
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article continues the works of references to improve and perfect the sampling theorem of exponential distribution. First, the distribution of the sample range of exponential distribution is derived, and that the sample range is mutually independent of the sample minimum is proven. Then, this article derives the distribution of the difference between sample maximum and mean and demonstrates that the difference of these two statistics is mutually independent of the sample minimum. Thus, three local minimum variance unbiased estimators of the mean could be constructed. The estimator built by sample minimum and the difference between sample mean and minimum is precisely the uniformly minimum-variance unbiased estimator (UMVUE) of the mean. Similarly, three local minimum variance unbiased estimators of the variance are derived. At last, the efficiency comparison is made among the above three local minimum variance unbiased estimators of mean and variance of the exponential distribution.
PUBLIC INTEREST STATEMENT
What is the sampling theorem of the exponential distribution? It includes the content about the distributions of the sample mean, sample maximum, sample minimum and their differences. It also includes the content of whether their differences are mutually independent of sample minimum. What is the local minimum variance unbiased estimation? Based on two mutually independent unbiased estimators, a kind of weighted linear unbiased estimators could be constructed, among which the one with the minimum variance is the local minimum variance unbiased estimation. One should remember that three local minimum variance unbiased estimators of mean and variance are not substituted for uniformly minimum variance unbiased estimators of mean and variance, respectively, but only rich in natural estimators.
1. Introduction
Sample minimum, sample maximum and sample mean are important statistics in exponential distribution. Sample minimum has an exponential distribution, and sample mean has a gamma distribution or Chi-square distribution with degree freedom of n. The difference of sample mean and minimum has a gamma distribution or Chi-square distribution with degree freedom of n–1. The difference between sample mean and minimum is mutually independent of the sample minimum (Arnold, Citation1968; Gupta & Kundu, Citation0000; Marshall & Olkin, Citation1967).
This article derives the distribution of the sample range and demonstrates that the sample range is mutually independent of sample minimum. Then, the distribution of the difference between sample maximum and mean is derived, and that the difference of these two statistics is mutually independent of the sample minimum is demonstrated (Cohen and Helm, Citation1973; Kundu & Gupta, Citation2009; Lawrance & Lewis, Citation1983; Nie, Sinha, & Hedayat, Citation2017).
Thus, the sampling theorem is improved. As natural corollary of the sampling theorem of the exponential distribution, a first local minimum variance unbiased estimators of expectation could be constructed by sample minimum and the difference between sample mean and minimum, which is precisely the UMVUE of the expectation. A second local minimum variance unbiased estimators of expectation could be constructed by sample minimum and sample range. A third local minimum variance unbiased estimators of expectation could be constructed by sample minimum and the difference between sample maximum and mean; similarly, three local minimum variance unbiased estimators of the variance are derived. At last, the efficiency comparison is made among the above three local minimum variance unbiased estimators of mean and variance of the exponential distribution (Al-Saleh & Al-Hadhrami, Citation2003; Baklizi & Dayyeh, Citation2003; Dixit & Nasiri, Citation2008; Guoan, Jianfeng, & Lihong, Citation2017; Li, Citation2016).
2. Sampling theorem of exponential distribution
The joint distribution of order statistics of exponential distribution is shown as follows:
Definition 2.1. If ,
is a sample with sample size
from
,
has a joint density function:
Then, we could say is from a multivariate order statistics exponential distribution.
Notate , the sampling theorem is:
Theorem 2.1. If ,
is a sample from
with sample size
,
are the order statistics, then
(1) ,
,
is mutually independent of
.
(2) ,
is mutually independent of
.
(3) is mutually independent of
. The density function of
:
Proof. ,
Notate ,
,
the joint distribution density of is:
Therefore, is the order statistics of sample
, which is the sample from
with sample size
,
is mutually independent of
.
,
is mutually independent of
.
Then, prove part (2).
Transform as ,
,
.
Therefore, is mutually independent of
.
,
.
Notate ,
,
, then
,
, the determinant is:
In , the coefficient of
is
,
, the coefficient of
is
. Derive the density function
of
:
From , we could obtain
, then obtain:
List some specific situations:
When :
, it is a mixed exponential distribution.
When :
When :
When :
is mutually independent of
.
3. Three local minimum variance unbiased estimators of expectation
Theorem 3.1. If ,
is the sample from
with sample size
,
are the order statistics, then the local minimum variance unbiased estimator, which is based on
and
, is the UMVUE of expectation.
Proof. From Theorem 2.1: ,
,
is mutually independent of
, we obtain
and
are both unbiased estimator of
, and the effective unbiased estimator is
,
Plug in and get , which is the UMVUE of the expectation.
Theorem 3.2. If ,
is the sample from
with sample size
,
are the order statistics, then the local minimum variance unbiased estimator, which is based on
and
, is
, here
is the unbiased estimator based on
,
,
is the unbiased estimator based
:
.
Proof.
,
, from Theorem 2.1:
is independent of
,
and
are both unbiased estimator of
, when
,
is the unbiased estimator of
,
, take derivative of
, make it equal to 0 and get:
,
here, ,
when is the local minimum variance unbiased estimator of expectation based on
and
.
Theorem 3.3. If ,
is a sample from
with sample size
,
are the order statistics, then the local minimum variance unbiased estimator of expectation based on
and
is
here ,
is the unbiased estimator of expectation based on
,
,
is the unbiased estimator of expectation based on
,
,
、
are the coefficients of
and
from
and
, respectively.
,
Proof. ,
,
, similar to Theorem 3.2, we only need to compute the expectation, second moment and variance of
.
, let
denote the coefficient of
, then
.
Similarly, , let
denote the coefficient of
, then
,
, when
,
is the local minimum variance unbiased estimator of expectation based on
and
.
4. Three local minimum variance unbiased estimators of variance
Theorem 4.1. If ,
is a sample from
with sample size
,
are the order statistics, then the local minimum variance unbiased estimator, which is based on
and
, is
here, ,
is the unbiased estimator based on
,
,
is the unbiased estimator based
,
.
Proof. From Theorem 2.1:,
,
is mutually independent of
. Obtain:
and
are both unbiased estimator of
, and the effective unbiased estimator is
, here
Plug in and get .
Theorem 4.2. If ,
is a sample from
with sample size
,
are the order statistics, then the local minimum variance unbiased estimator, which is based on
and
, is
,
is the unbiased estimator based on
,
,
is the unbiased estimator based
:
.
Proof:
, from Theorem 2.1:
is independent of
,
and
are both unbiased estimator of
, when
,
is the unbiased estimator of
,
, take derivative of
, make it equal to 0 and get:
, here
.
when
is the local minimum variance unbiased estimator of variance based on
and
.
Theorem 4.3. If ,
is the sample from
with sample size
,
are the order statistics, then the local minimum variance unbiased estimator of variance based on
and
is
here ,
is the unbiased estimator of variance based on
,
,
is the unbiased estimator of variance based on
,
,
,
are the coefficients of
and
from
and
, respectively.
,
.
Proof. ,
,
, similar to Theorem 4.2, we only need to compute the expectation, second moment and variance of
:
, let denote the coefficient of
, then
.
Similarly, , let
denote the coefficient of
, then
,
when ,
is the local minimum variance unbiased estimator of variance based on
and
.
5. Efficiency comparison of three local minimum variance unbiased estimators of expectation and variance
Remark 5.1. The efficiency comparison of three local minimum variance unbiased estimators is the comparison of variances.
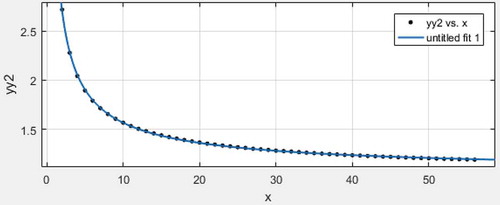
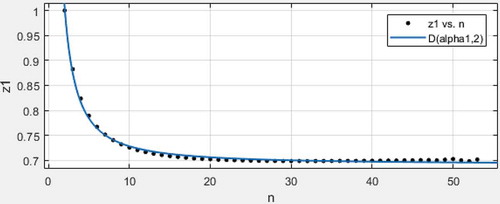
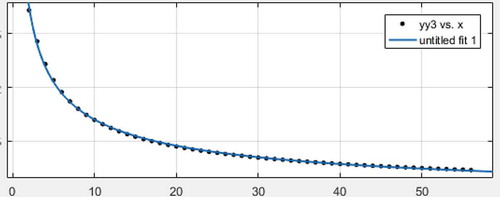
Let , here is the variance comparison of three local minimum variance unbiased estimators of expectation and variance when sample size is 2 to 56.
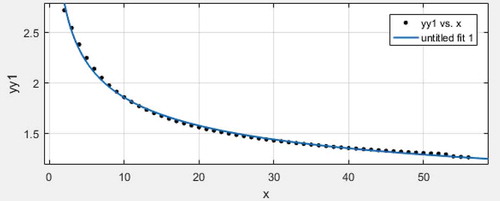
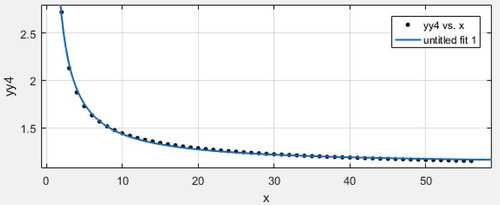
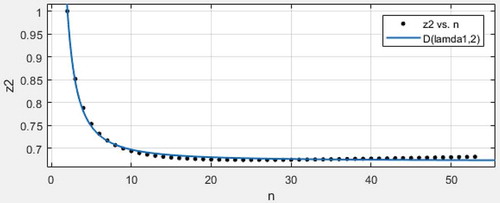
Scatter plot with regression line 1:
Scatter plot with regression line2:
Scatter plot with regression line3:
Comment 5.1. If ,
is the sample from
with sample size
,
are the order statistics, then the efficiency comparison of three local minimum variance unbiased estimator of expectation is that:
.
Proof. Because is the UMVUE of the expectation, we have
,
. Based on comparison among scatter plot with regression lines 1 or 2 as well as 3, we can obtain
. Hence,
.
Scatter plot with regression line4:
Scatter plot with regression line5:
Scatter plot with regression line6:
Comment 5.2. If ,
is the sample from
with sample size
,
are the order statistics, then the efficiency comparison of three local minimum variance unbiased estimator of variance is that:
.
Proof. Based on comparison among scatter plot with regression line 4 or 5 as well as 6, we can obtain.
6. Discussion and conclusion
This article continues the works of references, to improve and perfect the sampling theorem of the exponential distribution. As natural corollary of the sampling theorem of the exponential distribution, one can obtain three local minimum variance unbiased estimators of mean and variance of the exponential distribution, respectively. We know that the sample mean is the UMVUE of expectation and is the UMVUE of variance. Therefore, three local minimum variance unbiased estimators of mean and variance are not substituted for uniformly minimum variance unbiased estimators of mean and variance, respectively, but only rich in natural estimators. From Tables – and scatter plots with regression lines 1–6, we can draw a conclusion that
and
are strictly monotonous decreasing as
increases; moreover, they are all convergent to zero, hence, they are all consistent.
Table 1. Variance comparison of three local minimum variance unbiased estimators of expectation under small sample
Table 2. Variance comparison of three local minimum variance unbiased estimators of variance under small sample
Remark 6.1. The advantages of those estimators are as follows: If sample is not complete or the record value of the sample mean is not given, and the record value of the difference between sample maximum and mean and the sample minimum are known, then the local minimum variance unbiased estimator of expectation, which is based on and
is a practical estimator; similarly, if sample is not complete or the record value of the sample mean is not given, and the record value of the sample maximum and the sample minimum are known, then the local minimum variance unbiased estimator of expectation, which is based on
and
is a recommendable estimator. If sample is not complete or the record value of the sample mean is not given, and the record value of
and
are known, then the local minimum variance unbiased estimator of variance, which is based on
and
is a practical estimator, similarly, under different sample condition, If sample is not complete or the record value of the sample mean is not given, and the record value of
and
are known, or the record value of
and
are known, then the local minimum variance unbiased estimator of variance, which is based on
and
or which is based on
and
is a recommendable estimator, respectively.
Additional information
Funding
Notes on contributors

Muzhen Li
Guoan Li is an associate professor in Ningbo University, the Department of Financial Engineering, with more than 70 publications. His research interest includes prediction of earthquake hazards with application to actuarial science, parameter estimation of mixed generalized uniform distribution and its application to data science, multivariate statistical analysis and its application, statistical inferences of multivariate survival distribution under dependent samples, reasonable price assessment of land and real estate acquisition compensation.
References
- Al-Saleh, M. F., & Al-Hadhrami, S. A. (2003). Estimation of the mean of the exponential distribution using moving extremes ranked set sampling. Statistical Papers, 44, 367–382. doi:10.1007/s00362-003-0161-z
- Arnold, B. C. (1968). Parameter estimation for a multivariate exponential distribution. Journal of American Statistical Association, 63, 848–852.
- Baklizi, A., & Dayyeh, W. A. (2003). Shrinkage estimation of P(Y<X)in the exponential case. Communications in Statistics - Simulation and Computation, 32(1), 31–42.
- Cohen, A. C., & Helm, E. R. (1973). Estimation in the exponential distribution. Technometrics, 15(2), 415–418. doi:10.1080/00401706.1973.10489054
- Dixit, U. J., & Nasiri, P. N. (2008). Estimation of parameters of a right truncated exponential distribution. Statistical Papers, 49, 225–236. doi:10.1007/s00362-006-0008-5
- Guoan, L., Jianfeng, L., & Lihong, W. (2017). Parameter estimation for the multivariate exponential distribution which has a location parameter under censored samples or complete samples. Journal of Systems Science & Mathematical Sciences, 37(8), 1854–1865. (in Chinese) Research field.
- Gupta, R. D., & Kundu, D. 0000. Generalized exponential distributions. Australian and New Zealand. doi:10.1111/1467-842X.00072
- Kundu, D., & Gupta, R. D. (2009). Bivariate generalized exponential distributions. Journal of Multivariate Analysis, 100, 581–593. doi:10.1016/j.jmva.2008.06.012
- Lawrance, A. J., & Lewis, P. A. W. (1983). Simple dependent pairs of exponential and uniform random variables. Operations Research, 31, 1179–1197. doi:10.1287/opre.31.6.1179
- Li, G. A. (2016). Sampling fundamental theorem for exponential distribution with application to parameter estimation in the four-parameter bivariate exponential distribution of Marshall and Olkin. Statistical Research, 33(7), 98–102. (inChinese).
- Marshall, A. W., & Olkin, I. (1967). A multivariate exponential distribution. Journal of American Statistical Association, 62(1), 30–44. doi:10.1080/01621459.1967.10482885
- Nie, K., Sinha, B. K., & Hedayat, A. S. (2017). Unbiased estimation of reliability function from a mixture of two exponential distributions based on a single observation. Statistics and Probability Letters, 127, 7–13. doi:10.1016/j.spl.2017.03.026