with the maximum value
we have
Hence,
Clearly,
, so the second inequality holds.
For (2), since
(A12)
(A12) Set
we have
(A13)
(A13) Since the following identity holds for a, b are positive,
we have
(A14)
(A14) This implies result.
Assume SSE. First, we consider a>0. The joint posterior of
is proportional to
(A15)
(A15) By the spectral decomposition,
(A16)
(A16) where
is the orthogonal matrix and
Let
(A17)
(A17) Set
,
,
(A18)
(A18) Integrating out
, (EquationA18
(A18)
(A18) ) is proportional to
(A19)
(A19) Moreover,
(A20)
(A20) By Lemma A.1(a), we know (EquationA20
(A20)
(A20) ) is smaller than or equal to an expression proportional to
(A21)
(A21) When
, we know
has finite integral with respect to σ when a>0. Hence, if
is proper, the posterior of
is proper.
When a = 0, the joint posterior of is proportional to
(A22)
(A22) Following the same procedure as the case a>0, we only need to show
(A23)
(A23) has finite integral. By Lemma A.1(b), we know there exist a constant
such that (EquationA23
(A23)
(A23) ) is smaller than or equal to
(A24)
(A24) We know there are
terms after expansion. For the term involving both
we employ the inequality,
for
. Then, the term will not relate to η and has finite integral with respect to σ. Hence, we only need to consider the term
(A25)
(A25) Set
, then (EquationA25
(A25)
(A25) ) is equal to
which is proper when
. Hence, if
is proper, the posterior of
is proper.
When SSE, the joint posterior of
is proportional to
(A26)
(A26) With the same argument in Theorem 2.1, (EquationA26
(A26)
(A26) ) is smaller than or equal to
(A27)
(A27) Let
and
. The integral of (EquationA27
(A27)
(A27) ) w.r.t
equals to
(A28)
(A28) Since
is bounded, we only need to consider
(A29)
(A29) Similarly, we can find the
such that
(30)
(30) Let
, (EquationA31
(30)
(30) ) is proportional to the joint posterior of
when SSE = 0. By Theorem 2.2(a), the result holds.
For , since the posterior of
is proportional to
(A31)
(A31) We know that (EquationA31
(A31)
(A31) ) is the special case in Theorem 2.1. Hence, it has finite integral with respect to
iff
.
Appendix 3. Proof of Theorem 2.3
With the similar argument in Theorem 2.2, there exist such that
(A32)
(A32) By Lemma A.1(a) and the following inequality,
Ignoring the constant of the product, we have the right hand side of (EquationA32
(A32)
(A32) ) is larger than or equal to
(A33)
(A33) Set
, (EquationA33
(A33)
(A33) ) is larger than or equal to
(A34)
(A34) Since
has finite integral if
. Hence the necessary condition for the posterior propriety of
is
Combining the fact that
is bounded and away from zero in
for arbitrary large ϵ, The condition
(A35)
(A35) is also necessary. Next, we focus on the integral of η in the interval
. With loss of generality, assume
. All together (EquationA12
(A12)
(A12) ) with (EquationA19
(A19)
(A19) ), the integration of (EquationA32
(A32)
(A32) ) with respect to
is proportional to
(A36)
(A36) Let
,
(A37)
(A37) After integrating out σ in (EquationA37
(A37)
(A37) ), the result is proportional to
(A38)
(A38) since
, we have
(A39)
(A39) We will show right hand side of (EquationA40
(A39)
(A39) ), Q, is finite under n>2 + a. Divide the interval
into
, Q turns to be the summation of
integral. All the integrals can be dealt in the similar way. We take one for example. Consider
and the others are in
.
(A40)
(A40) since
and
,
(A41)
(A41) Using the polar transformation for
(A42)
(A42) where
and
. The determinant of Jacobian matrix is
. Hence, the right hand side of (EquationA41
(A41)
(A41) ) is proportional to
which is finite when
. Similarly, all the
integrals can be handled in this way and the case when all the
will give the most strict constraint for n, which is n>2 + a. Hence, we have
(A43)
(A43) Combing (EquationA35
(A35)
(A35) ) with (EquationA43
(A43)
(A43) ), the result holds.
Appendix 4. Proof of Theorem 3.1
The following lemma can be found in de Oliveira (Citation2007),
Lemma A.2
There exists a full rank matrix
satisfying
and
, for which the following hold,
For the special structure of , we can prove all its n−2 subprincipal matrice are positive definite. Let
be the orthogonalisation of
. We know
is an unitary matrix. Without loss of generality, we take the left upper subprincipal matrix of
with order n−2 for example and denote it to be
. The determinant is
where
is the first n−2 rows of
. In addition, since
is an unitary matrix, by the Theorem 6.3 in Zhang (Citation2011), we have
where c is a positive number related to
. Hence, we have
which is positive. Hence, all the n−2 subprincipal matrice of
are positive definite. Now, we can prove the theorem.
Here, we only consider the conditional posterior of . The similar argument can be applied to
. The conditional posterior of
is proportional to
(A44)
(A44) where
. Partition the precision matrix
,
(A45)
(A45) where
is the
matrix and
is
matrix. In addition, we have
is positive definite. Integrate out
, we have (EquationA44
(A44)
(A44) ) is proportional to
(A46)
(A46) where
whose rank is n−m−2. Then, (EquationA46
(A46)
(A46) ) has the same form as the case when
is full rank. Hence, the result holds.