
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Techniques for the semantic segmentation of remotely sensed imageries for building footprint identification have been widely studied and several supervised and unsupervised techniques have been proposed. The ability to perform online mapping and accurate segmentation on a large scale by taking into account the multifariousness inherent in aerial images has important implications. In this paper we propose a new method for building footprint identification using multiresolution analysis-based self-attention technique. The scheme is promising to be robust in the face of variability inherent in remotely sensed images by virtue of the capability to extract features at multiple scales and focusing on areas containing meaningful information. We demonstrate the robustness of the proposed method by comparing it against several state-of-the-art techniques using aerial imagery with varying spatial resolution and building clutter and it achieves better accuracy around 95% even under widely disparate image characteristics. We also evaluate the ability for online mapping on an embedded graphic processing unit (GPU) and compare it against different compute engines and it is found that the proposed method on GPU outperforms the other methods in terms of accuracy and processing time.
1. Introduction
The rapid rate of urbanisation demands rapid infrastructure development to accommodate surging population into the cities. It is, therefore, vital to design and regulate the use of space in urban areas. Out of the myriad parameters that influence the design and regulation of space, building detection has an indispensable implication in urban planning and analysis. Identification and mapping of built-up areas play a pivotal role in several applications including urban analysis, updating maps, change assessment, disaster management and transportation planning.
Identifying and demarcating built-up areas is difficult due to the nature of these classes, which requires extraction and analysis of spatial features, topological spread with scale complexities. Despite the automations in this task, there is still a large dependence on manual annotations, which is time consuming and prone to errors due to the presence of observational variations. Thus, there is a need for rapid and reliable automatic segmentation techniques.
The ability to perform online mapping and segmentation with the help of embedded GPUs, such as as NVIDIA’s Jetson Nano mounted on drones, is a step in this direction. Drones with their ability to cover large swathes of land, coupled with a high accuracy framework for processing of the captured scene, will promote rapid urban mapping and understanding, leading to improved urban planning.
Traditional methods use texture, shape, spectral and spatial features followed by clustering or classification algorithms (Sharma & Singhai, Citation2021; Xu et al., Citation2018). In the recent past, the advent of deep learning techniques and its proliferation into remote sensing applications including building and road detection have achieved significant improvement in the performance (Cao et al., Citation2021; Yongtao et al., Citation2021; Libo et al., Citation2022). Lu et al. (Citation2018) introduced a dual-resolution U-Net to capture features of multisource data to improve multiscale inference and enrich contextual information by optimising building boundaries. Liu et al. (Citation2019) proposed a convolutional neural network (CNN) in encoder-decoder framework for extracting and integrating the multiscale features for building footprint extraction. Li et al. (Citation2021) investigated a multiple feature reuse network to directly extract hierarchical features for building segmentation. Azimi et al. (Citation2019) introduced a fully connected neural network in combination with discrete wavelet transform features to capture multiscale features for improved performance. Kang et al. (Citation2021) proposed a deep learning approach to discriminate building and background pixels from a highly skewed data using cross entropy feature. While deep learning methods lend themselves well to these applications, these architectures need to cope with the broad spectrum of variations ranging from nature of imaging to the diversity of backgrounds while simultaneously tackling the varying shape, size and appearance of buildings in aerial images.
In this paper, we propose a new method based on multiresolution analysis (MRA) utilising dual self-attention (SA) features that improve the accuracy of detection and extraction of buildings from remotely sensed images. As MRA has a capability to extract features at different scales and orientations manifested by the built-up areas, it served as a motivation to fuse MRA features in a self-attentive framework, which allows the model to focus and extract regions consisting of meaningful information by virtue of assigning varying importance to different regions. The MRA feature in combination with attention module is a novel way to extract multiscale details for building detection application. The contributions of this work include implementation of MRA-based dual attention technique, identifying role of MRA features, position attention, channel attention and progressive generation of features for ablation analysis. The method is developed on a Jetson Nano standalone GPU compute engine which can be installed on a drone for online mapping.
2. Methods and materials
The architecture of proposed network is shown in . It consists of three modules: the feature extraction backbone, multi-level multiresolution feature augmentation and the dual attention module. The feature extraction backbone has been used in this method to extract features at multiple scales for a given input aerial image. These extracted features at multiple levels of the backbone are augmented with multi-resolution features which together provide the joint multiscale feature map of the aerial image. Finally, these learned features, along with the joint multiscale feature map, are fed into a dual-attention module, which is composed of position and channel self-attention modules that enables the network to pay closer attention – more weightage – to a particular region of the feature map at the expense of other regions. Such an amalgamation of a multiresolution framework along with self-attention allows adaptive integration of local features with their global dependencies.
Figure 1. Proposed architecture of self-attention multiresolution analysis.
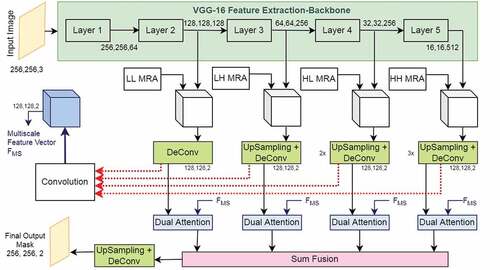
2.1. Feature extraction backbone and multiresolution analysis
In this work, two different representative backbones for feature extraction have been investigated: VGG-16 (Simonyan et al., Citation2014) the ResNet50 (Kaiming et al., Citation2016). While both backbones provide comparable results, in this paper, the VGG-16 backbone has been chosen due to its lightweight nature and lower inference latency for implementation in embedded GPUs like Jetson Nano. Along the similar lines, all the layers of the original VGG-16 network have not been used, instead only the initial few layers until the fourth max-pooling block have been employed. It was found that such an arrangement, while conducive enough to learn a rich feature representation, also favoured lower latencies (Ye et al., Citation2021).
An image on decomposition with the 2D discrete wavelet transform (DWT) is decomposed into one approximation and three other sub-bands in horizontal, vertical and diagonal directions. The approximation of the input image is a low-frequency subband (LL), the horizontal subband is called LH which extracts horizontal features from the input image, the HL or the vertical subband extracts vertical image features and HH or diagonal subband extracts diagonal subbands. The LH, HL and HH together form the detailed subbands. The three detail sub-bands are stacked together to augment the multiscale feature maps, which aid the network by supplementing it with details of singularity, and the approximation band serves as an input to the subsequent wavelet decomposition. Multiple levels of wavelet decompositions have been employed to augment all the learned multiscale feature maps. These feature maps are then concatenated together and then convolved to create a joint multi-scale feature map, which allows efficient capturing of global and local contextual directional information.
2.2. Dual attention
A self-attention framework inspired by the dual attention network (Fu et al., Citation2019) has been introduced in this work. Two synchronous attention modules, the position attention module and the channel attention module, have been employed to effectively capture feature connectedness in spatial and channel dimensions. Such an arrangement allows any two positions having similar features either within a channel or across channels to contribute mutual improvement in response to that particular feature. The local and global contextual information captured by the multiresolution framework tends to be noisy inherently due to the nature of the acquired aerial image. The attentions modules help de-clutter the extracted features by focusing on features that are crucial to improving the segmentation performance by nature of its weighting scheme. The attention module can, in essence, be thought of as performing a combination of denoising and enhancement of the feature space by the transformation to a domain where not all spatial and channel features are equally weighted. Additionally, since receptive fields in traditional fully connected networks are reduced to a local level, they are not able to model detailed long-range contextual information from a rich combination of local and global features. The dual attention mechanism helps overcome such associated problems with the help of position and channel attention modules. details the schematic of position and channel attention modules with different matrix connections.
Figure 2. Dual attention mechanism.
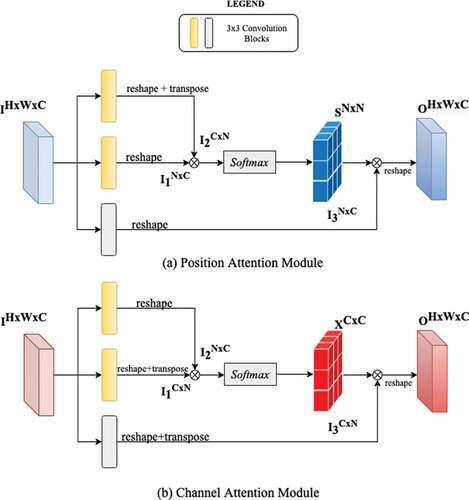
2.2.1. Position attention module
To model long-range connectedness within each channel and also to extract features of greater importance in a spatial context, we utilise the position attention module. For an input feature map, two new feature maps
are extracted by passing it through two disparate adaptive convolutional layers. To generate the spatial attention matrix S, I1 and I2 are reshaped into two-dimensional matrices of shape
where,
and then matrices are multiplied as follows to produce the spatial attention matrix S of shape
.
This adaptively generated spatial attention matrix from the input multi-resolution feature map represents the correlation between different regions within a channel map. Finally, the input feature map I after passing through another adaptive convolutional layer is multiplied with S and reshaped back to. The spatial attention matrix has different response to different regions of the feature map and helps give more ‘attention’ to certain regions of the image. Therefore we are able to selectively aggregate features from multiple resolutions in a global context.
2.2.2. Channel attention module
Each channel map input to our attention module has a class-specific response both at a particular resolution and in the joint multi-scale feature. It is important to find the interdependencies among these feature maps in addition to the intra-feature dependencies since they greatly improve the semantic representation by reducing misclassifications. The channel attention computation is similar to the position attention module except for the calculation of the channel attention matrix, which is done along the channel dimension to extract long range dependencies among feature maps. The channel attention matrix is generated from the same reshaped feature maps (I1, I2) as
.
The output of the spatial (P) and channel attention (Q) modules is element wise fused and then passed through a softmax layer to generate the combined output of the attention block represented as Ai (ith attention block),
The combined joint-multi scale feature map as described above along with the feature maps generated at different scales after up-sampling are fed into the dual attention network, with a dedicated attention block for each scale. The attention blocks operate on feature maps only half the size of the original image and with just four feature channels – one feature map per class from features at a particular resolution and also from the joint multi-scale feature map. Since the attention blocks employ expensive computation structures, such a choice of spatial and channel parameters enables real-time computation on embedded GPUs. Specifically, four channels per attention block were chosen because each pair of channels encodes a class-specific response at a specific scale and at the joint multi-scale and since this is a single class identification problem, four channels were sufficient enough to exploit the interdependencies among channel spaces and improve the feature representation of particular semantics.
The output of each attention block Ai at different scales is then element-wise sum fused to generate the joint scale attention map (A) to further enhance feature representation that contributes to more accurate results. The joint scale attention map is calculated as follows
The resultant feature map is passed through an up-sampling and pixel-wise deconvolution block to generate the final semantically segmented result having the same spatial resolution of the input data and two channels representing the class-wise response.
2.3. Progressive generation
For training purpose, progressively growing network architecture has been employed. The finest resolution aerial image – represented as , where H, W are the image dimensions – was downscaled to the coarsest resolution image represented as
where, N is the number of iterations progressive generation was carried out. The network was trained starting from this coarse input resolution and resolution gradually increased to the finest possible level. Initially, a segmentation mask at a lower resolution generated and then, the weights learnt at this resolution areused to predict the next higher resolution and update the weights in the process while simultaneously resulting in successive refinement of the segmentation mask. The progression from coarse to finer resolution for a particular iteration was done according to the following equation (Dai & Niessner, Citation2020),
where, the function upscale() function implements bilinear interpolation with a scale factor of two and is the network supervision signal (as detailed in the following section) and
is an empirically determined threshold. This enables successive refinement of the segmentation mask and results in homogenous semantics.
2.4. Loss function
In general, semantic segmentation tasks, involving remote sensing images, exhibit a wide class disparity. Hence, focal loss as the supervision signal (Lin et al., Citation2017) has been employed for the network over the standard cross-entropy loss, in order to handle the class imbalance in the training data.
The focal loss utilises a modulation term on the standard cross entropy loss, which allows the supervision signals to depend more heavily on regions that are misclassified and difficult to segment due to the inherent nature of the scene. This modulating term is dynamically scaled down to zero as the confidence in segmentation increases and the focal loss tends to standard cross entropy as the modulation term tends to zero. The focal loss is expressed as follows
where, is the modulating factor,
is the weighting parameter to account for class imbalance, p is the predicted probability and y is the ground-truth class.
3. Results and discussions
For the purpose of this study, the performance of the proposed method was evaluated on the WHU data set (Ji et al., Citation2019) and the OpenCities data set (GFDRR labs, Citation2020). The WHU data set comprises more than 220,000 independent buildings captured from aerial images with 7.5 cm spatial resolution, spanning an area of 450 km2 covering the city of Christchurch in New Zealand. The OpenCities dataset consists of 790,000 building footprints from 10 cities and regions in Africa extracted from OpenStreetMap. The resolution of the aerial imagery varies from region to region, varying from 0.03 m − 0.2 m. For these experiments, aerial imagery from four cities (Accra, Dar-es-Salaam, Zanzibar and Kampala) have been used, so as to have a robust dataset consisting of densely and sparsely populated regions alike. The area covered by the combined dataset is diverse, ranging from countryside to industrial areas consisting of multifarious architectures.
To evaluate the semantic segmentation performance of the proposed model, evaluation metrics including mean intersection over union (mIoU), F1-score (F1), and overall pixel accuracy (PA) have been used.
3.1. Training and implementation
The VGG16 feature extraction backbone with pre-trained weights with provision of enabled further learning of the VGG16 layers to the data during the course of training the entire network. For the multi-resolution framework, the images were decomposed using several different families of wavelets like Daubechies and biorthogonal. The complete network was trained on the NVIDIA Tesla P100 GPU using the Adam optimiser with a batch size of 16, and with β1 and β2 set to 0.9 and 0.99, respectively. As mentioned above, progressive generation has been used to train the network. Therefore, the training was begun with input image chips of size — extracted from the original remotely sensed image – until convergence, followed with suit on chips of size
until the network converged on input image chips of size
. Convergence on the final input image size was reached within the first 170 epochs. Several image augmentation procedures have been employed, such as rotation, translation etc., to expand the data. Both the datasets used in this study consisted of separate train and test data, which were utilised in the appropriate scenarios.
Several other deep learning and transformer based networks have been designed and deployed to compare them against the proposed network, such as enhanced SVM (Q. Zhang & Guo, Citation2007), U-Net (Ronneberger et al., Citation2015), Deep Residual U-Nets (Z. Zhang et al., Citation2018), FCN32 (Long et al., Citation2015), ScattNet (Li et al., Citation2021), ASF-net (Chen et al., Citation2022), CG-Swin (Meng et al., Citation2022), Buildformer (Wang et al. 2022a), and UNetFormer (Wang et al., Citation2022). All these models were developed using the Tensorflow platform (version 1.13) and trained on the same dataset in line with the proposed network until they overfit.
To verify the suitability of the proposed network for drones and embedded GPUs, the throughput of the network has been evaluated on the NVIDIA Jetson Nano 4GB Developer Kit and its latency has been compared and contrasted against the Tesla P100 GPU and a Quad Core Intel i5 CPU at 2 GHz.
3.2. Discussion
shows the results for the WHU dataset. From the semantic segmentation results, it is evident that the proposed method has a superior segmentation quality as compared to several other traditional and deep learning frameworks. Our method achieves a 4% increase in mIoU and a 2.4% increase in overall accuracy over the other techniques (). These advancements in the quantitative metrics demonstrate the superiority and the utility of a multi-resolution framework coupled with self-attention in improving the quality of the semantic segmentation of remotely sensed images for building extraction. The first row in highlights the improved segmentation results of the proposed network in its ability to extract sharp and real-world building shaped masks from the aerial images as compared to a U-Net whose extracted building footprints are random oblong blobs. The proposed network not only extracts straight edged buildings as accurately as possible, but also manages to extract circular or elliptical shaped buildings with very high accuracy in terms of structure as opposed to ResUnet for example whose extracted building footprints are extremely noisy and do not have homogenous semantics. Similarly in second row in (another sample from WHU dataset), the superiority of the method has been further demonstrated by showing the ability of the MRA framework coupled with the attention mechanism to be able to extract very thin building structures very accurately while maintaining the original shape and orientation of built-up structure.
Figure 3. Column-wise (a) Input image, (b) ground truth, and segmentation results of (c) SVM, (d) UNet, (e) ResUNet, (f) Proposed method of MRA-SA on the WHU building dataset with four samples (row-wise).

Table 1. Performance comparison for the WHU dataset.
To further cement the robustness of the proposed method, the results have been compared with the OpenCities dataset. shows the qualitative results where first row shows aerial images taken over Accra and the second row uses aerial images of Kampala. In the Accra image, the proposed method is able to extract clean and independent building footprints even in heavily cluttered regions as shown in the crops accompanying the figure. Whereas U-Net and ResUnet are unable to extract individual footprints and all the building masks are clumped together into one giant mass, which is not a suitable trait for several applications involving urban planning. Similarly, in the Kampala image of an industrial area in the second row, the proposed method is able to identify and extract extremely thin building structures and also reduce misclassifications as is excessively evident when compared against the ResUnet segmentation results. This results in better mIoU of 0.931 and pixel accuracy of 96.32% using the proposed method (). Additionally, the method is visibly robust to changing spatial resolutions and clutters and background variations, owing to the enhanced feature augmentations using multiresolution framework coupled with the attention module.
Figure 4. Column-wise (a) Input image, (b) ground truth, and segmentation results of (c) SVM, (d) UNet, (e) ResUNet, (f) Proposed method of MRA-SA on the OpenCities building dataset with four sample images (row-wise).

Table 2. Performance comparison for the OpenCities dataset.
3.3. Ablation studies
We use the single-scale VGG-16 network with structure similar to the feature extraction backbone used in the proposed method as the baseline in the ablation study. We then demonstrate the effectiveness of different components in the proposed method by progressively incorporating each module. The comparison results are shown in . The default setting for all experiments in the ablation is with progressive generation training, unless explicitly specified. Specifically, from it is evident that using the multiresolution features and joint multi-scale features and the dual attention mechanism results in 14% and 10% improvement over the baseline. Similarly, the utility of the attention mechanism in improving the semantic segmentation results is realised, where using the dual attention mechanism over rudimentary position or channel attention mechanism results in significant gains in qualitative performance. Furthermore, we also investigated the effect of the progressive generation training framework to the building extraction performance. It is evident from that using the proposed progressive generation training significantly improves the performance of the model across all the reported metrics. This is attributed to its ability to successively refine the segmentation mask which results in homogenous semantics.
Table 3. Ablation results.
shows the segmentation result using only MRA features, and shows the results without using MRA features. shows the final results obtained from the complete proposed network. The utility of the MRA framework is in having the extracted building footprints resemble as close as possible to real world buildings and also be able to identify and extract very fine structures, and buildings of varying shapes and sizes. The dual attention mechanism helps capture crucial long range dependencies to obtain precise segmentation results, which is particularly useful in cluttered scenes. Also, the attention mechanism helps make the network oblivious to the image acquisition characteristics, like its spatial resolution and results in uniform and homogenous semantics.
Figure 5. (A) Input image, (b) ground truth, and segmentation results of (c) SVM, (d) UNet, (e) ResUNet, (f) Only MRA features, (g) Only SA features (h) Proposed method of MRA-DA on the WHU building dataset.

3.4. Compute engine performance
By leveraging the CUDA API, common workloads in the proposed framework such as convolutions, matrix multiplications, dot products are parallelised using multiple CUDA kernels. These kernels greatly speedup the computation flow by processing image streams from multiple resolutions simultaneously as opposed to a single core CPU implementation. summarises the performance in frames per second (fps) and execution time of a single frame in milliseconds of the CPU (python code running on a single core), Tesla P100 GPU and the Jetson Nano (4GB). The Tesla P100 GPU implementation achieves real-time performance of over 25 fps, achieving nearly a 125× speedup over the CPU implementation. Whereas, the Jetson Nano is able to achieve a performance of 10.54 fps and a 45× speedup over the CPU. The Jetson Nano implementation lags behind the Tesla P100 in performance mainly due to the lack of enough parallel compute threads, however it nevertheless manages to achieve better performance as compared to that of CPU, under a heavily resource constrained environment, utilising only a fraction of the power of the Tesla P100.
Table 4. Compute engine comparison.
To further cement the efficiency of the proposed network, we compare the time performance and memory utilisation against top performing and lightweight methods alike from and list it in . It is evident from that our method achieves the best time performance and memory utilisation against the listed methods thus making our method well-suited for rapid building detection in heavily resource-constrained and challenging detection environments.
Table 5. Quantitative network efficiency comparison on the Jetson Nano (4GB) on an input of size 256 × 256 with select methods from .
4. Conclusion
In this paper, we proposed a supervised technique for the semantic segmentation of aerial imagery that is robust in the face of varying aerial image characteristics due to the enhanced feature representation capability of MRA at multiple scales and the successive refinement of these features by self-attention modules. Multiple levels of wavelet decomposition were utilised to augment the multiscale features from the lightweight feature extraction backbone to create a joint multiscale multiresolution feature map. These joint features are refined by virtue of the self-attention framework implemented as a dual attention module that is able to selectively extract features that consist of vital information which leads to improved segmentation performance. We demonstrated the cogency of the proposed method both quantitatively and qualitatively in terms of the geometric intactness of the extracted buildings and highlighted the superiority of our technique over several supervised frameworks. We additionally showed the utility of the proposed method by deploying it on a standalone embedded GPU to achieve near real-time segmentation of aerial imagery.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The data that support the findings of this study are openly available in GFDRR at https://doi.org/10.34911/rdnt.f94cxb
References
- Azimi, S. M., Fischer, P., Korner, M., & Reinartz, P. (2019, May). Aerial LaneNet: Lane-marking semantic segmentation in aerial imagery using waveletenhanced cost-sensitive symmetric fully convolutional neural networks. IEEE Transactions on Geoscience and Remote Sensing: A Publication of the IEEE Geoscience and Remote Sensing Society, 57(5), 2920–2938. https://doi.org/10.1109/TGRS.2018.2878510
- Cao, R., Fang, L., Lu, T., & He, N. (2021, Jan). Self-attention-based deep feature fusion for remote sensing scene classification. IEEE Geoscience and Remote Sensing Letters, 18(1), 43–47. https://doi.org/10.1109/LGRS.2020.2968550
- Chen, J., Jiang, Y., Luo, L., & Gong, W. (2022). ASF-Net: Adaptive screening feature network for building footprint extraction from remote-sensing images. IEEE Transactions on Geoscience and Remote Sensing, 60, 1–13. https://doi.org/10.1109/TGRS.2022.3165204
- Dai, C. D., & Niessner, M. (2020). SG-NN: Sparse generative neural networks for self-supervised scene completion of RGB-D scans. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 846–855. https://doi.org/10.1109/CVPR42600.2020.00093.
- Fu, J. Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z. and Lu, H. (2019). Dual attention network for scene segmentation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3141–3149. https://doi.org/10.1109/CVPR.2019.00326.
- GFDRR Labs. (2020). Open cities AI challenge dataset”, version 1.0, 20 Dec. 2021. Radiant MLHub. https://doi.org/10.34911/rdnt.f94cxb
- Ji, S., Wei, S., & Lu, M. (2019, Jan). Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Transactions on Geoscience and Remote Sensing, 57(1), 574–586. https://doi.org/10.1109/TGRS.2018.2858817
- Kaiming, H., Zhang, X., Ren, S. and Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, USA.
- Kang, J., Fernandez-Beltran, R., Sun, X., Jingen, N., & Plaza, A. (2021). Deep learning-based building footprint extraction with missing annotations. IEEE Geoscience and Remote Sensing Letters, 19, 1–5. https://doi.org/10.1109/LGRS.2021.3072589
- Libo, W., Rui, L., Zhang, C., Fang, S., Duan, C., Meng, X., & Atkinson, P. M. (2022). UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS Journal of Photogrammetry and Remote Sensing, 190, 196–214. https://doi.org/10.1016/j.isprsjprs.2022.06.008
- Li, R., Duan, C., Zheng, S., Zhang, C., & Atkinson, P. M. (2021). MACU-Net for semantic segmentation of fine-resolution remotely sensed images. IEEE Geoscience and Remote Sensing Letters, 1, 1–5. https://doi.org/10.1109/LGRS.2021.3052886
- Li Liu, Y., Yin, H., Li, Y., Guo, Q., Zhang, L. and Du, P. (2021). Attention residual U-Net for building segmentation in aerial images. IEEE International Geoscience and Remote Sensing Symposium IGARSS, 4047–4050. https://doi.org/10.1109/IGARSS47720.2021.9554058.
- Lin, T.Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. Proceedings of the IEEE international conference on computer vision, Venice, Italy.
- Li, H., Qiu, K., Chen, L., Mei, X., Hong, L., & Tao, C. (2021, May). SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters, 18(5), 905–909. https://doi.org/10.1109/LGRS.2020.2988294
- Liu, Y., Yao, J., Lu, X., Xia, M., Wang, X., & Liu, Y. (2019, Apr). RoadNet: Learning to comprehensively analyze road networks in complex urban scenes from high-resolution remotely sensed images. IEEE Transactions on Geoscience and Remote Sensing: A Publication of the IEEE Geoscience and Remote Sensing Society, 57(4), 2043–2056. https://doi.org/10.1109/TGRS.2018.2870871
- Long, J., Shelhamer, E., & Darrell, T. (2015, Jun). Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, USA (pp. 3431–3440).
- Lu, K., Sun, Y., & Ong, S. (2018). Dual-resolution U-Net: Building extraction from aerial images. 24th International Conference on Pattern Recognition (ICPR), 489–494. https://doi.org/10.1109/ICPR.2018.8545190.
- Meng, X., Yang, Y., Wang, L., Wang, T., Rui, L., & Zhang, C. (2022). Class-guided swin transformer for semantic segmentation of remote sensing imagery. IEEE Geoscience and Remote Sensing Letters, 19, 1–5. https://doi.org/10.1109/LGRS.2022.3215200
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional net- works for biomedical image segmentation. In N. Navab, H. Joachim, M. W. William, & A. Frangi (Eds.), Proceedings of International Conference Medical Image Computing and Computer-Assisted Intervention (pp. 234–241). Springer.
- Sharma, D., & Singhai, J. (2021). An unsupervised framework to extract the diverse building from the satellite images using Grab-cut method. Earth Sci Inform, 14(2), 777–795. https://doi.org/10.1007/s12145-021-00569-7
- Simonyan, K., Zisserman, A., & Zisserman, A. Learning local feature descriptors using convex optimisation. (2014). IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(8), 1573–1585. arXiv preprint arXiv:1409.1556. https://doi.org/10.1109/TPAMI.2014.2301163
- Wang, L., Fang, S., Meng, X., & Rui, L. (2022). Building extraction with vision transformer. IEEE Transactions on Geoscience and Remote Sensing, 60, 1–11. https://doi.org/10.1109/TGRS.2022.3186634
- Xu, S., Pan, X., Li, E., Wu, B., Bu, S., Dong, W., Xiang, S., & Zhang, X. (2018, Dec). Automatic building rooftop extraction from aerial images via hierarchical RGB-D priors. IEEE Transactions on Geoscience and Remote Sensing, 56(12), 7369–7387. https://doi.org/10.1109/TGRS.2018.2850972
- Ye, M., Ruiwen, N., Chang, Z., Gong, H., Tianli, H., Shijun, L., Sun, Y., Tong, Z., & Ying, G. (2021). A lightweight model of VGG-16 for remote sensing image classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14, 6916–6922. https://doi.org/10.1109/JSTARS.2021.3090085
- Yongtao, Y., Yinyin, L., Liu, C., Wang, J., Changhui, Y., Jiang, X., Wang, L., Liu, Z., & Zhang, Y. (2021). MarkCapsNet: Road marking extraction from aerial images using self-attention-guided capsule network. IEEE Geoscience and Remote Sensing Letters, 19, 1–5. https://doi.org/10.1109/LGRS.2021.3124575
- Zhang, Q., & Guo, L. (2007). Self-enhanced SVM extraction of building objects from high resolution satellite images. Second International Conference on Innovative Computing, Informatio and Control (ICICIC 2007), 13. https://doi.org/10.1109/ICICIC.2007.511.
- Zhang, Z., Liu, Q., & Wang, Y. (2018, May). Road extraction by deep residual U-Net. IEEE Geoscience and Remote Sensing Letters, 15(5), 749–753. https://doi.org/10.1109/LGRS.2018.2802944