
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The four-parameter Generalized Lambda distribution (GLD) can be used to approximate many probability distributions. We present a simple and efficient two-stage process for finding optimal GLD parameters to approximate a specified distribution. The probability density quantile function is first used to find the best GLD shape parameters. Given those shape parameters, it is then straightforward to find the best location and scale parameters. We highlight the excellent performance of our approach with comparisons to two existing and popular methods for a wide choice of distributions. Finally, we show that this is method can be used with other distributions by providing applications also to the Generalized Beta distribution.
PUBLIC INTEREST STATEMENT
The Generalized Lambda distribution (GLD) is a commonly used distribution in many fields, including finance and economics. Due to its flexibility, the GLD is widely used to approximate other distributions. Motivated by this fact, this article presents a new method which can be simply executed to obtain the optimal parameters for the GLD to approximate another distribution. Further, the results are compared with two other methods that are generally used to estimate GLD parameters to show that this new method has favourable qualities.
1. Introduction
Ramberg and Schmeiser (Citation1974) introduced the Generalized Lambda distribution (GLD), a flexible four-parameter family of distributions that can be used to approximate a very large number of probability distributions. It is defined by its quantile function, which depends on a location parameter , inverse scale parameter
, and shape parameters
and
. There are several re-parameterizations of the GLD, but the FKML parameterization (Freimer, Kollia, Mudholkar, & Lin, Citation1988) shown in (1) is simplest to work with, being defined for all real parameter values subject only to
. This GLD is used extensively throughout the text by Karian and Dudewicz (Citation2016) regarding fitting statistical distributions to data and the authors of a book (Pfaff, Citation2016) on financial risk modeling call this GLD an ideal choice.
Given the correct parameters, the GLD distribution equates to several well-known distributions (e.g. the uniform, exponential, logistic) and for many others, a close approximation is possible (e.g. normal, Cauchy, log-normal). While the use of two or more shape parameters increases the flexibility of generalized distributions such as the GLD, an exhaustive search for optimal parameters becomes difficult due to the dimension over which the search need be carried out. We propose to use the probability density quantile (Staudte, Citation2017) which depends only on the shape parameters and which is defined on the interval making the task of finding optimal shape parameters a simple one. It is then straightforward to find the location and inverse scale parameters. Our investigations to be detailed later reveal excellent performance of this new approach when compared to commonly used methods. Additionally, the method we propose is applicable to other distributions such as the generalized beta distribution which we explore in Section 5. Consequently, researchers exploring new generalized distributions will also find our method useful.
An outline of this paper is as follows: In Section 2 we introduce definitions used throughout. We also work through some simple examples that help to motivate our work. In Section 3 we briefly discuss two existing methods that are commonly used to identify GLD parameters before introducing our procedure. Examples are considered in Section 4, where our method is shown to perform relatively well in identifying optimal GLD parameters. Further, a web application is also provided. We then show in Section 5 that the method is suitable also for fitting generalized beta distributions to a given model. A discussion and further work are proposed in Section 6.
2. Definitions and some motivating examples
In this section we introduce definitions and notation to be used in the sequel.
2.1. Quantile, quantile density and density quantile functions
For , let
denote the quantile function associated with distribution function
. Let
denote the probability density function and assume
for all
in its domain. The quantile density function (Parzen, Citation1979) is defined as
. It was earlier called the sparsity index by Tukey (Citation1965). The quantile density function is often useful in nonparametric modeling and inference. For example, for
denoting the estimated pth quantile arising from the empirical distribution function
for a simple random sample of
observations, an asymptotic variance for
is
, e.g. page 52 of Staudte and Sheather (Citation1990). Parzen (Citation1979) called the reciprocal of the quantile density function the density quantile function, and we will denote it here by
2.2. Probability density quantile functions
The probability density quantile, introduced recently by Staudte (Citation2017), is shown to be useful in the study of shape in a location-scale free environment; see also Staudte and Xia (Citation2018).
Definition 2.1 Staudte (Citation2017): For and
assumed to be finite, the probability density quantile (pdQ) is defined to be
for
.
The pdQ is defined for all lattice distributions and continuous distributions having square-integrable densities; it is free of location and scale parameters and defined on the finite domain . Further, it retains information regarding shape such as asymmetry and tail behaviour (Staudte, Citation2017). It, therefore, can provide a simple means to identify suitable shape parameters. Once we introduce the GLD distribution next, we will provide some simple examples using the pdQ to find shape parameters.
2.3. The generalized lambda distribution
The Generalized Lambda Distribution (GLD) of Freimer et al. (Citation1988) is defined in terms of its quantile function:
where is a location parameter,
a scale parameter and
are shape parameters.
It is easy to see that the quantile density function for the GLD is so that the density quantile function is
In general, no closed-form solution for the integral exists, but it can be evaluated computationally and quite efficiently since integration occurs only between the finite bounds zero and one.
2.4. Some motivating examples
The following examples are used to motivate our approach that follows. While for these examples exact solutions are possible, our method provides a way to determine parameter choices for the GLD to closely approximate the true density when exact solutions are not possible.
2.4.1. The uniform distribution
For a simple motivating example, we consider the Uniform distribution with quantile function
and quantile density function
. Of course a simple inspection of the quantile functions for the uniform and GLD distributions reveals that
,
,
and
results in the Uniform
distribution. Below we show how the same results can be arrived at via the GLD.
The density quantile function for the uniform is where
leading to the uniform pdQ
Now by choosing
and
we can assure that the GLD pdQ is also free of
, as it is for the uniform distribution. For the GLD distribution
and
so that for these choices of
and
we have equality between the uniform and GLD pdQs.
2.4.2. The exponential distribution
The quantile function for the exponential distribution with rate parameter is
. Consequently, the pdQ
(see also Staudte, Citation2017). For the GLD, for
and
,
so that
which is equal to the pdQ for the exponential. Note that
so that the quantile function for the GLD is
and equality with the exponential quantile function is achieved by choosing
and
.
3. Methods
3.1. Existing methods
We start by briefly describing two commonly used methods for obtaining GLD parameters. These methods are available in the bda package (Wang, Citation2015) available for the R statistical software (R Core Team, Citation2017) and will be used later to assess our new approach which is also detailed here.
3.1.1. The moments method
Karian and Dudewicz (Citation2003) and Lakhany and Mausser (Citation2000) describe the moments matching method for GLD on the basis of the first four central moments. To estimate the GLD parameters, they match mean, variance, skewness and kurtosis of the GLD with the moments resulting in a system of non-linear equations that can be solved using optimization methods to obtain parameters.
3.1.2. The percentile matching method
Rather than moments, the percentile matching method equates a selected number of percentiles with the GLD theoretical percentiles. By optimizing this set of non-linear equations, parameters can be obtained for the given Generalized Lambda Distribution as discussed by Karian and Dudewicz (Citation1999) and Tarsitano (Citation2005). This method is preferred over the moments method as it applies less weight to the extremes and also could be used in situations where moments do not exist.
3.2. Choosing parameters based on the pdQ
Throughout let denote the GLD quantile function given in (1) and let
denote the corresponding GLD pdQ where we write, for a given
,
to emphasize that the GLD is a function of the two shape parameters. Further, let
and
be the quantile function and pdQ for another distribution to be approximated.
3.2.1. Step 1: choosing shape parameters
In the first step, we seek the GLD shape parameters and
that minimizes the expected squared distance between the pdQs
and
given as
While this need not be an onerous task, since the integral needs to be evaluated over the finite bounds 0 to 1, it is simple to approximate this step using a discrete set of s given as
for a positive integer
. Further, it may be appropriate to apply less weighting to the extreme tails to ensure that the GLD distribution is close to the distribution to be approximated in regions of high density mass. Therefore, we suggest choosing the optimal shape parameters using
where is a weight function to be chosen. We have chosen simple choices of
to be
(no weighting),
(weighting down the left tail),
(weighting down the right tail) and
(decreasing weights towards both the left and right tails). In what follows when considering weighting, we refer to these as left, right and both. Even for
standard optimization functionality in packages such as R can find the optimal
and
quickly.
There may be some difficulty in identifying shape parameters near zero due to the limiting behavior of and
which tend to
and
respectively as the shape parameters tend to zero. An example of this is given in Section 2.4.2 for the exponential distribution. We, therefore, suggest a small tolerance value for the shape parameters such that when the parameters are close to zero such that
and
are replaced with their respective log forms. We choose a tolerance of 0.02 which is also used in the Box-Cox transformation, which has a similar form, in the R MASS package (Venables & Ripley, Citation2002).
3.2.2. Step 2: choosing location and scale parameters
Following the selection of optimal and
in Step 1, we write the GLD quantile function as
which is now a function of
and the unknown
and
. We consider two methods to identify suitable location and scale parameters.
Distributional least squares. The optimal and
can be chosen as
which is the method of distributional least squares for the linear regression of the GLD quantiles on the quantiles from the distribution to be approximated. Consequently the closed-form solution for this minimization exists in the form of usual least squares where the intercept is the optimal choice for and the inverse of the slope parameter is the optimal choice for the scale parameter
. In this step we have found that only a few
‘s are needed to obtain suitable parameters and we set
for a chosen
. In what follows we choose
although other choices may also be considered. For more on distributional least squares see, e.g., page 203 of Gilchrist (Citation2000).
Quartile matching. Another option is to solve the system of linear equations , for known
and
. Solutions are
and then
. Note that this approach would work for any unique
in
.
4. Examples
In this section, we assess the performance of our pdQ method with different weight functions and compare them with the existing moments and percentile matching methods. We use the Hellinger distance (Hellinger, Citation1909) to measure the distance between the true and GLD-approximated density.
As can be seen in Table , similar results are obtained for symmetric distributions regardless of the weight function used. For the skewed distributions, choosing the appropriate weight function improves the GLD approximation. This is due to the fact that the application of less weight to the extreme tails would enhance the GLD approximation by applying more focus in regions with higher density. An example of this could be found for cases like right skewed exponential and Pareto distributions whereby weighting down the right tail provides the close-to-exact approximation. In many cases, the quartile matching approach to identify the best parameter choices is the superior performer and will be our preferred choice moving forward. For the least squares approach, we tried increasing but found that this typically returned poorer results.
Table 1. Hellinger distances for the pdQ method with different weighting methods for step 1 and either distributional least squares or quartile matching for step 2
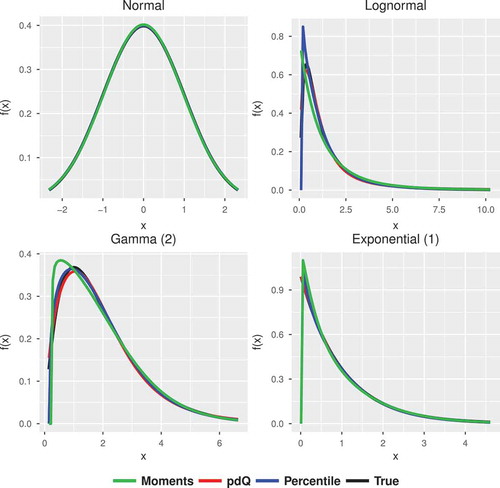
In Table we compare our pdQ method with the moments and percentile matching methods. The pdQ method typically outperforms the existing methods, returning excellent approximations for all of the distributions considered, especially for those that are highly skewed. This is apparent in Figure where the approximated density curves from the pdQ method mimics the true density extremely well compared to the other methods for the lognormal, Gamma and exponential distributions. All methods do very well at approximating the normal density. The non-existence of the first four moments for the selected parameter choice for the Cauchy, Frechet and Dagum distributions makes the moment method inapplicable for those instances. However, both the percentile and the pdQ methods could be used for these distributions.
Table 2. Hellinger distances comparing the performance of the moments, percentile matching and pdQ with quartile matching methods
Figure 1. Plots of the true and approximating GLD probability densities for several distributions using the moment matching (green), percentile matching (blue) and pdQ (red) methods. The true probability density is the black curve.
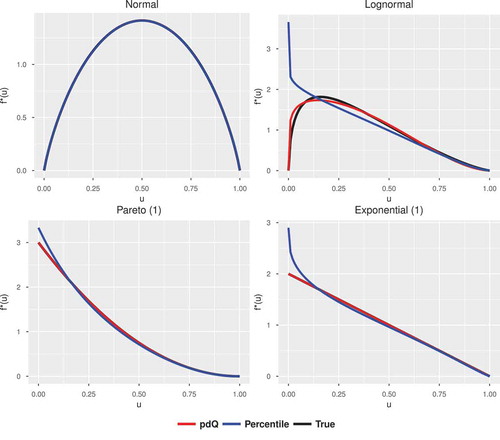
We further investigated the pdQ method and the percentile method by considering the scale—and location-free pdQ plots given in Figure . The pdQ curves produced by the pdQ method shows a better approximation to the true pdQ curve compared to those generated by the percentile matching method.
Figure 2. Plots of the pdQ for several distributions using the percentile matching (blue) and pdQ (red) methods. The true pdQ is the black curve.
In Table we provide the chosen parameters of the GLD distribution by the pdQ method. A large value of for the exponential is due to the fact that the theoretically optimal value is
(see Section 2.4.2). The pdQ method also chooses the correct optimal choices for the uniform distribution that we considered earlier in Section 2.4.1.
Table 3. Parameters chosen for the generalized lambda distribution using the pdQ method and quartile matching
We have also made a Shiny (Chang, Cheng, Allaire, Xie, & McPherson, Citation2017) application that can be used to find parameters of the GLD for several distributions. The app can be found at https://lukeprendergast.shinyapps.io/GLDlambdas/
We are happy to include other distributions on request and improvements to this application will continue to be made.
5. Extensions
As an another possibility, we consider the Generalized Beta Distribution (GB) with the parameterization below as expressed in the R bda package (Wang, Citation2015). This parameterization form includes a location parameter (), a scale parameter (
) and two shape parameters
and
. The quantile function is
where is the quantile function of the usual beta distribution, also commonly known as the inverse regularized beta function. A closed-form expression for
exists only if
,
or
. Further the density quantile function for the GB can be obtained as follows,
where denotes the quantile density function of the beta distribution. The pdQ for the GB can be obtained similarly using numerical integration as a closed-form solution is not available for
.
Table summarizes the performance of the pdQ approach in choosing optimal parameters for the GB distributions in approximating several distributions. Similar results can be found by Karian and Dudewicz (Citation2016) for parameter choices of the GB using the moments method. Excellent approximations can be obtained for most of the distributions such as the Uniform, Normal, exponential, , gamma, beta and triangular distributions using the pdQ approach. The parameterization in 5 indicates that the location and scale are the lower and upper bounds of support for the GB. Therefore, approximations for those parameters get larger for distributions which have infinite support in an effort to capture enough of the density being approximated. Further, shape parameters also can be very large due to the theoretically optimal value being infinite. As an example, both the pdQ method here and the moments matching method in Karian and Dudewicz (Citation2016) provide similar approximations for the normal distribution. The moments matching method approximates the standard normal with parameter choices −1414.214, 1414.214, 999998.848, 999998.848 while the pdQ approach provides similar choices in Table . Moreover, Karian and Dudewicz (Citation2016) report that it is possible to further improve this approximation by letting the two shape parameters get even larger. For the standard beta distribution, the theoretically optimal choices for the four GB distribution are the first and second shape parameter values and a location and scale of zero and one respectively. As can be seen in the table, the pdQ approach correctly identifies these parameters.
Table 4. Parameters chosen for the generalized beta distribution with Hellinger distance using pdQ method with quartile matching to choice the best parameters
We now further look at two specific cases where an exact solution can be obtained for the GB using the pdQ method.
5.1. The uniform distribution
We revisit Section 2.4.1 for the uniform distribution. As described below, we can use the same process to identify the theoretically optimal parameters for the GB. The pdQ for the uniform can be derived as . When
and
, the closed-form expression for the quantile function of the beta distribution is found to be
(Sharma & Chakrabarty, Citation2017). Hence, for these parameter choices, we have the GB pdQ as
and equality between the uniform and GB pdQs. As with the beta distribution, the pdQ approach has identified the optimal parameters.
5.2. The triangular distribution
Similarly, let us also consider the triangular distribution with parameters ,
and
giving the quantile function
. Consequently, we can obtain the density quantile function of the triangular distribution as
. Further, using
, the pdQ of the triangular distribution can be derived as
. If we consider
and
, a closed form solution for the quantile function of the beta distribution can be obtained as
(Sharma & Chakrabarty, Citation2017) which in turn gives the pdQ of the GB distribution as
. Therefore, we can obtain equality between the triangular and GB pdQs for this parameter choice. Again, the pdQ approach has found the optimal parameters.
6. Discussion
By concentrating on first identifying suitable shape parameters using the probability density quantile function, we have introduced a method for choosing optimal GLD parameters to approximate other distributions. Our method typically outperforms the approaches based on moment and percentile matching, and it is simple and efficient to implement. We also showed that the approach is also suitable for other distributions such as the generalized beta distribution. We are currently investigating estimation methods using some of the ideas developed here in the population setting.
Acknowledgements
The authors would like to thank the two anonymous referees for their thoughtful suggestions and the Editor for their support in providing a revised version.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Dilanka S. Dedduwakumara
Mr. Dilanka S. Dedduwakumara is a PhD candidate and a Statistician in the Department of Mathematics, La Trobe University, Australia. He has a Bachelor of Science (B.Sc.) in Statistics from the University of Colombo, Sri Lanka. He is researching in the fields of quantile-based methods in regards to limited summary information and parameter estimation of Generalized Distributions.
References
- Chang, W., Cheng, J., Allaire, J. J., Xie, Y., & McPherson, J. (2017). shiny: Web Application Framework for R, r package version 1.0.5.
- R Core Team. (2017). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing.
- Freimer, M., Kollia, G., Mudholkar, G. S., & Lin, C. T. (1988). A study of the generalized Tukey lambda family. Communications in Statistics-Theory and Methods, 17, 3547–11. doi:10.1080/03610928808829820
- Gilchrist, W. (2000). Statistical modelling with quantile functions. Florida: CRC Press.
- Hellinger, E. (1909). Neue begründung der theorie quadratischer formen von unendlichvielen veränderlichen. Journal für die reine und angewandte Mathematik, 136, 210–271.
- Karian, Z., & Dudewicz, E. (1999). Fitting the generalized lambda distribution to data: A method based on percentiles. Communications in Statistics-Simulation and Computation, 28(3), 793–819. doi:10.1080/03610919908813579
- Karian, Z. A., & Dudewicz, E. J. (2003). Comparison of GLD fitting methods: Superiority of percentile fits to moments in L2 norm.
- Karian, Z. A., & Dudewicz, E. J. (2016). Handbook of fitting statistical distributions with R. New York, NY: Chapman and Hall/CRC.
- Lakhany, A., & Mausser, H. (2000). Estimating the parameters of the generalized lambda distribution. Algo Research Quarterly, 3(3), 47–58.
- Parzen, E. (1979). Nonparametric statistical data modeling. Journal of the American Statistical Association, 74, 105–121. doi:10.1080/01621459.1979.10481621
- Pfaff, B. (2016). Financial risk modelling and portfolio optimization with R. UK: John Wiley & Sons.
- Ramberg, J. S., & Schmeiser, B. W. (1974). An approximate method for generating asymmetric random variables. Communications of the ACM, 17(2), 78–82. doi:10.1145/360827.360840
- Sharma, D., & Chakrabarty, T. K. (2017). Some general results on quantile functions for the generalized beta family. Statistics, Optimization & Information Computing, 5(4), 360–377. doi:10.19139/soic.v5i4.312
- Staudte, R. G. (2017). The shapes of things to come: Probability density quantiles. Statistics, 51, 782–800. doi:10.1080/02331888.2016.1277225
- Staudte, R. G., & Sheather, S. J. (1990). Robust estimation and testing (Vol. 918). New York, NY: John Wiley & Sons.
- Staudte, R. G., & Xia, A. (2018). Divergence from, and convergence to, uniformity of probability density quantiles. Entropy, 20(5). doi:10.3390/e20050317
- Tarsitano, A. (2005). Estimation of the generalized lambda distribution parameters for grouped data. Communications in Statistics—Theory and Methods, 34(8), 1689–1709. doi:10.1081/STA-200066334
- Tukey, J. W. (1965). Which part of the sample contains the information? Proceedings of the National Academy of Sciences, 53, 127–134.
- Venables, W. N., & Ripley, B. D. (2002). Modern applied statistics with S (4th ed.). New York: Springer. ISBN 0-387-95457-0.
- Wang, B. (2015). bda: Density Estimation for Grouped Data, R package version 5.1.6.. doi:10.1094/PDIS-09-14-0954-PDN