 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This research analyzes the eco-efficiency of peasant production in a sample of 32 Puebla municipalities located in the tropical montane cloud forests (TMCF) and the influence of climatic factors, considering data from two years 2016–2017. Therefore, window data envelopment analysis approach with bootstrap in two stages was used. The results allow us to draw two basic conclusions. 1) It is possible, imitating the benchmarks, at the aggregate level in the region, to increase annual revenue and preserved areas by 58.7%, with the same inputs; or equivalently, reduce inputs and environmental costs by 36.98% with the same level of production. 2) Eco-efficiency scores are significantly affected by climatic factors and thus, the increase in temperature and the reduction in precipitation should have predominantly positive impacts on the region’s eco-efficiency. This finding should be based on the characteristics of the region—humid mountainous forest with rain for most of the year and persistent mist almost at ground level. Based on this information, strategies can be defined by decision makers to harmonize economic growth and environmental preservation, as well as adaptive policies and actions to reduce vulnerability and improve the resilience of peasant producers.
1. Introduction
One of the themes discussed at the 26th United Nations Conference on Climate Change in Glasgow, Scotland, was the preservation of forests. At this conference, according to the website (https://news.un.org/en/story/2021/11/1104642), 110 countries, home to 85% of the world’s forests, signed a declaration, pledging to stop and reverse deforestation by 2030. This is an important step; however, the next and most difficult is the implementation of this commitment at the regional and local level, without compromising the sustainable development of the communities that live there.
In many forests, a large number of economically vulnerable small farmers live and work. They are families with limited resources to maintain or increase productivity and competitiveness, marginalized from social assistance, and affected by the fragmentation of rural properties with the independence of their adult sons (Donatti et al., Citation2019). Therefore, the implementation of increasingly strict regulations on environmental protection has generated a notable concern about its effects, a priori, negative in these communities.
This situation is no different in Mexican tropical montane cloud forests (TMCF),Footnote1 where decision-makers face two major challenges. The first indicates the need to make the communities that live there more productive and efficient so that they can offer more products with higher quality and competitive prices, capable of facing the direct competition of industrial-scale agriculture (Morton, Citation2007). The second challenge arises from the evidence that agricultural intensification and expansion in forestry areas can generate environmental damage not offset by economic benefits. The removal of native primary vegetation cover compromises the ecosystem services provided by flora and fauna, which also run the risk of degradation. It induces erosion, a reduction in soil nutrients, and an increase in greenhouse gas (GHG) emissions, which end up interfering with both the rainfall regime and the planet’s temperature. This creates a vicious cycle, as changes in temperature and precipitation patterns can damage the agricultural activity itself (Donatti et al., Citation2019; Kummu et al., Citation2021).
Therefore, the challenges in this region demand answers to the following questions: Is it possible to raise production and, at the same time, reduce environmental impacts and the use of production inputs? in other words, is a more eco-efficient agriculture feasible? If plausible, to what extent can agriculture be more eco-efficient in? How can temperature and precipitation affect eco-efficiency? Around these questions is the central problem of this article.
In recent decades, the literature has shown great contributions to the development of robust models for empirical analysis of efficiency, productivity, eco-efficiency, and their determining factors (Emrouznejad & Yang, Citation2018). From the seminal works of Simar (Citation1992) and Wilson (Citation1993), innovative approaches have emerged using bootstrap techniques to overcome the limitations of classical models: Stochastic Frontier Analysis—SFA (Aigner et al., Citation1977; Meeusen & van den Broeck, Citation1977) and Data Envelopment Analysis—DEA (Charnes, Cooper, & Rhodes, Citation1978). These approaches fall under the so-called stochastic and semiparametric DEA and make a symbiosis that integrates the random term contained in SFA-type methods to the boundary estimated by non-parametric DEA-type methods.
Although the use of the stochastic and semiparametric DEA model has become popular in the last decade, in the most diverse areas, there is a gap in the literature, especially in the study of the relationship between climatic factors and agricultural eco-efficiency. As far as is known, in the case of the analysis of Mexican agriculture with this method, there are no studies on eco-efficiency, and articles on the impact of climate factors on efficiency and productivity in Latin America and the Caribbean are scarce (Lachaud et al., Citation2017). Even so, it is possible to cite some works that include in the study of the efficiency and productivity of climatic variables: Mullen (Citation2007) for the analysis of Australian agriculture; Villavicencio et al. (Citation2013) for the USA; Khanal et al. (Citation2018) for Nepal; Ojo and Baiyegunhi (Citation2020) for Gori-Maia et al. (Citation2021) for Brazil.
This study aims to estimate robust two-stage bootstrap DEA eco-efficiency scores for agriculture in TMCF of the State of Puebla, on a municipal basis, considering data from 2016–2017. For this, in the first stage, the classic inputs and products of the sector were used, adding two environmental externalities: one positive and the other negative. At this stage, bootstrap techniques allowed for detecting outliers, estimating bias, correcting scores, as well as testing the type of returns to scale and the evolution of eco-efficiency in the two years studied. In the second stage, temperature and precipitation variables are used to explain the corrected eco-efficiency using the truncated Tobit regression model.
In this way, the study provides insights into benchmarks, goals for improving eco-efficiency in low-performing municipalities, and the possible impact of climate variables. It is hoped that the results can be particularly useful for formulators and decision-makers in defining and designing strategies that harmonize economic growth and environmental preservation, supporting the region’s sustainable development.
2. Background
The TMCF represents a biome that occupies a small area of the planet’s surface. Bruijnzeel (Citation2001) estimated that, at the beginning of the 21st century, these woods occupied around 381,000 km2, approximately 0.26% of the planet’s area. Despite its small size, it is a biome that contributes a set of ecosystem services. This type of forest provides wood, food, medicinal substances and fibers, purifies and preserves water resources and conserves fauna and flora.
In Mexico, one area of TMCF is located at the Oriental Sierra Madre, in rugged terrain with an altitude ranging from 400 to more than 2,800 meters above sea level, with temperatures around 12 to 20 °C and high humidity due to frequent rainfall that range between 1000 and 3000 mm. In 2013, it was estimated that the area of the Mexican TMCF was almost 17,000 km2 (1% of the national territory) and, despite being highly fragmented and dispersed, four-fifths were considered to be unchanged; the remaining was made up of almost 12% of the degraded area, 6% of the deforested area and 2% of area under-recovery (Sánchez-Ramos & Dirzo, Citation2014).
The Comisión National para el Conocimiento y Uso de la Biodiversidad (CONABIO) in its Information System on TMCF, reports the existence of great diversity: for example, 5533 species only with flowers, added to the 630 species of ferns and related plants. This represents 27% of the country’s floristic richness and about 2% of the world’s total floristic (Villaseñor, Citation2010). Nevertheless, given the fragility of the TMCF and the deterioration caused by human activities, there is a transition to an ecosystem that replaces primary vegetation with secondary vegetation, the fragmentation of the biome, and the migration and extinction of animals and plants (Cruz-Cárdenas et al., Citation2014). Families in the region practice shade coffee planting but carry out subsistence agriculture by cutting and burning the forest, which increases the degradation of the biome.
3 Theoretical methodological framework
In economics, efficiency develops from the joint concept of production possibility (CPP)—technology set (T). This set incorporates the transformed inputs (x) and the outputs (y) generated by a set of available production processes. It is expressed mathematically as:
where: in a broader concept (eco-efficiency), vector x represents production factors and environmental costs; and y is the set of desired products, including positive externalities.
Shephard (Citation1972) and Färe (Citation1988) describe the properties of the CPP. These properties define a space in the negative as , constituted by the x and
of the n productive units (called DMUs—Decision Making Unit) that make up the CPP. The upper limit of space determines the boundary
of the CPP that involves the points that represent the DMU. Farrell (Citation1957) shows that it is possible to build this boundary with linear segments, from the convex combinations of efficient DMUs. Thus, inefficient DMUs are located in points inside the CPP, showing that they are not maximizing production or minimizing inputs.
Hence the concept and measures of eco-efficiency. Eco-efficiency is revealed when a DMU obtains the highest level of desired products possible with a given level of input and environmental impact or when it requires the least possible amount of inputs and environmental cost to produce a given number of products. Its measurement results from the calculation of the Euclidean distance that separates each DMU from the border formed by the benchmarks. Thus, it is possible to define two measures of technical efficiency (): i) Farrell’s technical efficiency-oriented to maximize outputs with a given input level, ; ii) Farrell’s technical efficiency aimed at minimizing the inputs with a given level of products,
. Farrell’s (Citation1957) efficiencies are inverse to Shephard’s (Citation1970) radial efficiencies.
3.1 DEA Models
Having a set of n CPP observations it is possible to estimate the frontier of the CPP (
and the Farrell efficiency
, using the Data Envelopment Analysis (DEA) method. This is a nonparametric linear programming procedure, developed by Charnes, Cooper & Rhodes (Citation1978) and called the DEA-CCR or CRS model. It characterizes the technology through the estimator
of T and calculates
, an estimator of
, imposing the properties of constant return to scale (CRS). The output-oriented eco-efficiency estimator with
e
for each DMUi is defined with the following linear programming problem (PPL):
where Y= [y1, …,yn] and X= [x1, …,xn] represent, respectively, the matrices of the outputs (including the positive externalities) and inputs (including the environmental costs) of the n observations; xi e yi—the vectors of inputs and outputs, respectively, of the assessed DMUi; =[
1, …
n] 1xn—the vector that determines the linear combination of the best practices in the construction of the frontier.
is the output-oriented eco-efficiency index of DMUi that must be greater than or equal to 1. If
the DMUi is considered eco-efficient. For other cases, it will be eco-inefficient.
gives the projection of (
on the frontier, at the maximum level of outputs possible with the available inputs. In this way, it is possible to define improvement targets for eco-inefficient DMUs.
Similarly, one can define a new PPL and find the input-oriented eco-efficiency estimator for each DMUi.
where . If
the DMUi is considered eco-efficient. Otherwise, it will be eco-inefficient.
determines the projection of (
on the efficient frontier and indicates the intensity of waste verified in the production process. It is necessary to register that with the technology with constant returns
.
The DEA-CCR model was further complemented by Banker et al. (Citation1984) to include the property of increasing, constant, or decreasing scale income in different parts of the frontier. This is called the DEA-BCC or VRS model, in which the PPL for the product-oriented eco-efficiency estimator with for each DMUi is defined:
On the other hand, the PPL of the input-oriented DEA-BCC model is:
Thus, for a DMUi, the is estimated by adding, in the DEA-CCR PPL, the restriction
, that is,
. This allows incorporating the variable returns property and ensuring that DMUs are only compared with DMUs of equivalent size, disregarding scale inefficiency.
The explanation of the scores and
is the same as in the DEA-CCR model, concerning the maximum possible level of outputs and the minimum possible level of inputs, respectively. However,
and the DEA-BCC efficiency will always be greater than or equal to that achieved with DEA-CCR, that is, the BCC efficiency scores tend to be less restrictive than those obtained with DEA-CCR.
Cooper et al. (Citation2007) present other extensions of the DEA model. Among them, we are interested in the Window Analysis model. Window analysis, proposed by Charnes et al. (Citation1984), is valid for measuring intertemporal efficiency. It allows analyzing the same DMU in several periods (t) and identifying the year in which the DMUs were more or less efficient. Therefore, the sample has n*t observations. This increases the number of DMUs analyzed, which can be useful when dealing with small samples. In addition, it is possible to use DEA with unbalanced panel data, that is, panels that do not have the same number of DMUs in each period. However, the DEA window analysis implicitly assumes that each DMU is independent, different in each period and that there are no technical changes in the analyzed period.
3.2 Outlier detection
The models specified above are deterministic, calculate punctual efficiency values, and thus become sensitive to measurement errors and omissions as well as to the existence of outliers. Therefore, its application requires a previous data cleaning procedure. Wilson (Citation1993) suggests a first step, such as exploratory data analysis, before using any boundary estimation.
Bogetoft and Otto (Citation2011) recommend the multivariate data cloud method to detect outliers. This method identifies the atypical cases by calculating the influence of each DMU on the CPP. The influence refers to the impact of removing one DMU from the sample on measuring the efficiency of other DMUs. The method starts by calculating the volume of the point cloud (in the space formed with the variables used), estimated by the determinant of the input-output matrix. Afterward, a DMU is removed and the volume change is observed. If the volume variation is high, then it is possible to conclude that said DMU is an outlier. The volume change is calculated by R(i) = Di/D, where D is the determinant of the initial matrix and the Di—determinant after DMUi removal. Therefore, if the DMUi is not an outlier, R(i) will have a value close to 1; otherwise, its value will be close to zero, denoting an influential observation.
The process must be repeated for each DMU and a growing set of deleted DMUs. The number (r) of removed DMUs in the pool is arbitrary at the researcher’s discretion. However, its size must be large enough to detect outliers masked by other outliers. Usually, 10% of the sample is taken, following the estimates of Banker and Chang (Citation2006). When examining the values of Rr for the sets of r DMUs, we look for the first smallest value, which is compared with the other Rr. If the difference is large, the will be formed by a group of outliers. To get a clear picture of these differences and how they depend on the number of DMUs excluded Wilson (Citation1993 and Citation2008) recommends building a graph with the ordered pairs
. In this graph, outliers are identified when there is a relatively large interval between the points above 0 and the point at 0.
3.3 Statistical inference of bootstrapped DEA estimators
Another problem of classical DEA models, arising from their deterministic nature, is related to the estimation of point values without debating the stochastic noise and uncertainty surrounding this estimate. However, it would be of great relevance for empirical use if eco-efficiency analysis were complemented with statistical inference techniques that define confidence intervals, hypothesis testing, and correlation analysis. This allows for evidence of the reliability and acceptance of the scores of the DEA models and helps to qualify comparisons of eco-efficiency between DMUs, as well as the effect of exogenous variables. To make this complementation and obtain more robust efficiency indicators, a semi-parametric and stochastic DEA based on bootstrap techniques was developed.
The stochastic DEA is based on the fact that the set of n observations is just a sample of the CPP, which is not exhaustively known. Therefore, it is assumed that both the inputs and outputs and the eco-efficiency scores are random variables, resulting from an unknown data generating process (DGP), an underlying density function from which other observations can be produced. Naturally, it is assumed that there is a bias between the true technology T (unknown and unobservable) and the estimated based on a given sample of observations.
For small samples with unknown distributions, bootstrap is the most appropriate method for statistical inference. Bootstrap is widely used to obtain estimates with greater precision, calculate bias, and confidence intervals and perform hypothesis tests on parameters of interest. The main idea of bootstrap is to obtain a “new” set of random data, resampled with replacement over the original data set (Efron & Tibshirani, Citation1993). Resampling is repeated several times to create new samples (pseudo-samples) of the same size as the original. From the set of samples, we obtain the distribution of the estimates of the parameter of interest which should be like the true one, and we can draw robust conclusions about the statistics that interest us. In other words, the essence of the bootstrap is to generate a fictitious distribution so like the real one that the results obtained from it can be considered analogous to those obtained with population data.
In this work, DEA based on bootstrap techniques will be used to estimate eco-efficiency confidence intervals and test three hypotheses: the existence of return to scale, the difference in eco-efficiency between two periods, and the dependence between eco-efficiency and external factors.
3.3.1 Bootstrap to estimate bias and confidence interval of DEA indexes
To operationalize this procedure, Simar and Wilson (Citation1998) suggested a special type of bootstrap, called smooth. This is different from the classic naive bootstrap, which is inconsistent in inferring DEA indicators. In this new proposal, new bootstrap efficiency indexes for each DMU ( are estimated from the initial indexes, using a kernel density estimate with smoothing and reflection methods. Then, these new indexes are used to generate a new sample
formed (respecting the radial nature of the efficiency) as follows: to estimate
use
and
; to estimate
is given by
and
. With these new inputs and outputs, we get a new efficiency index
. By replicating this process B times for each DMU we will have a vast amount of bootstrap efficiency scores, a set
and a joint density function
for each DMUi. This distribution provides a reliable estimate of the true efficiency index of DMUi, this reliability being greater when B → ∞ and n → ∞. Simar and Wilson (Citation1998) suggest that at least 2000 samples are needed for asymptotic results to be good.
As Simar and Wilson (Citation1998) point out, when the bootstrap is consistent, the distinction between initial efficiency () and bootstrap efficiency (
) should be similar to the difference between initial efficiency and true efficiency (
) for a given DMUi:
Therefore, the bias for each DMUi can be revealed, by the equations:
where is the average of B bootstrap efficiency estimates of the DMUi. So, the estimator of
with bias correction is:
It is also observed that knowing the empirical distribution of bootstrap efficiency and bias, it is possible to estimate confidence intervals with a significance level (1-α), computing the critical values aα and bα, so that
To calculate aα and Simar and Wilson (Citation1998, Citation2000) propose the use of the percentile method, which is based on ordering bias-corrected estimates from highest to lowest and eliminating, at both ends of this ordering, the percentage (α/2) of values. Thus, the estimated confidence interval will be
This procedure, formulated for the DMUi, is the same that must be followed for each and every one of the other DMUs that make up the original sample.
The smoothed bootstrap algorithm to estimate the bias and confidence interval of DEA indexes is operated by the R boot.sw98 function available in the FEAR library (Wilson, Citation2008).
3.3.2 Test of the return to scale model
The freedom to choose one model (CCR or BCC) or adopt multiple models may be inadequate. Taking an unproven assumption about frontier returns to scale can seriously change efficiency measures if the actual technology is another (Simar & Wilson, Citation2002). Therefore, in the development and validation of the DEA method, one must test whether the set of technology T from which our observations are sampled exhibits constant returns to scale or not. The authors formalize the test with a pair of hypotheses: the null hypothesis (H0): T is CCR or the alternative hypothesis (Ha): T is BCC, using the following estimator:
where, S ≤1, since . If S is close to 1, H0 must not be rejected and if S is significantly less than 1, Ha must be considered true. Therefore, we must find a critical value
that will determine whether we should reject H0, when S <
is according to a significance level: usually 5%.
The distribution of the population parameter of S is unknown. Therefore, it is not possible to determine immediately. To estimate the distribution of this estimator, Simar and Wilson (Citation2002) advise using the bootstrap technique. With the help of the R boot.sw98 function, the algorithm obtains the sets of bootstrap efficiency scores for the CCR model, for the BCC model, and the distribution of S. In this way, we can compare the estimated value of S in (11) with the critical value at 5% to decide on H0.
3.3.3 Efficiency difference test for two periods
According to Bogetoft and Otto (Citation2011), if the set of n DMUs is divided into two groups with K1 and K2, where n = K1 + K2, we may also be interested in testing whether there are significant differences between the efficiencies of the two groups. The authors argue that this procedure is relevant if one intends to test whether a specific treatment in a group of DMUs is more efficient than another, whether a specific region offers more favorable conditions for companies than another, etc. In our case, we are interested in testing whether the distribution of eco-efficiency of municipalities in 2016 ( is significantly different from 2017. Thus, the test can be formalized as the null hypothesis, H0:
=
; versus the alternative hypothesis, Ha:
.
There are several ways to perform these tests. If the assumption of the efficiency distribution is not possible, Banker (Citation1993) suggests using the Kolmogorov-Smirnov (K-S) test and Bogetoft and Otto () complement it with the Kruskal-Wallis test. Thus, these tests will be used to verify the equality of the two corrected eco-efficiencies distributions.
3.3.4 Testing the dependence of eco-efficiency on external factors: Second-stage analysis
After estimating the corrected indexes and performing the aforementioned tests, for Bogetoft and Otto () naturally the following questions arise: why are some DMUs more efficient than others? Is efficiency affected by weather disturbances and other exogenous factors?
The search for answers to these questions led to the emergence of the semi-parametric technique called two-stage analysis (Simar & Wilson, Citation2007). In the first, the corrected efficiency indexes are calculated and, in the second, we try to identify the impact of other variables (Z) on the efficiency of the DMUs. These variables (Z) are called exogenous, non-discretionary variables and can be internal or external to the production process. Lovell (Citation1993) advises the use of variables under the manager’s control in the first stage and variables over which the producer does not control in the second, such that the second stage variables are not correlated with the inputs and outputs used in the first.
To investigate whether a Z vector explains variations in efficiency, Tobit regression is usually used. This method is estimated by maximum likelihood and is used when the dependent variable is truncated by value ranges. However, as the DEA efficiency indexes have serial correlation and there is often multicollinearity in the contextual variables, biased results can be obtained, especially when the sample is small.
To overcome this problem, Simar and Wilson (Citation2007) indicate the application of bootstrap to a truncated regression model (Tobit or equivalent) in which . Here,
represents the corrected eco-efficiency, estimated in the first stage;
is the vector of predictor variables that are expected to explain the eco-efficiency indices through the vector of parameters
to be estimated; and the vector
is the random error associated with each DMU, indicating the part of eco-inefficiency not influenced by
. It is assumed that
has a normal distribution with an average 0 and variance
censored between 0 and 1. This procedure allows you to test consistently which are the significant influencing variables and their sign (positive or negative).
Simar and Wilson (Citation2007) developed two algorithms that incorporate the bootstrap procedure into a truncated regression model. In this research, we will use Algorithm #1, recommended for samples with less than 400 units and up to three outputs and three inputs.
4 Variables
This section describes the sample and data used. The sample consisted of a group of 32 municipalities in the State of Puebla (Figure ), representing 15% of the 217 municipalities in this State. They are located in the TMCF, in the mountainous region of Sierra Norte, east of the capital of the Mexican Republic and have a humid and hot climate, with abundant rainfall in summer. Families practice planting coffee in the shade and do subsistence agriculture by cutting and burning the forest, which increases the degradation of the biome.
Figure 1. Municipalities of Puebla, located in the TMCF.
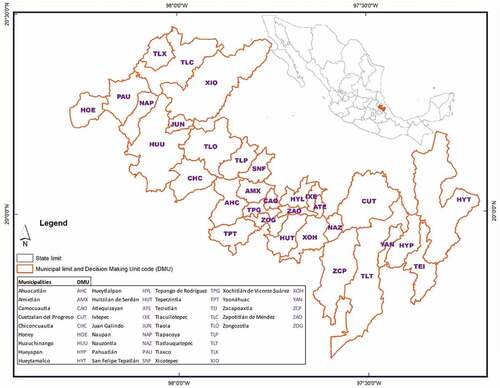
The analysis of these municipalities was carried out in terms of input and output indicators commonly used for agricultural efficiency and productivity analyses. But a negative externality was added as input and a positive environmental externality as an output. More specifically, the following variables were considered. As input: x1—people employed in the primary sector (paid and familiar); x2—an area of agricultural use in hectares; x3—greenhouse gas (GHG) emissions in the agricultural sector in tons of CO2 equivalent which represents a proxy of the environmental cost; as outputs: y1- total production value in thousands of Mexican pesos; y2- a preserved area with forest in hectares, which represents a proxy of environmental services provided by nature in this area.
Furthermore, to investigate the association of climatic factors with eco-efficiency in the second stage, the average annual temperature (in °C), precipitation of the municipalities (in mm) and their squared values (T^2 and P^2) were selected. The inclusion of T^2 and P^2 is because at the extremes of these variables (low or high temperatures and lack or excess of precipitation) we must observe similar effects and their impacts are not constant (that is, they have different rates of variation -ascending or descending).
Data were extracted to two years (2016 and 2017) from different official databases according to Hernández Cayetano (Citation2020) (See end of text “Data Availability Statement” section).
5 Results analysis
5.1 Descriptive analysis, outlier detection, and final sample
Table shows the descriptive statistics of inputs, products, and climate variables, allowing for an overall view of the sample referring to the 64 DMUs analyzed (32 municipalities in 2 years −2016-2017). The Table indicates that, for all variables, the minimum values are well below the 1st quartile and the maximum values are well above the 3rd quartile. This shows the existence of significant heterogeneity in the data and evidence of potential extreme observations (outliers), mainly in y1- total production value.
Table 1. Descriptive statistics of inputs (x), outputs (y), and environmental determinants
As pointed out, DEA models are especially sensitive to the presence of outliers. Therefore, a preliminary purification of the data was performed, using the routine developed by Wilson (Citation1993) in the FEAR 2.01 package for the R programming language. In this analysis, the possibility of removing more than 10% of the sample was considered, an r =8, an acceptable size for a sample 64.
The results are presented in Table , which show which exclusions provide the minimum value of Rr (the ratio of the new volume of the data cloud to the initial volume). The first line of Table shows that the exclusion of DMU 45 will result in a value of R1 =0.2015, the minimum value of R1 when only one observation is excluded from the sample. The second line, r =2, indicates that excluding DMUs 54 and 45 simultaneously we obtain an R2 =0.1335. The same understanding is valid for the other lines. Complementing the Table, represents a dashed line connecting the second lowest values for each r, illustrating the separation between the lowest log ratios for each r value. Thus, for r = 1 a jump relatively larger than the rest is obtained when excluding the DMU45, the Tlatlauquitepec municipality of 2016 (TLT16).
Table 2. Matrix of outliers for the initial sample
Analyzing the TLT16 municipality, it is possible to notice the existence of a possible typographical error in the variable y1- total production value. This value is the maximum observed in Table , being 10 times greater than y1 for this municipality in 2017. Therefore, it was decided to remove this DMU from the sample.
Graph 1. Log-ratio for the initial sample.
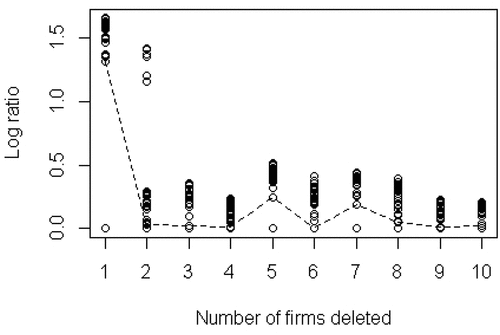
In , we observe two other jumps: r =5 and r =7. However, the DMUs that form r =5 and r =7 (except 45) are neither at the minimum input extremes nor at the maximum output extremes. Therefore, because they are relatively smaller jumps, it was decided to keep these DMUs in the sample. Decisions about atypical cases are not mechanical, they must be taken with prudence. Simar and Wilson (Citation2015) indicate that determining what constitutes an outlier necessarily implies a certain subjectivity on the part of the researcher.
5.2 Statistical inference of DEA eco-efficiency
After defining the new sample (63 DMUs), the return to scale test was performed, since the choice of technology is a fundamental issue and if decided arbitrarily, inadequate conclusions can be reached. As already suggested, this test was performed using the CCR and BCC ecoefficiency scores with the DEA window analysis method and the bootstrap procedure. The null hypothesis of CRS technology prevalence can be rejected if the estimated statistic S in (11) is less than the critical value obtained by the bootstrap estimators.
Bootstrapping the test used 2000 replications, giving an S = 0.8157 and a critical value of 0.6541 at a 5% significance level. Thus, it is suggested not to reject the CRS technology. Therefore, it can be assumed that in the studied region the DMUs operate with a similar production scale, with no relative scale inefficiency.
This result must be supported by the geography of the region and by the fact that in the municipalities studied, peasants’ production oriented in part to subsistence economy predominates. In this type of mountain farming, production is carried out on small properties, with little technological diversity, low use of inputs and machines, and an insignificant amount of external labor, where the family usually plays the role of owner, manager and is still responsible for all production and marketing logistics. Without cooperatives, and technical and financial assistance, it is difficult to find significant inequality in the scale of production.
Adopting the CRS technology as the dominant one, we started to estimate the eco-efficiency values, considering the random error inherent in the data. Here, the window analysis and the DEA-Bootstrap proposal by Simar and Wilson (Citation1998, Citation2000) was also used, using 2000 replications. As a result, a stochastic production frontier closer to the real one is established to estimate the eco-efficiency levels.
shows the bias-corrected efficiency estimates and 95% confidence intervals and Table records the values of the main results: the deterministic and bias-corrected eco-efficiency levels and their confidence interval for the output-oriented CCR model. But, due to the large number of DMUs, only the three most eco-efficient and the three most eco-inefficient municipalities are shown in the Table. Thus, when closer to one (1) the DMU is more eco-efficient; otherwise, if eco-efficiency is greater than 1, it will be more eco-inefficient. The results confirm that there are non-negligible eco-inefficient behaviors in the region and, therefore, it is possible to increase eco-efficiency.
Graph 2. Bias-corrected efficiency estimates and 95% confidence intervals (Source: elaborated by the authors).
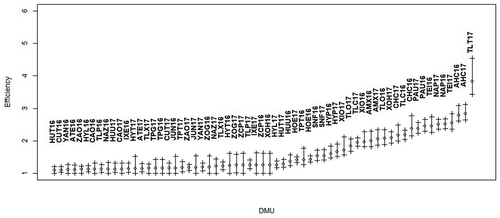
Table 3. Eco-efficiency
In Table , as in , the DMUs were classified from lowest to highest corrected eco-inefficiency. It is noted that the DMU15, the municipality Huitzilan de Serdán in 2016 (HUT16), was the best position in the ranking. Thus, the multiplication of its index by the product vector ( will give the projection of this municipality on the efficient frontier, the maximum level of outputs with the available inputs (x15). The municipality with the lowest eco-efficiency was Tlalauquitepec in 2017 (TLT17) with an index of 3.833, within the confidence interval 3,433–4.548. This allows us to consider that in this municipality, as well as in others that have very high scores, increasing its products to be eco-efficient will require a great effort. In this way, it is possible to define improvement goals for the evaluated municipalities.
From the results reported in Table , other important inferences are derived. The average of the bias-corrected indices was 1,587, indicating that in the region, on average, the total value of production and the preserved area with forest can increase by 58.7%, maintaining the level of inputs and emission of effect gases greenhouse—GHG. Equivalently, this index shows that it is possible to reduce inputs and emissions by 36.98% (1-(1/1.587)) with the same level of production. It is also observed that the mean and the standard deviation (0.58) of the corrected eco-efficiency levels is smaller than those obtained for the uncorrected eco-efficiency. In other words, the corrected eco-efficiency indices are more robust than the indices estimated by the deterministic DEA method, suggesting an overestimation of the latter. This finding highlights the relevance of performing the bootstrap analysis when estimating the efficiency indices in small samples. It also indicates that great caution should be exercised when performing comparative analysis between DMUs, since, as shown by the confidence interval, there may be no significant difference between the indices. If two intervals intersect, it would be possible to affirm that the units do not have statistically different levels of eco-efficiency.
Using the corrected indices, we continued with the tests on the difference in eco-efficiency of municipalities between 2016 and 2017. Table presents the results of descriptive statistics and hypothesis tests on equality of distributions for the two groups, 2016 and 2017. Both the Kolmogorov-Smirnov and the Kruskal-Wallis tests estimated a p-value greater than the 0.05 significance level, which leads us not to reject the null hypothesis. In other words, the difference between the 2016 and 2017 eco-efficiency distributions is not significant. This conclusion is corroborated by the descriptive statistics of the two groups and by , which represents the distributions, in box-plot format, of the eco-efficiencies of each group. This result must be supported by the low probability of significant changes in eco-efficiency from one year to another, where producers have low resources for investments.
Graph 3. Boxplot of the corrected eco-efficiency indexes for the groups (Source: elaborated by the authors).
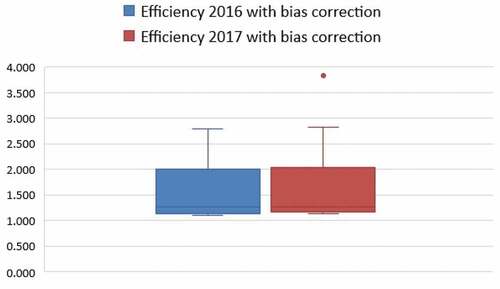
Table 4. Corrected eco-efficiency statistics for the Kolmogorov-Smirnov and Kruskal-Wallis groups and tests
5.3 Impact of climate variations on eco-inefficiency indices
Figures offer an overview of the temperature and precipitation levels, as well as the eco-efficiency indices calculated for the two years studied (2016 and 2017), respectively. The Figures do not allow us to visualize a clear pattern of correlation between climatic variables and eco-efficiency. Therefore, to understand the impact of climate on eco-efficiency, a Tobit regression analysis with bootstrap was performed between the corrected eco-efficiency (dependent variable) and the explanatory variables, temperature (T) and precipitation (P), considering their squared values (T^2 and P^2). With the four explanatory variables, the second stage model (Algorithm #1) by Simar and Wilson (Citation2007, Citation2011) with 2000 replications is appropriate for an improvement in the statistical inference capacity of the relationship. In the application, output-oriented eco-inefficiency is the dependent variable that must be greater than or equal to 1. Therefore, it is necessary to clarify that a negative sign indicates a positive effect on efficiency (decreases eco-inefficiency) and a positive sign indicates a worsening (increases eco-inefficiency). Table presents the results of the estimated model.
Figure 2. Temperature, precipitation, and eco-efficiency of 2016 in the study area.
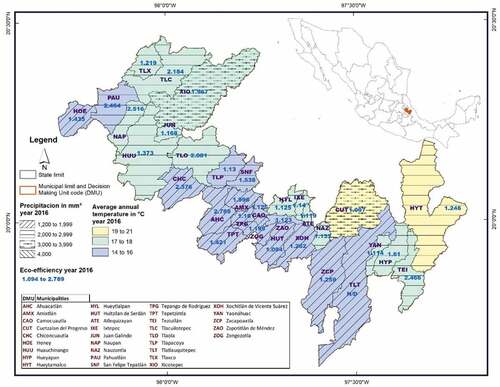
Figure 3. Temperature, precipitation, and eco-efficiency of 2017 in the study area.
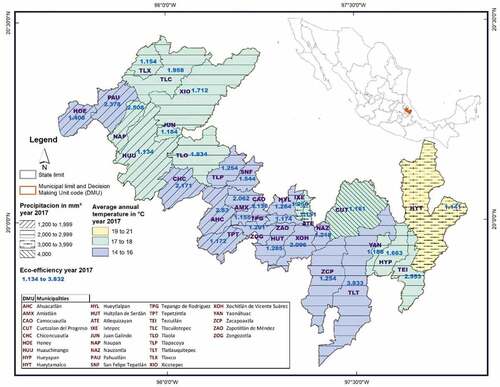
Table 5. Second stage model estimates
The results reveal that both temperature and precipitation coefficients are statistically significant, at the 5% level, but they have a different impact on the eco-efficiency of the studied municipalities. As the estimated coefficients of the Tobit model cannot be interpreted as if they were linear regression estimators, the mean marginal effects were calculated, considering the two coefficients of both variables (T and P). The average marginal effect of temperature results in −0.1610705, which indicates that increasing the temperature by one unit reduces the eco-inefficiency by that value on average. Therefore, the increase in temperature contributes to improving eco-efficiency. The average marginal effect of precipitation was 0.00065, which indicates that reduction of the precipitation by one unit increases the eco-inefficiency in this value on average. Therefore, it is observed that the partial effect of temperature variability is greater than that of precipitation, which is very small.
The positive effects of increased temperature and reduced precipitation on eco-efficiency should be based on the characteristics of the region—humid mountain forest with rain for most of the year and persistent mist almost at ground level. In addition, it is known that these effects would reduce excess humidity, that creates an ideal environment for fungal proliferation, as well as promote restrictions on gas exchange in the soil, causing O2 shortages and excess CO2, impairing root development and biological nitrogen fixation in crops such as coffee and corn”.
6 Final considerations
In this work, agricultural eco-efficiency was estimated using the window data envelopment analysis approach in the municipalities of Puebla located in TMCF, pointing out how much it is possible to maximize economic and environmental objectives, having as reference the best practices of the region in 2016 and 2017. We employed the multivariate data cloud method, to identify and eliminate outliers that affect the eco-efficiency indices. Then, using bootstrap techniques, the scale-return significance test was performed. Once the CRS technology was confirmed, the corrected score for the random bias inherent in the data was estimated, as well as testing the difference in the eco-efficiency of the municipalities between 2016 and 2017. Furthermore, as the estimated scores are affected by uncontrollable factors not considered in the eco-efficiency calculations, truncated Tobit regression models with bootstrap were used to investigate how these environmental variables influenced these scores. In this way, an important gap is filled concerning the assessment of the environmental and economic performance of agriculture in one of the most vulnerable biomes in Mexico.
The results indicate that there are marked eco-inefficient behaviors. It is possible, at an aggregate level across the studied area, to increase annual agricultural revenue and preserved areas by 58.7%, with the same inputs and environmental costs, or equivalently, to reduce inputs and GHG emissions by 36.98% with the same level of annual agricultural revenue and preserved areas. Thus, the first and second questions of this research are answered, and it is shown that the results provide decision makers with important practical contributions to define policies that support the harmonization of economic growth and environmental preservation, as well as adaptive actions to reduce vulnerability and improve the resilience of peasant producers in the TMCF area in the face of possible climate changes.
The regression results answer the third question of this research and indicated that the eco-efficiency scores are also significantly affected by climatic factors. The results show that changes manifested by reduced rainfall and increased temperature will have predominantly positive impacts on the region. This must be explained by the mountainous and humid characteristics of the TMCF area.
The finding seems to dispute the general conclusions found in other research. For example, in the work of Sagarpa (Citation2012) it is concluded that, in the region of the State of Puebla, the increase in temperature is related to a decrease in crop yields due to the stress caused by heat, the increase in fire. On the other hand, the reduction in rainfall has negative effects on productivity due to the incapacity of cultivation due to the lack of humidity, and dehydration of weeds and animals, among others. However, many of these researches are carried out considering extensive territories, warmer and more heterogeneous, disregarding the fact that the effects of climatic variations can be uneven in different regions. Hence, the importance of strengthening the studies in more homogeneous local scenarios that allow knowing the short-, medium- and long-term climate vulnerabilities to direct sustainable actions from the present.
Finally, it is necessary to emphasize that within the limitations of the study, one can consider the difficulty in obtaining disaggregated information to determine inputs, outputs, climatic data and to build a model with longer panel data. In this sense, as a line of future investigation, models are recommended that allow for the inclusion of trends in climate change, as well as contextual variables related to indicators of social, regional, and economic development.
Acknowledgements
The authors acknowledge the sponsorships from Consejo Nacional de Ciencia y Tecnología CONACYT(México); Secretaría de Investigación y Posgrado (SIP), IPN, México with the Project No. SIP20181987 and CIIEMAD- IPN are highly appreciated.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The database used and the data sources can be found in the open access link located in: https://data.mendeley.com/datasets/gf6xnkb5tw/1 and doi:10.17632/gf6xnkb5tw.1.
Additional information
Funding
Notes
1. In this case, the notion of mesophilic mountain woods is considered equivalent to the notion of Tropical Montane Cloud Forests.
References
- Aigner, D., Lovell, C. A., & Schmidt, P. (1977). Formation and estimation of stochastic frontier production function models. Journal of Econometrics, 6(1), 21–14. https://doi.org/10.1016/0304-4076(77)90052-5
- Banker, R. D. (1993, October). Maximum likelihood, consistency and data envelopment analysis: A Statistical foundation. Management Science, 39 (10), 1265–1273. https://doi.org/10.1287/mnsc.39.10.1265
- Banker, R., & Chang, H. (2006). The super-efficiency procedure for outlier identification, not for ranking efficient units. European Journal of Operational Research, 175, 1311–1320. Ed. Elsevier. https://doi.org/10.1016/j.ejor.2005.06.028
- Banker, R. D., Charnes, A., & Cooper, W. W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science, 30(9), 1078–1092. https://doi.org/10.1287/mnsc.30.9.1078
- Bogetoft, P., & Otto, L. (2011) Benchmarking with DEA, SFA, and . Ed. . ISSN pp. 0884–8289. Springer. ISBN 978-1-4419-7960-5 e-ISBN 978-1-4419-7961-2. https://doi.org/10.1007/978-1-4419-7961-2
- Bruijnzeel, L. A. (2001). Hydrology of tropical montane cloud forests: A reassessment. Land Use and Water Resources Research, 1(1732–2016–140258), 1.
- Charnes, A., Clark, C., Cooper, W., & Golany, B. (1984). A developmental study of data envelopment analysis in measuring the efficiency of maintenance units in the U.S. air forces. Annals Of Operations Research, 2(1), 95–112. https://doi.org/10.1007/BF01874734
- Charnes, A., Cooper, W., & Rhodes, E. (1978, Nov). Measuring the efficency of decision making units. European Journal of Operational Research, 2(6), 429–444. https://doi.org/10.1016/0377-2217(78)90138-8
- Cooper, W. W., Seiford, L. M., & Tone, K. (2007). Data envelopment analysis: A comprehensive text with models, applications, references and DEA-solver software (Vol. 2). Springer.
- Cruz-Cárdenas, G., Villaseñor, J. L., López-Mata, L., Martínez-Meyer, E., & Ortiz, E. (2014). Selección de predictores ambientales para el modelado de la distribución de especies en Maxent. Revista Chapingo. Serie ciencias forestales y del ambiente, 20(2), 187–201. https://doi.org/10.5154/r.rchscfa.2013.09.034
- Donatti, C. I., Harvey, C. A., Martinez-Rodriguez, M. R., Vignola, R., & Rodriguez, C. M. (2019). Vulnerability of smallholder farmers to climate change in central America and Mexico: Current knowledge and research gaps. Climate and Development, 11(3), 264–286. https://doi.org/10.1080/17565529.2018.1442796
- Efron, B., & Tibshirani, R. J. (1993). An introduction to the bootstrap (pp. 473). Chapman and Hall.
- Emrouznejad, A., & Yang, G.-L. (2018). A survey and analysis of the first 40 years of scholarly literature in DEA: 1978–2016. Socio-economic Planning Sciences, 61, 4–8. https://doi.org/10.1016/j.seps.2017.01.008
- Färe, R. (1988). Fundamentals of production theory. Springer-Verlag.
- Farrell, M. J. (1957). The measurement of productive efficiency. Journal of the Royal Statistical Society. Series A (General), 120(3), 253–281. https://doi.org/10.2307/2343100
- Gori-Maia, A., Silveira, R., Veneo, C., Burney, J., & Cesano, D. (2021). Climate resilience programmes and technical efficiency: Evidence from the smallholder dairy farmers in the Brazilian semi-arid region. Rev. Climate and Development. https://doi.org/10.1080/17565529.2021.1904812
- HernándezCayetano, M. (2020). Correlación espacial de ecoeficiencia y clima en los municipios poblanos del Bosque Mesófilo de Montaña de México. Tesis de Maestría, MCEAS-CIIEMAD-IPN, 27 de octubre de 2020. INSTITUTO POLITÉCNICO NACIONAL - CIIEMAD. https://tesis.ipn.mx/jspui/handle/123456789/29409
- Khanal, U., Wilson, C., Hoang, V.-N., & Lee, B. (2018). Farmers‘ Adaptation to Climate Change, Its Determinants and Impacts on Rice Yield in Nepal. Ecological Economics, Elsevier, 144(C), 139–147. https://doi.org/10.1016/j.ecolecon.2017.08.006
- Kummu, M., Heino, M., Taka, M., Varis, O., & Viviroli, D. (2021). Climate change risks pushing one-third of global food production outside the safe climatic space. Rev. One Earth, 4(5), 720–729. https://doi.org/10.1016/j.oneear.2021.04.017
- Lachaud, M., Bravo-Ureta, B., & Ludena, C. (2017). Agricultural productivity in Latin America and the Caribbean in the presence of unobserved heterogeneity and climatic effects. Rev. Climatic Change, 143(3–4), 445–460. http://dx.doi.org/10.1007/s10584-017-2013-1
- Lovell, C. K. (1993). Production Frontiers and Productive Efficiency. In H. O. Fried, C. K. Lovell, & S. S. Schmidt (Eds.), The measurement of productive efficiency-techniques and applications (pp. 3–67). Oxford University Press.
- Meeusen, W., & van den Broeck, J. (1977). Efficiency Estimation from Cobb-Douglas Production Functions with Composed Error. Published Wiley, Rev. International Economic Review, 18(2), 435–444. https://doi.org/10.2307/2525757
- Morton, J. (2007). The impact of climate change on smallholder and subsistence agriculture. Proceedings of the National Academy of Sciences, 104(50), 19680–19685. December 11, 2007 https://doi.org/10.1073/pnas.0701855104
- Mullen, J. (2007). Productivity growth and the returns from public investment in R&D in Australian broadacre agriculture. The Australian Journal of Agricultural and Resource Economics, 51(4), 359–384. https://doi.org/10.1111/j.1467-8489.2007.00392.x
- Ojo, T., & Baiyegunhi, L. (2020). Determinants of climate change adaptation strategies and its impact on the net farm income of rice farmers in south-west Nigeria. Rev. Land Use Policy, 95(1). https://doi.org/10.1016/j.landusepol.2019.04.007
- Sagarpa. (2012). México: El sector agropecuario ante el desafío del cambio climático. México: Secretaría de Agricultura, Ganadería, Desarrollo Rural, Pesca y Alimentación. http://www.sagarpa.gob.mx/programas2/evaluacionesExternas/Lists/Otros%20Estudios/Attachments/37/Cambio%20Climatico.pdf
- Sánchez-Ramos, G., & Dirzo, R. (2014). El bosque mesófilo de montaña: Un ecosistema prioritario amenazado. In Gual-Díaz, M. y A. Rendón-Correa (comps.). Bosques Mesófilos de Montaña de México: Diversidad, Ecología y Manejo (pp. 109–139). 978-607-8328-07-9. Comisión Nacional para el Conocimiento y Uso de la Biodiversidad. https://www.academia.edu/12475725/Bosque_Mes%C3%B3filos_de_Monta%C3%B1a_de_M%C3%A9xico_diversidad_ecolog%C3%ADa_y_manejo
- Shephard, R. W. (1970). The Theory of Cost and Production Functions. Princeton University Press.
- Shephard, R. W. (1971). Theory of Cost and Production Functions. Ed. Princeton University Press.
- Simar, L. (1992). Estimating efficiencies from frontier models with panel data: A comparison of parametric, non-parametric and semi-parametric methods with bootstrapping. Journal of Productivity Analysis, 3(1–2), 167–203. https://doi.org/10.1007/978-94-017-1923-0_11
- Simar, L., & Wilson, P. W. (1998). Sensitivity analysis of efficiency scores: How to bootstrap in nonparametric frontier models. Management Science, 44(1), 49–61. http://dx.doi.org/10.1287/mnsc.44.1.49
- Simar, L., & Wilson, P. W. (2000). Statistical inference in nonparametric frontier models: The state of the art. Journal of Productivity Analysis, 13(1), 49–78. https://doi.org/10.1023/A:1007864806704
- Simar, L., & Wilson, P. W. (2002). Non-parametric tests of returns to scale. European Journal of Operational Research, 139(1), 115–132. https://doi.org/10.1016/S0377-2217(01)00167-9
- Simar, L., & Wilson, P. W. (2007). Estimation and inference in two-stage, semi-parametric models of production processes. Journal of Econometrics, 136(1), 31–64. https://doi.org/10.1016/j.jeconom.2005.07.009
- Simar, L., & Wilson, P. W. (2011). Two-stage DEA: Caveat emptor. Journal of Productivity Analysis, 36(2), 205–218. https://doi.org/10.1007/s11123-011-0230-6
- Simar, L., & Wilson, P. W. (2015). Statistical approaches for non-parametric frontier models: A guided tour. International Statistical Review, 83(1), 77–110. https://doi.org/10.1111/insr.12056
- Villaseñor, J. L. (2010). El bosque húmedo de montaña en México y sus plantas vasculares.Catálogo florístico-taxonómico. Comisión Nacional para el Conocimiento y Uso de la Biodiversidad-Universidad Nacional Autónoma de México. Springer.
- Villavicencio, X., McCarl, B. A., Wu, X., & Huffman, W. E. (2013). Climate change influences on agricultural research productivity. Rev. Climatic Change, 119(3–4), 815–824. https://doi.org/10.1007/s10584-013-0768-6
- Wilson, P. W. (1993). Detecting outliers in deterministic nonparametric frontier models with multiple outputs. Journal of Business and Economics Statistics, 11(3), 319–323. https://doi.org/10.2307/1391956
- Wilson, P. W. (2008). FEAR: A software package for frontier efficiency analysis with R. Socio-Economic Planning Sciences, 42(4), 247–254. https://doi.org/10.1016/j.seps.2007.02.001