
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A regression model with skew-normal errors provides a useful extension for traditional normal regression models when the data involve asymmetric outcomes. Moreover, data that arise from a heterogeneous population can be efficiently analysed by a finite mixture of regression models. These observations motivate us to propose a novel finite mixture of median regression model based on a mixture of the skew-normal distributions to explore asymmetrical data from several subpopulations. With the appropriate choice of the tuning parameters, we establish the theoretical properties of the proposed procedure, including consistency for variable selection method and the oracle property in estimation. A productive nonparametric clustering method is applied to select the number of components, and an efficient EM algorithm for numerical computations is developed. Simulation studies and a real data set are used to illustrate the performance of the proposed methodologies.
1. Introduction
When the data involve asymmetrical outcomes, inference under the linear regression model with the skewed random errors can be viewed as an alternative procedure to the classical regression models with symmetric errors, since the use of a skewed distribution for the errors could reduce the influence of outliers and thus make statistical analysis more robust. Specifically, suppose that a response variable Y given a set of predictors takes the form of
(1)
(1) where
represents a vector of the unknown regression coefficients and the conditional density of the error term ϵ given
follows an unknown distribution with the probability density function (pdf)
. It is known that if
is symmetrical about 0, the estimation of β in (Equation1
(1)
(1) ) will be the same as the coefficients obtained by conventional mean linear regression. However, if
is skewed, the median regression provides a more reliable statistical analysis with adaptive robustness to outliers, since the median of a distribution is less susceptible to outliers, especially when the data involve asymmetrical outcomes. We here refer the interested readers to Kottas and Gelfand (Citation2001), Zhou and Liu (Citation2016) and Hu et al. (Citation2019) for relevant research on the median regression of population distributions.
It is noteworthy to mention that the median regression has been widely used for studying the relationship between the response variable Y and a set of predictors in symmetrical distribution, whereas such a median regression may not be suitable for analysing the data exhibiting asymmetrical behaviour or the data that arise from a heterogeneous population. To tackle this difficulty, mixture of regression models (known as switching regression models in econometrics), initially introduced by Goldfeld and Quandt (Citation1973), may be employed as a flexible tool for studying the skewed data from two or more subpopulations. Since then, finite mixture of regression (FMR) models has been widely used in a variety of fields including but not limited to biology, medicine, economics, environmental science, sampling survey and engineering technology. The book by McLachlan and Peel (Citation2004) contains a comprehensive review of FMR models. An FMR model is obtained when a response variable with a finite mixture distribution depends on a set of covariates, and FMR models have been discussed extensively when the normality is assumed for the regression error in each component.
However, it has been shown that the commonly used normal mixture model tends to be an over fitting model, since additional components are usually needed to capture the skewness of the data. To overcome the potential inappropriateness of normal mixtures in some context, we may consider the use of the skew-normal distributions (Azzalini, Citation1985) as component densities of the errors; see, for example, Wu et al. (Citation2013), Wu (Citation2014), Tang and Tang (Citation2015), and H. Li et al. (Citation2016, Citation2017), to name just a few. These observations motivate us to develop a novel finite mixture of the median regression (FMMeR) model based on a mixture of the skew-normal distributions to explore asymmetrical data that arise from several subpopulations. There exist two barriers for the development of the FMMeR model. The first barrier is to deal with computational aspects of parameter estimation when fitting the FMMeR model with the skew-normal distribution for the errors. We tackle this barrier by utilizing the stochastic representation and hierarchical representation (see, for example, Liu & Lin, Citation2014) of skew-normal mixtures. A second technical barrier is to determine the number of components of the FMMeR model under consideration. Popularly, the log-likelihood maximum and two information-based criteria, AIC (Akaike, Citation1973) and BIC (Schwarz, Citation1978), can be used to select the number of components. Although some success has been shown using the model choice criteria, choosing the right number of components for a mixture model is known to be difficult. Thus, we consider a procedure of clustering to determine the number of components, which has been shown to be very effective via real-data example, and it is introduced in Subsection 5.3.
To enhance predictability and to give a concise model, it is reasonable to include only the significant covariates in the model. As a result, variable selection has also become increasingly important for FMR models and a rich literature has been generated in recent several decades. All-subset selection methods, such as the AIC and BIC, and their modifications, have been widely investigated in the context of FMR models; for instance, P. Wang et al. (Citation1996) researched model selection in a finite mixture of Poisson regression models via AIC and BIC. However, all-subset selection methods for FMR models are computationally intensive. To improve computational efficiency, the least absolute shrinkage and selection operator (LASSO) of Tibshirani (Citation1996) and the smoothly clipped absolute deviation (SCAD) method of Fan and Li (Citation2001) are proposed as new methods for variable selection. The penalized likelihood for FMR models, the extension of penalized least square methods, were proposed by Khalili and Chen (Citation2007). Recently, Wu et al. (Citation2020) proposed an estimation and variable selection method for mixture of joint mean and variance models; Yin, Wu, and Dai (Citation2020) proposed variable selection procedures in FMR models using the skew-normal distribution.
The remainder of this paper is organized as follows. In Section 2, we briefly introduce the skew-normal distribution and its median expression. In Section 3, we develop a variable selection method for FMMeR model via the penalized likelihood-based procedure for analysing asymmetrical data from several subpopulations. Section 4 studies asymptotic properties of the resulting estimators. In Section 5, a numerical algorithm, a productive nonparametric clustering method for determining the number of components and a data-adaptive method for choosing tuning parameters are discussed. In Section 6, we carry out simulation studies to investigate the finite sample performance of the proposed methodology. A real-data example is provided in Section 7 for illustrative purposes. Some concluding remarks are given in Section 8. Brief proofs of theorems and some technical derivations are given in Appendices 1 and 2.
2. The skew-normal mixture of median regression models
2.1. Skew-normal distribution
A random variable Y is said to follow a univariate skew-normal distribution with location parameter μ, scale parameter and skewness parameter
, denoted by
, if its pdf is given by
(2)
(2) where
and
denote the pdf and cumulative distribution function (cdf) of the standard normal distribution, respectively. It is worth noting that if
, the density of Y reduces to a normal density
and that the distribution is positively skewed if
and is negatively skewed if
.
We represent the skew-normal distribution in an incomplete data framework. Specifically, the stochastic representation for random variable is given by
(3)
(3)
where with a sample size of n,
. Here,
and
, where
and
are independent.
is a truncated normal distribution with the density
where
and
represents an indicator function. For notational simplicity, let
and
. Furthermore, the skew-normal distribution can be decomposed into a normal distribution and a truncated normal distribution by a hierarchical representation given by
(4)
(4) Azzalini and Capitanio (Citation2013) adopted the moment-generating function to calculate the mean and variance for the skew-normal distribution in (Equation2
(2)
(2) ) and they are given by
(5)
(5) respectively, where
and
. Of particular note is that Lin et al. (Citation2007) introduced a simple way of obtaining higher moments of the skew-normal distribution without the use of its moment-generating function. Letting
be the mode of the distribution
, a quite accurate approximation of
evaluated by the numerical maximization method is given by
where
indicates the sign function for λ and
It deserves mentioning that the logarithm of the density for the skew-normal distribution is a concave function and that this property is not altered by a change of location and scale parameters. Thus,
is unique and the mode of the skew-normal distribution in (Equation2
(2)
(2) ) can be reexpressed as
. Mean(Y), Mode(Y) and Median(Y) have the quantitative relationship when the observations follow a skew-normal distribution:
, that is,
(6)
(6) which could facilitate the development of the median regression with the skew-normal mixtures discussed below.
2.2. Median regression for skew-normal mixtures
In this paper, we assume that the response variable follows a skew-normal distribution with location parameter
, scale parameter σ and skewness parameter λ, denoted by
for
. A linear mode regression model with skew-normal errors can be expressed as
(7)
(7) where
defined by (Equation6
(6)
(6) ). Here
is a
design matrix, such that each of its element
is the p-dimensional vector of predictors, and
is a p-dimensional vector of the unknown regression coefficients, and
stands for the n-dimensional vector of random errors such that
.
We consider the case where the data from heterogeneous populations. A finite mixture median regression (FMMeR) model with m-components of the skew-normal distributions is defined as
(8)
(8) where
are the mixing proportions which are constrained to be non-negative and sum to unity,
and
. It is obvious that
(9)
(9) which shows that the location in the FMMeR model is altered by a change of scale and skewness parameters.
2.3. Identifiability
An important part associated with statistical inference for FMR models is their identifiability. It is well known that mixture models are not absolutely identifiable in general. However, in some mixture model settings, it is possible to establish a weaker sense of identifiability. Titterington et al. (Citation1985) have given relevant conclusions that the FMR models of continuous distribution are identifiable in most cases. Otiniano et al. (Citation2015) introduced the identifiability of finite mixture of skew-normal distribution and gave detailed explanation. The cumulative distribution function of Y is denoted by . It is possible to define the skew-normal family as the set
and
as the class of finite mixture of skew-normal distributions. The class
of all finite mixtures of
is identifiable if and only if for any
,
The equality
implies
and
are a permutation of
. The following theorem given by Atienza et al. (Citation2006) gives a sufficient condition for the identifiability of finite mixtures of distributions.
denotes the accumulation set of A.
Theorem 2.1
Atienza et al., Citation2006
Let be a family of distributions. Let M be a linear mapping which transforms any
into a real function
with domain
. Let
. Suppose that there exists a total order ≺ on
, such that for any
there exists a point
verifying
if
,with
if
Then, the class of all finite mixture distributions of
is identifiable.
3. The method for variable selection
Various classical variable selection criteria can be considered as tradeoffs based on the estimation variance and modelling biases of penalized likelihood. The density is functionally independent of the parameters as an assumption in FMMeR model when
is random. Hence, the variable selection can be done based absolutely on the conditional density function specified in (Equation2
(2)
(2) ). Denote
as a sample of observations from FMMeR model specified in (Equation8
(8)
(8) ). The log-likelihood function of
is given by
A maximum likelihood estimate (MLE) is obtained via maximizing
. The MLE is often close to, but not strictly equal to 0 when a component of
is not important. Thus, this covariate is not excluded from the model. To address this problem, according to Khalili and Chen (Citation2007), we define a penalized log-likelihood function as
(10)
(10) with the penalty function
where
is a given penalty function with the tuning parameter
, and the tuning parameters and the penalty functions are not necessarily the same for all the parameters. A data-driven criterion for determining tuning parameters is introduced in Subsection 5.2. By choosing appropriate tuning parameters and maximizing function
in (Equation10
(10)
(10) ) to obtain penalized maximum likelihood estimator of
, denoted by
, the coefficients in the vicinity of 0 are compressed to 0 and automatically excluded. Thus, the procedure combines the parameter estimation and variable selection and reduces the computational burden substantially. We use the following three penalty functions to illustrate the theory that we develop for the FMMeR model:
Following the idea of Fan and Li (Citation2001), we set a = 3.7 for application purposes in this article. The LASSO penalty has a good performance in numerical computation because of its convex property. The SCAD penalty gives a good performance in selecting important variables. HARD penalty should work more like SCAD, although less smoothly.
4. Asymptotic properties
In this section, we consider the consistency for variable selection method and the oracle property in estimation. Without loss of generality, the coefficient vector of the j-th component is decomposed into
, where
and
contain the nonzero effects and zero effects of
, respectively. Naturally, we also split the parameter
such that
contains all zero effects, that is,
in the true model. The vector of true parameters is denoted as
. The components of
are denoted with a superscript, namely
, where
is the t-th component of
. Let
denote the number of nonzero elements
of the subvector
for each j. Let
where
and
.
and
are the first and second derivatives of the penalty function
with respect to
, respectively. The asymptotic results obtained in this article are based on the three conditions on the penalty functions
.
| C0: | For all j, | ||||
| C1: | As | ||||
| C2: | For all j and | ||||
Condition is used to explain the asymptotic properties of the estimators of nonzero effects. Conditions
and
are required for sparsity.
Theorem 4.1
Consistency
Let ,
, be a random sample from a density function
that satisfies the regularity conditions
–
in the Appendix 1. The penalty functions
satisfy conditions
and
as a assumption. Then there exists a local maximizer
of the penalized log-likelihood function
for which
where
represents the Euclidean norm.
Theorem 4.2
Oracle property
Assume that the conditions given in Theorem 4.1 are fulfilled. The penalty functions satisfy conditions
–
, and m is known in parts (a) and (b). We then have the following.
For any
For any
sparity:
asymptotic normality:
Brief proofs of theorems are put in Appendix 1. Detailed proofs can be seen in the previous literature (see, for example, Fan & Li, Citation2001; Khalili & Chen, Citation2007; Yin, Wu, & Dai, Citation2020).
5. Numerical computations
5.1. Maximization algorithm
In general, due to the unboundedness of the likelihood function, the maximum likelihood estimator of the mixture distribution is often inconsistent in the context of finite mixture models. The alternative is to add a regular term that prevents the likelihood function from tending to infinity to get a consistent maximum penalty likelihood estimator, see, for example, Chen and Tan (Citation2009), Chen (Citation2017), including recent works, Chen et al. (Citation2020), He and Chen (Citation2022a, Citation2022b). McLachlan and Peel (Citation2004) proposed that the EM algorithm can calculate the maximum likelihood estimation of arbitrary distribution in finite mixture model. We maximize the regularized log-likelihood function by the EM algorithm. We define the latent component-indicators with
,
. Then
is an m-dimensional indicator vector with its j-th element given by
Since an observation cannot simultaneously belong to both components, we have
. By assuming the component-indicators
to be independent, we obtain a conditional density of the multinomial distribution given the mixing probabilities
(11)
(11) which is denoted as
, and it will be used in combination with (Equation3
(3)
(3) ) to generate the following hierarchical representation for the skew-normal mixtures, such that
(12)
(12) It deserves mentioning that the hierarchical representation of the finite skew-normal mixtures in (Equation12
(12)
(12) ) allows us to address computational barriers of the parameter estimation when fitting the FMMeR model. Let
be the observed data. For each
, we use the latent variables
and
to form the complete data
, where
denotes the missing data. From hierarchical representation (Equation12
(12)
(12) ), the complete data log-likelihood function can be given by
(13)
(13) Similar to the approach in Fan and Li (Citation2001),
is replaced by the following local quadratic function given the value
,
This approximation is used in the M-step of the EM algorithm in each iteration. The complete penalized log-likelihood function of (Equation10
(10)
(10) ) can be given by
(14)
(14) • E-step. The E-step computes the conditional expectation of the function
with respect to
. Given the observed data
from FMMeR model (Equation8
(8)
(8) ),
is denoted as parameter estimation for k-th iteration. Let
. Then the surrogate function can be constructed as
(15)
(15) where
The required conditional expectations are obtained as follows. First, the conditional expectation
is given by
(16)
(16) Then, it can be easily shown that
• M-step. The M-step calculates parameter vector
via maximizing
with respect to
. Thus, on the
-th iteration of the EM algorithm, the mixing proportions are updated by
(17)
(17) It is worth noting that the mixing proportions modelling should be considered in mixture of experts regression models, which can be found in Yin, Wu, Lu, et al. (Citation2020). To improve the efficiency for selecting the number of components in real data analysis for this article, we firstly applied a clustering method to determine the optimal number of components in Subsection 5.3. By maximizing
with respect to
without
, namely maximizing
, we can compute
. To obtain parameter estimation of FMMeR model without penalty, start from an initial value
and given k as the current iteration. We use the following method to update
(18)
(18) where
is referred to as score function without penalty.
is an observation information matrix defined as
Detailed derivation can be seen in Appendix 2. We iterate between the E-steps and M-steps until algorithm converges, and the estimators
are obtained.
In order to find the non-significant variables and simplify the FMMeR model, we shrink the coefficients by the penalty function. is taken as the initial value of iteration and given k as the current iteration, update
with
5.2. Choice of the tuning parameters
The degree of penalty is controlled by tuning parameters. When using the method introduced in this article, we need to choose the tuning parameters. Various selection criteria, including cross-validation (CV), generalized cross-validation (GCV), Akaike information criterion (AIC) (Akaike, Citation1973) and Bayesian Information Criterion (BIC) (Schwarz, Citation1978), are often used for choosing tuning parameters. GCV has a non-negligible overfitting effect in the final model selection. H. Wang et al. (Citation2007) suggested using BIC for the SCAD estimator in linear models and partially linear models and proved the consistency of the selection method, that is, the optimal parameter chosen by BIC can identify the true model with probability tending to 1. Considering the maximizer of the log-likelihood function (Equation13
(13)
(13) ), we use the estimator
to calculate the mixing proportions in (Equation17
(17)
(17) ). The mixing proportions remain fixed throughout the tuning parameter selection process. For a given value of tuning parameter
, let
be the maximum regularized likelihood estimates of the parameters in the j-th component of the FMMeR model fixing the remaining elements of
at
. Denote the likelihood-based deviance statistics, evaluated at
, corresponding to the j-th component of FMMeR model as
where
and the weights
are given in (Equation16
(16)
(16) ). Then we define
where
is the number of nonzero elements of the vector
and
. It is expected that the choice of
should be such that the tuning parameter for a zero coefficient is larger than that for a nonzero coefficient. Thus, we can simultaneously unbiasedly estimate the larger coefficient, and shrink the small coefficient towards zero. Hence, similar to Wu et al. (Citation2013), we suggest
where
is the MLE of
.
,
are the t-th component of
and
, respectively. Tuning parameters are obtained via calculating
5.3. Determining the number of components
Determining the number of components of an FMR model is a challenge. In the above discussion, we assume that m is known and processing methods are either based on prior information or pre-analysis of data. A feasible method implements reversible jump Markov chain Monte Carlo (RJMCMC) Richardson and Green (Citation1997), since adding skewness even complicates matters, we did not pursue RJMCMC. Moreover, the component posterior probabilities evaluated in mixture modelling for Bayesian inference can be readily used as a soft clustering scheme. Alternatively, the log-likelihood maximum and two information-based criteria, AIC and BIC, can be used to select the number of components. Although some success has been shown using the model choice criteria, choosing the right number of components for a mixture model is known to be difficult.
To improve the efficiency for selecting the number of components in this article, a productive nonparametric clustering method via mode identification is applied, see J. Li et al. (Citation2007). It deserves mentioning that this approach is robust in high dimensions and when clusters deviate substantially from Gaussian distributions. Specifically, a cluster is formed by those sample points that ascend to the same local maximum of the density function, and a pairwise separability measure for clusters is defined using the Ridgeline between the density bumps of two clusters. In this process, the Modal EM (MEM) algorithm and Ridgeline EM (REM) algorithm are used. Numerical results in Section 7 illustrated that this clustering procedure works well for determining the number of components in the FMMeR model.
6. Numerical experiments
In this section, we carry out simulation studies to investigate the finite sample performance of the proposed methodology. To be more specific, in Subsection 6.1, we conduct simulations to study the impact of the sample size on the estimation quality, and in Subsection 6.2, we investigate the quality of the performance for variable selection over different values of the skewness, and we compare the performance of the proposed FMMeR model and NMR model used in Khalili and Chen (Citation2007) in Subsection 6.3.
6.1. Experiments 1
The experiment works to observe the impact of the sample size on the estimation quality. In addition, we compare the performance of different variable selection methods from a number of angles. We generated independently samples of size n from the following FMMeR model with two components,
(19)
(19) where
and
are defined by (Equation9
(9)
(9) ), and
. The components of the covariate
in the simulation are generated from a uniform distribution
. The true values of parameters are set to be
,
,
. To test the sensitivity of the FMMeR model for positively or negatively skewed data, we set
and
. A choice of mixing proportion
and 0.35 is considered, and y is generated according to model (Equation19
(19)
(19) ). According to Karlis and Xekalaki (Citation2003), a faster convergence rate can be achieved by setting the true value of the parameter to the initial value of the iteration. The performance of the estimators
,
,
and
will be assessed using the Mean Squared Error (MSE), defined as
The average numbers of correctly (C) and incorrectly (IC) estimated zero coefficients and their standard deviation (SD) based on 500 repetitions are presented in Table . The results are presented in terms of mixture components 1 and 2. In addition, we report the MSEs and SD of scale, skewness and mixing proportion for
across the repetitions in Table . Note that when the sample size n increases, as expected, the methods improve for a given penalty. The MSEs of estimators
,
,
and
tend to decrease by increasing the sample size, which illustrates the convergence property of the maximum penalized likelihood estimator of FMMeR model. For a given n, the performances of SCAD and HARD methods are similar for model complexity and better than LASSO method. When mixing proportion
reduces, and the sample size for component 1 decreases, all procedures for the component 1 of the FMMeR model become less satisfactory. Furthermore, the performances of component 1 and component 2 are similar for
, which indicates that FMMeR model is insensitive to positively or negatively skewed data.
Table 1. Three penalty functions are used for variable selection procedure.
Table 2. Simulation results of the parameters of scale, skewness and mixing proportion for =0.5.
6.2. Experiments 2
To investigate how the estimation quality is changed over different skewness, in this section, we set mixing proposition and the number of observations n = 400. Observations are generated in the same way as in Experiment 1. Table shows C, IC, MSE
and their SD for different penalty function with
for 500 repetitions. Notice that the variable selection procedures perform similarly in all three cases for a given penalty function, but a larger SD is obtained by LASSO. When combined with the relevant conclusions of Experiment 1, the result indicates that the performance of the variable selection method is not affected by the choice of skewness of data.
Table 3. Varying skewness with n = 400 and .
6.3. Experiments 3
To demonstrate the ability of the proposed variable selection method at selecting important variables, we compare the performance of the proposed FMMeR model and NMR model used in Khalili and Chen (Citation2007) for a varying sample size n = 200, 400 and . The data are generated exactly in the same way as in Experiment 1, and each of the two models is considered for the inference. The simulated results are reported in Table based on 500 repetitions. From Table , it is clear that the performance of the variable selection procedure based on the FMMeR model is better than that based on the NMR model in some settings. This confirms that the FMMeR model clearly outperforms the NMR model at identifying important variables when there is skewness in the data. As expected, the MSEs indicate the convergence property of the maximum penalized likelihood estimator of FMMeR and NMR models.
Table 4. Varying sample size n with ,
and
.
7. A real-data example
FMR models have been used in the fields of biomedicine. To further demonstrate the ability of the proposed FMMeR model and variable selection method at identifying significant variables, we use a real-data example to illustrate the practical application of the proposed method of the FMMeR model in this section. The data set, analysed by Cook and Weisberg (Citation1994), focused on the body mass index (BMI) for 102 male and 100 female athletes collected at Australian Institute of Sport. We are interested in the relationship between BMI and the 10 performance measures given as red cell count , white cell count
, haematocrit
, haemoglobin
, plasma ferritin concentration
, sum of skin folds
, body fat percentage
, lean body mass
, height
and weight
.
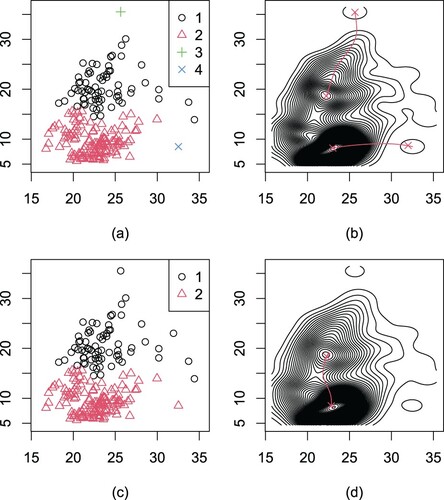
It can be seen from the histogram of the BMI in Figure that the response is right-skewed, indicating the preference of the model with the skew-normal random errors. We determine the number of components via the method in Subsection 5.3. The clustering results are shown in Figure . At the level 3, 4 clusters are formed, as shown by different symbols in Figure (a). The 4 modes identified at level 3 are merged into 2 modes at level 4, as shown in Figure (b,d). Compared with level 4, two influential observations were excluded in cluster 1 and cluster 2 of level 3. Thus, it seems reasonable to use the following FMMeR model with two components to fit the BMI data,
(20)
(20) where
and
are defined by (Equation9
(9)
(9) ), and
.
is a
vector consisting of all 10 potential variables. Three penalty functions are used to select significant variables.
Figure 1. Histogram of the BMI.
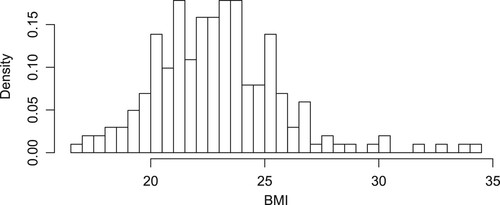
Figure 2. Clustering results for the BMI data obtained. (a) The 4 clusters at level 3. (b) The ascending paths from the modes at level 3 to those at level 4 and the contours of the density estimate at level 4. (c) The 2 clusters at level 4. (d) The ascending paths from the modes at level 4 to the next level and the contours of the density estimate at the next level.
We compare the variable selection results of the three models, including the proposed FMMeR model in this article, finite mixture of modal liner regression model and NMR model, where modal liner regression (MODLR) model was proposed by Yao and Li (Citation2014). The results of variable selection for three models are given in Tables . In this data example, three variable selection procedures for a given model perform very similarly in terms of selecting significant variables. For FMMeR model and finite mixture of MODLR model, the same variables are removed for a given penalty function. NMR model, however, reserves more variables, resulting in a failure to select significant variables. Thus, the true structure of the model is not identified. When there is a situation of skewed data, the performances of HARD and SCAD are better than LASSO for identifying the authentic structure of the model. In FMMeR model, seven significant variables, including ,
,
,
,
,
,
, are identified in component 1. Also seven
,
,
,
,
,
,
are contained in component 2. This indicates that these variables have a significant effect for BMI of athletes. We also find that there are some variables having different effects on parts one and two. For instance, red cell count
and sum of skin folds (
) are another factors affecting athletes' BMI in component 1 and component 2, respectively. Furthermore,
,
,
and
are helpful for achieving a high BMI in two conponents. In addition, the performance of the variable selection procedure via the FMMeR model is different from that of the variable selection procedure via the NMR model.
Table 5. Variable selection for BMI data set via FMMeR model.
Table 6. Variable selection for BMI data set via finite mixture of MODLR model.
Table 7. Variable selection for BMI data set via NMR model.
8. Conclusions remarks and future works
In this paper, by utilizing the skew-normal distribution as a component density to overcome the potential inappropriateness of normal mixtures in some context, we have developed a novel finite mixture of the median regression (FMMeR) model to explore asymmetrical data that arise from several subpopulations. Thanks to the stochastic representation for the skew-normal distribution, we have constructed a hierarchical representation of the finite skew-normal mixtures to address computational barriers of the parameter estimation and variable selection when fitting the FMMeR model. In addition, in order to determine the number of components, we applied a clustering method via mode identification proposed by J. Li et al. (Citation2007) and a good performance is shown. Numerical results from simulation studies and a real-data example illustrated that the proposed FMMeR model methodology performs well in general, even when the data exhibit symmetrical behaviour.
It is worth noting that we only considered the procedures of parameter estimation and variable selection for the FMMeR model based on a mixture of the skew-normal distributions. Meanwhile, the scenario of p>n has not been considered in this paper. A natural extension of the proposed methodology is to consider other skewed distributions, such as the skew-t and skew-Laplace distributions, and high-dimensional settings. In addition, another research direction is to model the mixing proportions , which extends the proposed model to the framework of mixture of experts models. Finally, it will also be of interest to consider Bayesian variable selection, semi-parametric and nonparametric methods for the FMMeR model, which are currently under investigation and will be reported elsewhere.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle. International Symposium on Information Theory, 1, 610–624. https://doi.org/10.1007/978-1-4612-1694-0_15
- Atienza, N., Garcia-Heras, J., & Muñoz-Pichardo, J. (2006). A new condition for identifiability of finite mixture distributions. Metrika, 63(2), 215–221. https://doi.org/10.1007/s00184-005-0013-z
- Azzalini, A. (1985). A class of distributions which includes the normal ones. Scandinavian Journal of Statistics, 12(2), 171–178. http://www.jstor.org/stable/4615982
- Azzalini, A., & Capitanio, A. (2013). The skew-normal and related families. Cambridge University Press.
- Chen, J. (2017). Consistency of the MLE under mixture models. Statistical Science, 32(1), 47–63. https://doi.org/10.1214/16-sts578
- Chen, J., Li, P., & Liu, G. (2020). Homogeneity testing under finite location-scale mixtures. Canadian Journal of Statistics, 48(4), 670–684. https://doi.org/10.1002/cjs.11557
- Chen, J., & Tan, X. (2009). Inference for multivariate normal mixtures. Journal of Multivariate Analysis, 100(7), 1367–1383. https://doi.org/10.1016/j.jmva.2008.12.005
- Cook, R.-D., & Weisberg, S. (1994). An introduction to regression graphics. John Wiley and Sons.
- Fan, J., & Li, R. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association, 96(456), 1348–1360. https://doi.org/10.1198/016214501753382273
- Goldfeld, S., & Quandt, R. (1973). A Markov model for switching regressions. Journal of Econometrics, 1(1), 3–15. https://doi.org/10.1016/0304-4076(73)90002-X
- He, M., & Chen, J. (2022a). Consistency of the MLE under a two-parameter gamma mixture model with a structural shape parameter. Metrika. https://doi.org/10.1007/s00184-021-00856-9
- He, M., & Chen, J. (2022b). Strong consistency of the MLE under two-parameter gamma mixture models with a structural scale parameter. Advances in Data Analysis and Classification, 16(1), 125–154. https://doi.org/10.1007/s11634-021-00472-5
- Hu, D., Gu, Y., & Zhao, W. (2019). Bayesian variable selection for median regression. Chinese Journal of Applied Probability and Statistics, 35(6), 594–610.
- Karlis, D., & Xekalaki, E. (2003). Choosing initial values for the EM algorithm for finite mixtures. Computational Statistics & Data Analysis, 41(3–4), 577–590. https://doi.org/10.1016/S0167-9473(02)00177-9
- Khalili, A., & Chen, J. (2007). Variable selection in finite mixture of regression models. Journal of the American Statistical Association, 102(479), 1025–1038. https://doi.org/10.1198/016214507000000590
- Kottas, A., & Gelfand, A. (2001). Bayesian semiparametric median regression modeling. Journal of the American Statistical Association, 96(456), 1458–1468. https://doi.org/10.1198/016214501753382363
- Li, H., Wu, L., & Ma, T. (2017). Variable selection in joint location, scale and skewness models of the skew-normal distribution. Journal of Systems Science and Complexity, 30(3), 694–709. https://doi.org/10.1007/S11424-016-5193-2
- Li, H., Wu, L., & Yi, J. (2016). A skew-normal mixture of joint location, scale and skewness models. Applied Mathematics-A Journal of Chinese Universities, 31(3), 283–295. https://doi.org/10.1007/S11766-016-3367-2
- Li, J., Ray, S., & Lindsay, B.-G. (2007). A nonparametric statistical approach to clustering via mode identification. Journal of Machine Learning Research, 8(8), 1687–1723.
- Lin, T.-I., Lee, J., & Yen, S. (2007). Finite mixture modelling using the skew normal distribution. Statistica Sinica, 17(3), 909–927. http://www.jstor.org/stable/24307705
- Liu, M., & Lin, T.-I. (2014). A skew-normal mixture regression model. Educational and Psychological Measurement, 74(1), 139–162. https://doi.org/10.1177/0013164413498603
- McLachlan, G., & Peel, D. (2004). Finite mixture models. John Wiley and Sons.
- Otiniano, C. E. G., Rathie, P. N., & Ozelim, L. C. S. M. (2015). On the identifiability of finite mixture of skew-normal and skew-t distributions. Statistics & Probability Letters, 106, 103–108. https://doi.org/10.1016/j.spl.2015.07.015
- Richardson, S., & Green, P. (1997). On bayesian analysis of mixtures with an unknown number of components (with discussion). Journal of the Royal Statistical Society: Series B (Statistical Methodology), 59(4), 731–792. https://doi.org/10.1111/1467-9868.00095
- Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464. https://doi.org/10.1214/AOS/1176344136
- Tang, A., & Tang, N. (2015). Semiparametric Bayesian inference on skew-normal joint modeling of multivariate longitudinal and survival data. Statistics in Medicine, 34(5), 824–843. https://doi.org/10.1002/SIM.6373
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B. Statistical Methodology, 58(1), 267–288. https://doi.org/10.1111/J.2517-6161.1996.TB02080.X
- Titterington, D., Smith, A., & Makov, U. (1985). Statistical analysis of finite mixture distributions. John Wiley and Sons
- Wang, H., Li, R., & Tsai, C. (2007). Tuning parameter selectors for the smoothly clipped absolute deviation method. Biometrika, 94(3), 553–568. https://doi.org/10.1093/BIOMET/ASM053
- Wang, P., Puterman, M., Cockburn, I., & Le, N. (1996). Mixed Poisson regression models with covariate dependent rates. Biometrics, 52(2), 381–400. https://doi.org/10.2307/2532881
- Wu, L. (2014). Variable selection in joint location and scale models of the skew-t-normal distribution. Communications in Statistics. Simulation and Computation, 43(3), 615–630. https://doi.org/10.1080/03610918.2012.712182
- Wu, L., Li, S., & Tao, Y. (2020). Estimation and variable selection for mixture of joint mean and variance models. Communications in Statistics-Theory and Methods, 50(24), 6081–6098. https://doi.org/10.1080/03610926.2020.1738493
- Wu, L., Zhang, Z., & Xu, D. (2013). Variable selection in joint location and scale models of the skew-normal distribution. Journal of Statistical Computation and Simulation, 83(7), 1266–1278. https://doi.org/10.1080/00949655.2012.657198
- Yao, W., & Li, L. (2014). A new regression model: Modal linear regression. Scandinavian Journal of Statistics, 41(3), 656–671. https://doi.org/10.1111/SJOS.12054
- Yin, J., Wu, L., & Dai, L. (2020). Variable selection in finite mixture of regression models using the skew-normal distribution. Journal of Applied Statistics, 47(16), 2941–2960. https://doi.org/10.1080/02664763.2019.1709051
- Yin, J., Wu, L., Lu, H., & Dai, L. (2020). New estimation in mixture of experts models using the Pearson type VII distribution. Communications in Statistics. Simulation and Computation, 49(2), 472–483. https://doi.org/10.1080/03610918.2018.1485943
- Zhou, X., & Liu, G. (2016). LAD-Lasso variable selection for doubly censored median regression models. Communications in Statistics. Theory and Methods, 45(12), 3658–3667. https://doi.org/10.1080/03610926.2014.904357
Appendices
Appendix 1. Regularity conditions and proofs
Regularity conditions on the joint distribution of
are needed for proving the asymptotic properties of the proposed method. Let
be the joint density function of h with the parameter space
. We write
and s is the total number of parameters in the FMMeR model. The regularity conditions are as follows.
| R1: | The density | ||||
| R2: | There exists an open subset | ||||
| R3: | For each | ||||
| R4: | The Fisher information matrix,
| ||||
Proof
Proof of Theorem 4.1
Let . We just have to specify that for any given
, there exists a large constant C such that
(A1)
(A1) This indicates that for sufficiently large n, with large probability namely
, there is a localmaximum in the ball
. This localmaximizer, say
, satisfies
.
Let . Using
and the definition of
, we have
where
is the number of nonzero elements of the vector
.
is the parameter vector with zero regression coefficients removed and
is a subvector of
with corresponding components. By Taylor's expansion and the triangular inequality
(A2)
(A2) Regularity conditions imply that
and Fisher informationmatrix
is positive definite. Thus,
is of the order
. By choosing a sufficiently large C,
is controlled uniformly by
in
. Note that the
is bounded by
where
. By condition
for the penalty functions,
, this is also dominated by the
. Hence, by choosing a sufficiently large C, (EquationA1
(A1)
(A1) ) holds. This completes the proof.
Proof
Proof of Theorem 4.2
To prove part (a), consider the partition for any
in the neighbourhood
. By the definition of
, we obtain
By the mean value theorem,
(A3)
(A3) with
. Furthermore, by using regularity condition
and the mean value theorem, we have
By the regularity conditions
–
,
. Thus,
. Applying these order assessments to (EquationA3
(A3)
(A3) ), we obtain
for large n. On the other hand,
Thus,
In a shrinking neighbourhood of 0,
in probability by condition
. This completes the proof of part (a).
To prove sparsity in part (b(1)), we consider the partition . Let
be the maximizer of the penalized log-likelihood function
, which is considered as a function of
. It suffices to show that in the neighbourhood
,
with probability tending to 1 as
. By the result in part (a), we obtain that
To prove asymptotic normality in part (b(2)), we consider
as a function of
. Using the same argument as in Theorem 4.1, there exists a
-consistent local maximizer of this function, denoted by
, that satisfies
By substituting the first-order Taylor's expansions of
and
into the above expression, we have
On the other hand, under the regularity conditions, we obtain
and
Using the foregoing facts and Slutsky's theorem, we have
which is the result in part (b(2)).
Appendix 2. Some technical derivations
In (5.9), the score function of j-th component is expressed as
is defined as
where
with
. Thus, we have
and