
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
When the historical data of the early phase trial and the interim data of the Phase III trial are available, we should use them to give a more accurate prediction in both futility and efficacy analysis. The predictive power is an important measure of the practical utility of a proposed trial, and it is better than the classical statistical power in giving a good indication of the probability that the trial will demonstrate a positive or statistically significant outcome. In addition to the four predictive powers with historical and interim data available in the literature and summarized in Table 1, we discover and calculate another four predictive powers also summarized in Table 1, for one-sided hypotheses. Moreover, we calculate eight predictive powers summarized in Table 2, for the reversed hypotheses. The combination of the two tables gives us a complete picture of the predictive powers with historical and interim data for futility and efficacy analysis. Furthermore, the eight predictive powers with historical and interim data are utilized to guide the futility analysis in the tamoxifen example. Finally, extensive simulations have been conducted to investigate the sensitivity analysis of priors, sample sizes, interim result and interim time on different predictive powers.
1. Introduction
The predictive power, which is the prior expectation of the power and averaged over the prior distribution for the unknown true treatment effect, is an important measure of the practical utility of a proposed trial, and it is better than the power in giving a good indication of the probability that the trial will demonstrate a positive or statistically significant outcome. As we know, the power may have very different values at different treatment effects (for instance, a treatment effect under the alternative hypothesis or an observed treatment effect in the interim analysis), and that may cause difficulty for interpretation. The predictive power has been investigated intensively in the literature (Choi et al., Citation1985; Schmidli et al., Citation2007; Spiegelhalter et al., Citation1986; Zhang & Ting, Citation2018). Moreover, the predictive power is also known as assurance (Kirby et al., Citation2012; O'Hagan et al., Citation2005; Wang et al., Citation2006), Probability Of Success (POS) (Ibrahim et al., Citation2015; Jiang, Citation2011; Trzaskoma & Sashegyi, Citation2007), Average Success Probability (ASP) (Chuang-Stein, Citation2006; Zhang & Ting, Citation2020) or Contemplated Average Success Probability (CASP) (Zhang et al., Citation2020a).
The ‘predictive power’ is the central matter of our methodological development. Therefore, we present a general formal expression of it. The predictive power is an average power with respect to some prior, that is,
where δ is the true treatment effect of the early phase and Phase III trials. There are eight predictive powers with historical and interim data, because we have four choices for
, that is, the classical power that does not use any data, the classical conditional power that uses the interim data once, the Bayesian power that uses the historical data once, and the Bayesian conditional power that uses the historical data once and the interim data once; and we have two choices for
, that is,
that uses the historical data once, and
that uses the historical data once and the interim data once, where
is the historical data, and
is the interim data.
Spiegelhalter et al. (Citation2004) have calculated the rejection region, the power or the conditional power, and the predictive power or the conditional predictive power of the hypotheses versus
for five different scenarios, which are non-sequential trials with classical power and Bayesian power, and sequential trials with hybrid predictions, Bayesian predictions, and classical predictions in Sections 6.5 and 6.6. They also gave the adjusting formulae, which include nonzero threshold and reversal of hypotheses, for different hypotheses in Section 6.5.4. In their book, they did not explicitly mention that the predictive powers of the five different scenarios use different combination of historical and interim data. In this article, we explicitly mention that different predictive powers will use different combination of historical and interim data. Moreover, we expand the four predictive powers (the predictive power corresponding to the sequential trials with classical predictions is excluded) in Spiegelhalter et al. (Citation2004) to eight predictive powers for the hypotheses
versus
and the reversed hypotheses
versus
, which can be seen in Tables and , where
is a threshold value for δ. In other words, we have discovered four predictive powers with historical and interim data for the hypotheses and the reversed hypotheses. Finally, the eight predictive powers are utilized to guide the futility analysis in the tamoxifen example, in which a long-term tamoxifen therapy is used for the prevention of recurrence of breast cancer. The tamoxifen example is a Phase III trial and the predictive powers suggest us to stop the trial for futility.
Table 1. The eight predictive powers with historical and interim data, their analytical expressions, the predictive distributions, the data used, and the references for the hypotheses versus
.
Table 2. The eight predictive powers with historical and interim data, their analytical expressions, the predictive distributions, and the data used for the reversed hypotheses versus
.
The rest of the paper is organized as follows. In Section 2, we provide two tables. The eight predictive powers with historical and interim data, their analytical expressions, the predictive distributions, the data used, and the references for the hypotheses versus
are given in Table . Those quantities for the reversed hypotheses
versus
are given in Table . The data structures of the historical data, interim data and future data described in Figure can also be found in this section. Section 3 illustrates the calculations of the eight predictive powers through the tamoxifen example. Section 4 conducts extensive simulations to investigate the sensitivity analysis of priors, sample sizes, interim result and interim time on different predictive powers. Some conclusions and discussions are provided in Section 5.
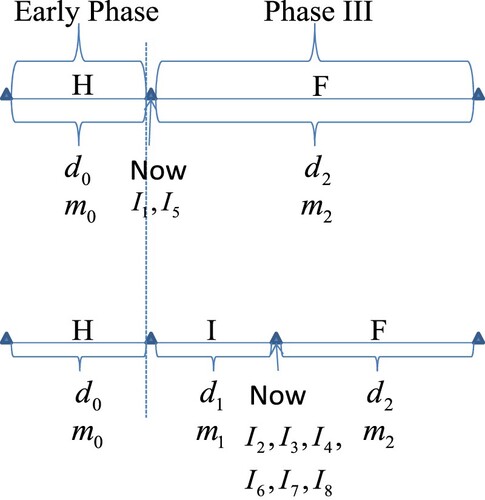
Figure 1. The data structures of the historical data, interim data and future data.
2. Eight predictive powers with historical and interim data
Similar to Dmitrienko and Wang (Citation2006) and Jiang (Citation2011), a go/no-go decision rule can be defined at the end of the early phase trial or at the interim of the Phase III trial. In our notation, (1)
(1) where
is the predictive power, while
,
and
are pre-specified thresholds for futility, go and efficacy, respectively. The thresholds should satisfy the following constraints:
Jiang (Citation2011) suggests
, with
meaning that a stop for futility decision is taken if
that is, the risk of failure is greater than or equal to the chance of success. The threshold
can be set at a relatively high value such as 0.9, so that when the
exceeds this threshold, a stop for efficacy decision can be made. Finally, the threshold
can be set at a value such as 0.8, so that if
, a go decision can be made, where ‘Go’ means moving on without the need of adjustment to the sample size of the future data
; if
, a conditional-go decision can be made, where ‘Conditional-Go’ means moving on with the condition that
is either increased to improve the
(so it is equal or close to
) or staying unchanged while acknowledging a reduced
or increased risk of failure. Note that there are two no-go decisions in our decision criteria (Equation1
(1)
(1) ), that is, stop for futility and stop for efficacy.
The data structures of the historical data, interim data and future data are described in Figure . In the figure, H means historical data, I means interim data and F means future data. The historical data could be the Phase II data, or the previous Phase III data, as long as the outcome variable and patient populations are the same between the historical data and the upcoming Phase III data. Moreover, the historical data could also be a fictitious data corresponding to a sceptical or optimistic prior, and in this case and
of the historical data are determined to satisfy the requirements of the sceptical or optimistic prior. Note that
,
and
are the observed treatment differences in the treatment group and the control (or placebo) group of the historical data, interim data and future data respectively, and
,
and
are the per group number of patients of the historical data, interim data and future data respectively. In the upper plot, only historical data are available. Furthermore, the upper plot also depicts the data structure for criterion (Equation7
(7)
(7) ). Note that in the upper plot, the sample size of the future data
is the whole sample size of the Phase III trial. Note that the present time of the program (termed now) in the upper plot is at the end of Early Phase and before the start of Phase III. At that time, only two predictive powers can be calculated to facilitate the go/no-go decision according to the decision criteria (Equation1
(1)
(1) ), that is, the first and fifth predictive powers in Tables and . If the
results in a ‘Go’ or ‘Conditional-Go’ decision according to the decision criteria (Equation1
(1)
(1) ), then the Phase III trial is launched. However, if the
results in a no-go decision (either stop for futility or stop for efficacy), then the Phase III trial will not be launched. Furthermore, if the Phase III trial is launched and the interim data of the Phase III trial are available, the data structure of the program can be described in the lower plot of Figure . Note that the present time of the program (termed now) in the lower plot is at the interim of the Phase III trial. At the interim, there are six predictive powers which can be calculated to facilitate the go/no-go decision according to the decision criteria (Equation1
(1)
(1) ), that is, the second, third, fourth, sixth, seventh and eighth predictive powers in Tables and . In the lower plot, both historical data and interim data are available. Moreover, the lower plot also depicts the data structure for criterion (Equation4
(4)
(4) ) and (Equation5
(5)
(5) ).
Note that F in the graph could be meaning data after interim in the lower plot, and full Phase III data in the upper plot. The justifications of the meaning of F are given as follows. First, the future data are the data after the present time (termed now in the upper and lower plots). Second, in the lower plot, when the information time increases, the interim data become more and more, and the future data become less and less. Conversely, when the information time decreases, the future data become more and more, and the interim data become less and less. When the information time is 0, the future data is the full Phase III data.
Suppose that the interim analysis of a randomized controlled Phase III trial is to be conducted with patients randomized to one of two treatments, with patients allocated to treatment i (i = 1, 2), where treatment 2 is the test drug and treatment 1 is the control (or placebo). Moreover, suppose that the j-th patient receiving treatment i for the interim data will yield a continuous response
that we can assume is normally distributed with an unknown mean
and a common known variance
. The third subscript ‘1’ in
means that the responses are for the interim data. Moreover, assume that the data from the two treatments are independent. Thus the model of the interim data of the Phase III trial is that
It is easy to derive the sampling distributions of the sufficient statistics
More specifically,
Therefore,
where
is the sample mean difference based on the interim data of the Phase III trial, and
is the true treatment effect based on the interim data of the Phase III trial.
Similarly, suppose that the future data of a randomized controlled Phase III trial is to be collected with patients randomized to one of two treatments, with patients allocated to each treatment. After some similar derivations for the interim analysis of the Phase III trial, we have
where
is the sample mean difference based on the future data of the Phase III trial,
is the true treatment effect based on the future data of the Phase III trial,
is the sample mean of
which is the continuous response of the j-th patient receiving treatment i for the future data, and
is the unknown mean of
. The third subscript ‘2’ in
means that the responses are for the future data. Note that we have assumed the true treatment effects based on the interim data and future data of the Phase III trial are the same. This assumption has also been used in the literature. See for instance (Spiegelhalter et al., Citation2004). Note also that the assumption can be easily violated in the clinical trials, such as the enrichment design which will change the population. Therefore, our discussions are not suitable for the enrichment design.
Suppose that we have some prior knowledge about δ through the historical data corresponding to patients per group in two treatments, and the prior mean of δ is estimated to be
. We remark that the historical data with
patients refer to Phase II patients specifically, and thus the treatment effect δ in Phase II could be different than Phase III. However, in many disease areas where main clinical outcomes can be observed in relatively short duration – such as acute pain, allergy, asthma, depression, hypertension, and so on – Phase II and Phase III trials often have the same trial design including a same outcome variable and same patient population. In these disease areas, the treatment effect δ on Phase II and Phase III trials can be assumed the same. For simplicity, we assume a normal model for the prior. That is,
(2)
(2) Note that this prior incorporating the historical data can be obtained as follows. For the historical data
, assume that
Suppose that we have no prior knowledge about δ before the historical data
, and thus we assume that δ has an improper uniform prior over
, that is,
. Then the posterior distribution of δ given
is easily found to be given by (Equation2
(2)
(2) ).
Therefore, when the interim data is available, the model and the prior are given by
(3)
(3) Let the model and prior be given by (Equation3
(3)
(3) ). Given the likelihood
and the prior
, standard Bayesian calculus yields the posterior distribution of δ given
and the conditional distribution of
given
, that is,
(4)
(4) Then using the posterior distribution
as a new prior for our future data
, standard Bayesian calculus yields the posterior distribution of δ given
and the conditional distribution of
given
, that is,
(5)
(5) The data structure of (Equation4
(4)
(4) ) and (Equation5
(5)
(5) ) is depicted in the lower plot of Figure . Note that the posterior distribution
is used in the calculations of the Bayesian rejection regions with
,
The conditional distribution
is the predictive distribution used in the calculations of the even-numbered predictive powers in Table .
Similarly, when the interim data is not available, the model and the prior are given by
(6)
(6) Let the model and prior be given by (Equation6
(6)
(6) ). Given the likelihood
and the prior
, standard Bayesian calculus yields the posterior distribution of δ given
and the conditional distribution of
given
, that is,
(7)
(7) The data structure of (Equation7
(7)
(7) ) is depicted in the upper plot of Figure . Note that the posterior distribution
is used in the calculations of the Bayesian rejection regions with
,
The conditional distribution
is the predictive distribution used in the calculations of the odd-numbered predictive powers in Table .
For clarity, we define the Classical Power (CP), Classical Conditional Power (CCP), Bayesian Power (BP), and Bayesian Conditional Power (BCP). The CP is the probability of the classical rejection region with ,
, given a value for δ,
, where S is for ‘Success’ and the success region is the rejection region, C is for ‘Classical’, α is the significance level, and
is a threshold value for δ. The CCP is the probability of the classical rejection region with
and
,
, given values of δ and interim result
,
. The BP is the probability of the Bayesian rejection region with
,
, given values of δ and historical result
,
, where B is for ‘Bayesian’. The BCP is the probability of the Bayesian rejection region with
,
, given values of
,
. Under normality assumptions for the priors and the likelihoods, it is easy to obtain the expressions of the rejection regions and the powers as
where
(8)
(8)
(9)
(9)
(10)
(10)
(11)
(11)
The detailed derivations of the expressions of the rejection regions and the powers can be found in the supplement.
Suppose that we are interested in testing the hypotheses versus
. This kind of hypotheses arise when we assume that a larger value in the population mean of the normal distribution means improvement in disease condition. Hence, a positive value of δ means better. The eight predictive powers with historical and interim data, their analytical expressions, the predictive distributions, the data used, and the references for the hypotheses
versus
are given in Table . Note that the definitions of the eight predictive powers for the hypotheses are given in Table under the column name ‘Predictive Power’. In the table:
For the predictive power column,
is the Classical Predictive Power (CPP),
The analytical expressions are given as follows:
Note that in the table, for
Note that in the table, there are only two predictive distributions, that is,
For the data used column, H means that the historical data are used, and I means that the interim data are used. HI means that the historical data are used once and the interim data are also used once. HI
For
Now suppose that we are interested in testing the reversed hypotheses versus
. This kind of hypotheses arise when we assume that a smaller value in the population of the normal distribution means improvement in disease condition. Hence, a negative value of δ means better. We will use a ‘−’ sign here to indicate that the respective quantities are calculated for the reversed hypotheses. The eight predictive powers with historical and interim data, their analytical expressions, the predictive distributions, and the data used for the reversed hypotheses
versus
are given in Table . Note that the definitions of the eight predictive powers for the reversed hypotheses are given in Table under the column name ‘Predictive Power’. In the table:
For the predictive power column, the nomenclatures are the same as in Table with a ‘−’ sign here to indicate that the respective nomenclatures are for the reversed hypotheses.
The analytical expressions are given as follows:
Note that in the table, there are only two predictive distributions, that is,
The data used column can be explained in the same way as in Table .
There are no references available to the best of our knowledge for the reversed hypotheses
Comparing Tables and , we find that for each predictive power, the predictive distribution and the data used are the same. From the two tables we see that the analytical expressions of the hypotheses versus
are just the quantities of the hypotheses
versus
with the terms involving
and
adding a negative sign, and vice versa.
3. A real data example
Long-term tamoxifen therapy is used for the prevention of recurrence of breast cancer (see Dignam et al., Citation1998; Example 6.7 in Spiegelhalter et al., Citation2004). The aim of the study is to estimate disease-free survival benefit from tamoxifen over placebo, in patients who already have had 5 years of taking tamoxifen without a recurrence. That means, patients were randomized to either continuation of tamoxifen therapy or continuation with placebo after having survived recurrence-free under tamoxifen for 5 years. To detect a reduction in annual risk associated with tamoxifen (hazard ratio
), with
power and a one-sided tail area of
, 115 events were required. The statistical model is the proportional hazards regression model, with summary using the approximate hazard ratio analysis. If there are
events on treatment, and
events on control, then
is an approximate estimate of the log(hazard ratio) δ, with mean δ and variance
, as shown in Tsiatis (Citation1981). Prior distributions: an optimistic prior was centred on a
hazard reduction and a
chance of a negative effect (i.e., HR>1), equivalent on the
scale to a normal prior with mean
and standard deviation 0.31 (
,
). Note that in Spiegelhalter et al. (Citation2004), the variance is
, while in our article, the variance is
, and thus
in our article. Moreover,
is used to guarantee that ‘an optimistic prior was centred on a
hazard reduction and a
chance of a negative effect’. Also a sceptical prior was adopted with the same standard deviation as the optimistic prior but centred on
. The estimated
after the first interim analysis in 1993 is
. At that time
events have been observed, and further
events are to be observed.
In the tamoxifen example, let and
be the hazard rates corresponding to tamoxifen (treatment) and placebo (control) respectively. Therefore,
Consequently, for
, the j-th predictive power
is for control superior, the j-th predictive power
is for tamoxifen superior, and
is for equivocal.
The eight predictive powers with historical and interim data of eventual conclusions for the B-14 trial after the first interim analysis in 1993 are reported in Table . In the table, the conclusion is: ‘Tamoxifen superior’, defined as a confidence interval or credible interval for
lying wholly below 0; ‘Equivocal’, defined as a
confidence interval or credible interval for
including 0; and ‘Control superior’, defined as a
confidence interval or credible interval for
lying wholly above 0. The significance level α is chosen to be 0.025 in all cases. For the first and fifth predictive powers, the number of events of the future data
is the whole number of events of the Phase III trial 115, not 69 (the further number of events to be observed). In Table , we observe the following facts.
Table 3. The eight predictive powers with historical and interim data of eventual conclusions for the B-14 trial after the first interim analysis in 1993. Two prior distributions are considered: a sceptical prior and an optimistic prior.
The sum of the three predictive powers in each row corresponding to the sceptical prior (or the optimistic prior) should be equal to 1. However, in some cases, the sum is equal to 0.999, due to the rounding error.
The fourth predictive powers in Table are the same as those under the column ‘When not using prior in analysis’, which can be calculated by (6.15), in Table 6.7 of Spiegelhalter et al. (Citation2004). Moreover, the eighth predictive powers in Table are the same as those under the column ‘When using prior in analysis’, which can be calculated by (6.18), in Table 6.7 of Spiegelhalter et al. (Citation2004).
All the predictive powers under the ‘Tamoxifen superior’ column are less than 0.85, the designed power. Note that these predictive powers are calculated when the significance level α is chosen to be 0.025, while the designed power 0.85 is calculated when α is chosen to be 0.05. When the significance level α is risen to 0.05 when calculating the predictive powers, the predictive powers also rise, as the predictive powers are increasing functions of α. However, they are still less than 0.85. This phenomenon has been observed in the literature. See for instance Chuang-Stein (Citation2006); Chuang-Stein Kirby (Citation2017); Spiegelhalter et al. (Citation2004).
For the eight predictive powers, the optimistic prior has a greater tendency to draw a ‘Tamoxifen superior’ conclusion than the sceptical prior, and this is reflected in the predictive powers. In contrast, the sceptical prior has a greater tendency to draw a ‘Control superior’ conclusion than the optimistic prior, and this is also reflected in the predictive powers.
Now let us focus on the ‘Tamoxifen superior’ column. The first predictive power under the optimistic prior is 0.656, which is fairly high, due to the first predictive power only uses the historical data once and it does not use the interim data, and the historical data (a fictitious data corresponding to the optimistic prior) favours the tamoxifen treatment. The fifth predictive power under the optimistic prior is 0.771, which is even higher, due to the fifth predictive power uses the historical data twice and it does not use the interim data, and the historical data favours the tamoxifen treatment. Note that the time point of the first and fifth predictive powers is before the launch of the Phase III trial. Since the first and fifth predictive powers are between
4. Numerical simulations
In this section, we will conduct extensive simulations to investigate the sensitivity analysis of priors (), sample sizes (
,
,
), interim result (
), and interim time (t) on the eight predictive powers. We assume that
where
is calculated to ensure that an optimistic prior was centred on a
hazard reduction and a
chance of a negative effect (i.e., HR>1), equivalent on the
scale to a normal prior with mean
and standard deviation 0.31 (
,
). We add a superscript ‘r’ in
,
,
,
and
to indicate that they are from the real data.
Now let us explain the special reason for choosing in the simulations section. As described in Section 2.4.2 in Spiegelhalter et al. (Citation2004), suppose that the first intervention corresponds to an active treatment T, and the second to a control C. Often the results of a survival analysis may be given in terms of an observed log-rank test statistic
, which is defined as the excess of events under T, compared to that expected were there no treatment effect, where m is the total number of events observed.
is often denoted as O−E (observed minus expected). Assuming proportional hazards, we have the following approximation in the particular case of equal allocation and follow-up. If there have been
events on treatment, and
events on control, then the expected number of events in the treatment group under the null hypothesis is approximately m/2, and hence the log-rank statistic is
. It can be shown in Tsiatis (Citation1981) that, for large trials,
is an approximate estimate of the log(hazard ratio) θ, and
Hence we can set
and adopt a normal likelihood. Note that in Spiegelhalter et al. (Citation2004), the variance is
, while in our article, the variance is
, and thus
in our article, as
Let us introduce some notations used in this section.
is the i-th predictive power for tamoxifen superior,
is the i-th predictive power for control superior, and
is the i-th predictive power for equivocal, for
.
is the i-th predictive power of the sceptical prior for tamoxifen superior,
is the i-th predictive power of the sceptical prior for control superior,
is the i-th predictive power of the sceptical prior for equivocal,
is the i-th predictive power of the optimistic prior for tamoxifen superior,
is the i-th predictive power of the optimistic prior for control superior, and
is the i-th predictive power of the optimistic prior for equivocal, for
. In the notations (
,
,
,
,
and
), the superscript ‘s’ is for the sceptical prior which corresponds to
, the superscript ‘o’ is for the optimistic prior which corresponds to
, the subscript ‘i’ is for the i-th predictive power,
is for tamoxifen superior, I is for control superior, and E is equivocal.
The sensitivity analysis of on the eight predictive powers is displayed in Figure . In the figure, we note the following issues.
Figure 2. The sensitivity analysis of on the eight predictive powers.
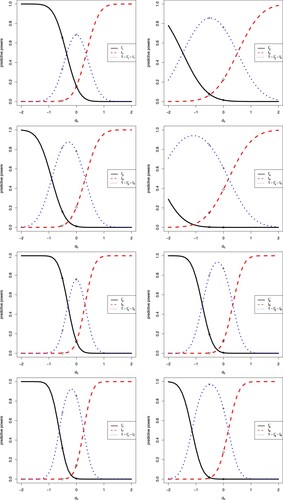
The first and second predictive powers are related to the CP, the third and fourth predictive powers are related to the CCP, the fifth and sixth predictive powers are related to the BP, and the seventh and eighth predictive powers are related to the BCP.
A negative
From the first plot, we see that
In the first plot, there are six markers labelled °, △, +, ×, ⋄ and ▽, which correspond to
In the first plot, the six values
The predictive powers
In the first plot, a different
From the first plot, we see that as
The other seven plots can be explained similarly to the first plot.
It is interesting to note that for the first and fifth predictive powers, the predictive powers for equivocal are symmetric around
The sensitivity analysis of on the eight predictive powers is displayed in Figure . In the figure, we note the following issues.
For the i-th (
Note that
The increase-decrease characteristics of
Figure 3. The sensitivity analysis of on the eight predictive powers.
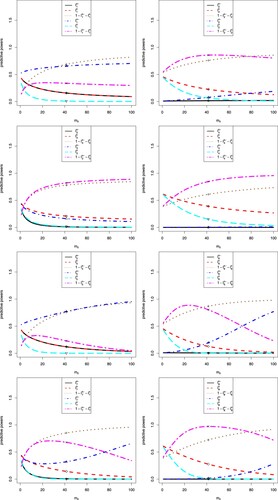
Table 4. The increase–decrease characteristics of ,
,
,
,
and
for
observed from Figure .
The sensitivity analysis of on the eight predictive powers is displayed in Figure . In the figure, we note the following issues.
Note that
A negative
From the figure, we see that
The optimistic prior favours tamoxifen, and thus
For the i-th (i = 2, 3, 4, 6, 7, 8) predictive power, there are six markers labelled °, △, +, ×, ⋄ and ▽, which correspond to
In each plot,
Figure 4. The sensitivity analysis of on the eight predictive powers.
The sensitivity analysis of on the eight predictive powers are displayed in Figure . In the figure, we note the following issues.
Note that
In each plot, s = 115 is fixed,
For the i-th (i = 2, 3, 4, 6, 7, 8) predictive power, there are six markers labelled °, △, +, ×, ⋄ and ▽, which correspond to
Note that
When
The increase–decrease characteristics of
Figure 5. The sensitivity analysis of on the eight predictive powers.
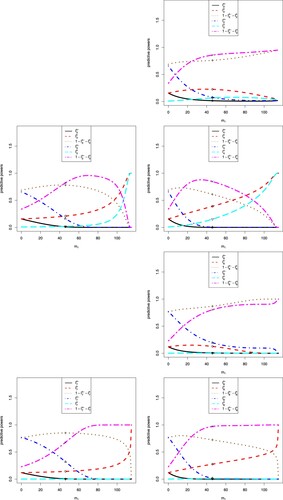
Table 5. The increase–decrease characteristics of ,
,
,
,
and
for i = 2, 3, 4, 6, 7, 8 observed from Figure .
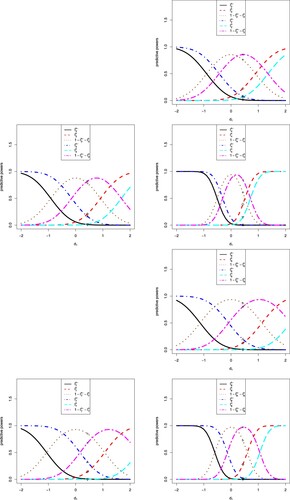
The sensitivity analysis of on the eight predictive powers is displayed in Figure . In the figure, we note the following issues.
For the i-th (
Note that for the first and fifth predictive powers, the range of
Note that
The increase-decrease characteristics of
Figure 6. The sensitivity analysis of on the eight predictive powers.
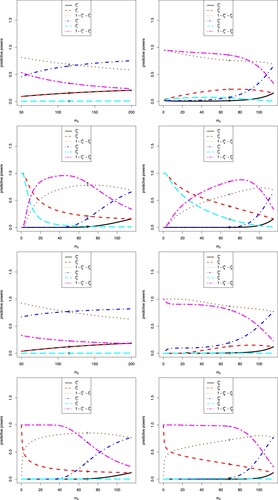
Table 6. The increase–decrease characteristics of ,
,
,
,
and
for
observed from Figure .
The sensitivity analysis of t on the eight predictive powers are displayed in Figure . In the figure, we note the following issues.
Note that t is the information time of the interim data. The first and fifth predictive powers do not use the interim data, and thus they are missing in the figure.
Figures and are the same with the only differences of the x-labels and x-ranges, which are
For the i-th (i = 2, 3, 4, 6, 7, 8) predictive power, there are six markers labelled °, △, +, ×, ⋄, and ▽, which correspond to
When
The increase–decrease characteristics of
Figure 7. The sensitivity analysis of t on the eight predictive powers.
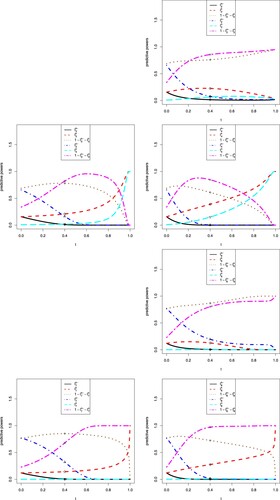
5. Conclusion and discussion
For the randomized controlled early phase and Phase III trials, suppose that the model and the prior are given by (Equation3(3)
(3) ). We provide two tables in this article. The eight predictive powers with historical and interim data, their analytical expressions, the predictive distributions, the data used, and the references for the hypotheses
versus
are given in Table . The eight predictive powers with historical and interim data, their analytical expressions, the predictive distributions and the data used for the reversed hypotheses
versus
are given in Table . Moreover, the data structures of the historical data, interim data and future data are described in Figure . Furthermore, the eight predictive powers with historical and interim data for the hypotheses and the reversed hypotheses are utilized to guide the futility analysis in the tamoxifen example. Finally, extensive simulations are conducted to investigate the sensitivity analysis of priors (
), sample sizes (
,
,
), interim result (
) and interim time (t) on the eight predictive powers.
In addition to the four predictive powers (,
,
,
) summarized in Table , we discover and calculate another four predictive powers (
,
,
,
) also summarized in Table , for the hypotheses
versus
. Moreover, we calculate eight predictive powers (
to
) summarized in Table , for the reversed hypotheses
versus
. The combination of Tables and gives us a complete picture of the predictive powers with historical and interim data for futility and efficacy analysis, as illustrated in Table .
By comparing these eight predictive power calculations, one main difference among them is how many times the historical data and interim data are utilized. For example, the historical data and the interim data could be used once or twice in these calculations. It may be confusing to the reader why the historical data or interim data could be used twice. For example, if the predictive power is calculated at the time when the required interim data are collected, why the authors incorporate the interim data into the prior specification given the interim data have been contributed to the likelihood? These are the fourth and eighth predictive powers in Tables and . Note that in Table , the fourth predictive power is (6.15) in Spiegelhalter et al. (Citation2004), and it is the average classical conditional power with respect to the updated new prior ; the eighth predictive power is (6.18) in Spiegelhalter et al. (Citation2004), and it is the average Bayesian conditional power with respect to the updated new prior
. If one is willing to use the historical data and interim data only once, then one could use the second and third predictive powers in the two tables, and the two predictive powers are discovered by us. Another possible solution to use the data twice is to use the external data.
Two sets of one-sided hypotheses are considered throughout the paper, and they are both needed. That is, both Tables and are needed. As discussed in the real data example, for , the j-th predictive power
(see Table ) is for control superior, the j-th predictive power
(see Table ) is for tamoxifen superior, and
is for equivocal.
We have assumed a known variance (), which is unrealistic. However, in the literature and real applications (see for instance Chuang-Stein, Citation2006; Kirby et al., Citation2012; Lan & Wittes, Citation2012; O'Hagan et al., Citation2005; Spiegelhalter et al., Citation2004; Wang et al., Citation2006), it is common practice to assume that the variance
is known to obtain analytical solutions, such as
for powers and average powers. When the variance is unknown, one might use the historical data to specify a sampling prior for
(Chen et al., Citation2011). Alternatively, one might utilize a t statistic. As stated in O'Hagan et al. (Citation2005), the sampling distribution of t is a non-central t distribution (which only becomes an ordinary Student t distribution if
). Nevertheless, based on previous Phase II trials or publications, the estimate of
is good enough, such that it provides some assurance to the practitioners that probably there is no need to have a prior for
when designing the Phase III trial. Furthermore, in practice and in publications, it is not common to add a prior to
in the calculations in frequentist framework and mixed frequentist and Bayesian framework. However, it is very common to include prior on
in pure Bayesian framework.
We have assumed equal variances for the normally distributed responses of two treatments of the Phase III trial. The equal variances assumption can be reasonably met in reality by exploiting the randomized controlled Phase III trial. This statement needs to be further justified. Consider a well-designed (patient-masked and outcome observer-blinded) placebo controlled trial where patients in the control group will demonstrate (approximately) the same outcome before and after treatment exposure. If the study drug is effective in a certain portion of patients in the treatment arm, the outcome for these patients will be different (shifted by a certain magnitude) before and after treatment. Hence, the variance in the treatment arm is expected to be higher than that in the control arm, unless the study drug is similarly effective in every patient who received it. On the other hand, if the study drug leads to an elevation (or decrease) of the outcome to a certain boundary value, the variance in the treatment group may be even smaller than that in the control group. Therefore, for simplicity, we assume equal variances for the normally distributed responses of two treatments. However, it is not uncommon to assume unequal variances in pure Bayesian framework.
The method demonstrated in Section 2 assumes the treatment arms have the same randomization ratio for illustration purpose, but the method can be easily adapted when the randomization ratios are not balanced. See the Conclusions and Discussion section in Deng et al. (Citation2020) for details.
For simplicity, we assume that outcome measurements are available for all individuals in the study and that everyone in the treatment arm and the control arm is fully adherent to the treatment they are allocated to, i.e., no non-compliance or treatment arm cross-over. In other words, the meaning of the effect parameter we are going to identify from the observed data is the true average treatment effect.
For simplicity, we have assumed the true treatment effects based on the historical data of the early phase trial, the interim data, and the future data of the Phase III trial are the same. This assumption has also been used in the literature. For example, Chuang-Stein (Citation2006) has assumed that the true treatment effects based on the Phase II trial and the Phase III trial are the same. Spiegelhalter et al. (Citation2004) have assumed that the true treatment effects based on the interim data and the future data of the Phase III trial are the same.
The analytical derivations in Section 2 are based on normal likelihoods. As explained in Section 2.4 of Spiegelhalter et al. (Citation2004), normal likelihoods can be used for binary data, survival data, count responses and continuous responses. In the real data example, we use a data example where survival data (disease-free survival time) is the primary outcome variable. Note that, in general, effect estimates such as log hazard ratios follow a normal distribution. It is important to stress that ,
and
do represent number of events and are not sample sizes in this context.
Intuitively, when the historical and interim data are available, they should be used to give a more accurate prediction, as the predictive powers shown in Table . Therefore, we recommend reporting all eight predictive powers in practice to have a complete picture for futility and efficacy analysis.
If one is interested in evaluating whether the incorporation of the historical data or interim data can improve the estimation of treatment effects for futility analysis, a real data example is not enough. One may need to conduct simulation studies to evaluate estimation accuracy or correct stopping rates by using the historical data (or interim data) or not. Alternatively, one may use the Receiver Operating Characteristic (ROC) curve as a tool to evaluate and compare operating characteristics by using the historical data (or interim data) or not. In fact, we are currently working on the analytical ROC analyses of the eight predictive powers, and the elaborated version deserves another publication.
Table summarizes the predictive power values for the example data under three predefined scenarios (tamoxifen superior, equivocal, and control superior) considering sceptical and optimistic priors. Note that the three scenarios are based on the notion of ‘statistical significance’, i.e. if 0 is included in the posterior interval for the target parameter δ or not. One could consider the specification of these scenarios as to consider clinically relevant equivalence margins for δ (say
or
). The statement ‘equivocal’ would then only hold, if both credible interval limits fall within these margins.
The way the results are presented right now suggests to stop the trial for futility but this may in fact be an imprecision issue due to small (or limited overall number of events). This claim is supported by the fact that even for very low optimistic predictive power values under scenario ‘Tamoxifen superior’, the sceptical predictive power values under scenario ‘Control superior’ remain relatively low. This means that the confidence intervals or credible intervals of δ often are too wide to exclude 0 for the target parameter δ. The lengths of the confidence intervals or credible intervals of δ and the lengths of the intervals of
of equivocal are decreasing functions of
. That is, when
is small (imprecision), the lengths of the intervals of
of equivocal are large. Hence, it is probably that the probabilities of equivocal for the powers and predictive powers will be large. It is worth noting that the imprecision issues due to small
(or limited overall number of events) are related to all four powers (CP, CCP, BP and BCP) and all eight predictive powers. We are currently working on the imprecision issue, and the elaborated version deserves another publication.
Assuming a flat prior with infinite tales () seems overly conservative, the uniform prior interval would in practice rather be
with
and
for the hypotheses
versus
, expressing the optimism of the drug-developer as the drug made it already beyond lab and animal testing. That is, it is useful to allow for the incorporation of a proper uniform prior for δ when estimating the posterior
, into formula (Equation3
(3)
(3) ) and following expressions. However, in this situation, one may not obtain analytical solutions. Then one should be able to derive the predictive powers numerically.
Acknowledgments
The authors are extremely grateful to the editor, the associate editor, and the reviewer for their insightful comments that led to significant improvement of the article.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Chen, M. H., Ibrahim, J. G., Lam, P., Yu, A., & Zhang, Y. Y. (2011). Bayesian design of noninferiority trials for medical devices using historical data. Biometrics, 67(3), 1163–1170. https://doi.org/10.1111/biom.2011.67.issue-3
- Choi, S. C., Smith, P. J., & Becker, D. P. (1985). Early decision in clinical trials when the treatment differences are small. Controlled Clinical Trials, 6(4), 280–288. https://doi.org/10.1016/0197-2456(85)90104-7
- Chuang-Stein, C. (2006). Sample size and the probability of a successful trial. Pharmaceutical Statistics, 5(4), 305–309. https://doi.org/10.1002/(ISSN)1539-1612
- Chuang-Stein, C., & Kirby, S. (2017). Quantitative decisions in drug development. Springer.
- Deng, Q. Q., Zhang, Y. Y., Roy, D., & Chen, M. H. (2020). Superiority of combining two independent trials in interim futility analysis. Statistical Methods in Medical Research, 29(2), 522–540. https://doi.org/10.1177/0962280219840383
- Dignam, J. J., Bryant, J., Wieand, H. S., Fisher, B., & Wolmark, N. (1998). Early stopping of a clinical trial when there is evidence of no treatment benefit: protocol b-14 of the national surgical adjuvant breast and bowel project. Controlled Clinical Trials, 19(6), 575–588. https://doi.org/10.1016/S0197-2456(98)00041-5
- Dmitrienko, A., & Wang, M. D. (2006). Bayesian predictive approach to interim monitoring in clinical trials. Statistics in Medicine, 25(13), 2178–2195. https://doi.org/10.1002/(ISSN)1097-0258
- Ibrahim, J. G., Chen, M. H., Lakshminarayanan, M., Liu, G. F., & Heyse, J. F. (2015). Bayesian probability of success for clinical trials using historical data. Statistics in Medicine, 34(2), 249–264. https://doi.org/10.1002/sim.v34.2
- Jiang, K. (2011). Optimal sample sizes and go/no-go decisions for phase ii/iii development programs based on probability of success. Statistics in Biopharmaceutical Research, 3(3), 463–475. https://doi.org/10.1198/sbr.2011.10068
- Kirby, S., Burke, J., Chuang-Stein, C., & Sin, C. (2012). Discounting phase 2 results when planning phase 3 clinical trials. Pharmaceutical Statistics, 11(5), 373–385. https://doi.org/10.1002/pst.1521
- Lan, K. K. G., & Wittes, J. T. (2012). Some thoughts on sample size: a Bayesian frequentist hybrid approach. Clinical Trials, 9(5), 561–569. https://doi.org/10.1177/1740774512453784
- O'Hagan, A., Stevens, J. W., & Campbell, M. J. (2005). Assurance in clinical trial design. Pharmaceutical Statistics, 4(3), 187–201. https://doi.org/10.1002/(ISSN)1539-1612
- Schmidli, H., Bretz, F., & Racine-Poon, A. (2007). Bayesian predictive power for interim adaptation in seamless phase ii/iii trials where the endpoint is survival up to some specified timepoint. Statistics in Medicine, 26(27), 4925–4938. https://doi.org/10.1002/(ISSN)1097-0258
- Spiegelhalter, D. J., Abrams, K. R., & Myles, J. P. (2004). Bayesian approaches to clinical trials and health-care evaluation. Wiley.
- Spiegelhalter, D. J., Freedman, L. S., & Blackburn, P. R. (1986). Monitoring clinical trials: conditional or predictive power?. Controlled Clinical Trials, 7(1), 8–17. https://doi.org/10.1016/0197-2456(86)90003-6
- Trzaskoma, B., & Sashegyi, A. (2007). Predictive probability of success and the assessment of futility in large outcomes trials. Journal of Biopharmaceutical Statistics, 17(1), 45–63. https://doi.org/10.1080/10543400601001485
- Tsiatis, A. A. (1981). The asymptotic joint distribution of the efficient scores test for the proportional hazards model calculated over time. Biometrika, 68(1), 311–315. https://doi.org/10.1093/biomet/68.1.311
- Wang, S. J., Hung, H. M. J., & O'Neill, R. T. (2006). Adapting the sample size planning of a phase iii trial based on phase ii data. Pharmaceutical Statistics, 5(2), 85–97. https://doi.org/10.1002/(ISSN)1539-1612
- Zhang, J., Carlin, B. P., Neaton, J. D., Soon, G. G., Nie, L., Kane, R., Virnig, B. A., & Chu, H. (2014). Network meta-analysis of randomized clinical trials: reporting the proper summaries. Clinical Trials, 11(2), 246–262. https://doi.org/10.1177/1740774513498322
- Zhang, Y. Y., Rong, T. Z., & Li, M. M. (2020a). The contemplated average success probability for normally distributed models with an application to optimal sample sizes selection. Statistics in Medicine, 39(23), 3173–3183. https://doi.org/10.1002/sim.v39.23
- Zhang, Y. Y., Rong, T. Z., & Li, M. M. (2020b). A new expectation identity and its application in the calculations of predictive powers assuming normality. Chinese Journal of Applied Probability and Statistics, 36(5), 523–535. https://doi.org/10.3969/j.issn.1001-4268.2020.05.007
- Zhang, Y. Y., & Ting, N. (2018). Bayesian sample size determination for a phase iii clinical trial with diluted treatment effect. Journal of Biopharmaceutical Statistics, 28(6), 1119–1142. https://doi.org/10.1080/10543406.2018.1436556
- Zhang, Y. Y., & Ting, N. (2020). Sample size considerations for a phase iii clinical trial with diluted treatment effect. Statistics in Biopharmaceutical Research, 12(3), 311–321. https://doi.org/10.1080/19466315.2019.1599414