
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper investigates the issue of disturbance observer-based fuzzy adaptive optimal finite-time control in light of the backstepping approach for strict-feedback nonlinear systems with bias fault term and full state constraints. Considering that external disturbance and bias fault signal can affect the stability of control and control quality, a disturbance observer is constructed to track the external disturbances and bias fault online. A disturbance observer-based finite-time control strategy is proposed to achieve optimized control by utilizing the fuzzy logic system approximation-based adaptive dynamic programming method under the critic-actor framework. The purpose of the critic is to evaluate control performance and the role of the actor is to execute control behaviour. In addition, it is proved that the proposed fuzzy adaptive optimal finite-time scheme not only realizes all signals in closed-loop system are bounded, but also ensures that system states are restricted within specific sets. Finally, simulation results are shown to demonstrate the effectiveness of the proposed control strategy.
1. Introduction
In the past few decades, the research on controller designing for nonlinear systems speedy developed neural networks and fuzzy approximation characteristics [Citation1–4]. The incipient control strategies facilitate the control objectives for nonlinear systems are realized in a infinite time, which means that the stability of systems fails to be guaranteed in a finite time. However, in practical problems, it is imperative to achieve superior control performance in a finite time.
Dissimilar to asymptotic stability, finite-time stability converges fast without the requirement of long-term transient response, so it is widely concerned and applied to practical systems such as aircraft flight systems [Citation5], cart-pole systems [Citation6], teleoperation systems [Citation7] and so on. Bhat and Bernstein [Citation8] explained finite-time stability based on Lyapunov theory and constructed feedback controller for nonlinear systems to achieve finite-time stability. Qiu et al. [Citation9] established a fuzzy finite-time controller for nonlinear systems and realized the tracking error is limited to a bounded set. Li et al. [Citation10] studied the problem of finite-time containment control involving unmeasurable states for nonlinear multiagent systems with input delay. Zhang et al. [Citation11] designed an adaptive fuzzy control strategy based on finite-time stability criterion for nonlinear systems with unavailable states, in which all states are confined to restricted sets. Meng et al. [Citation12] developed a finite-time quantized controller for dealing with the nonlinear systems contingent on unknown control directions, which constructed state and disturbance observers simultaneously. Sui et al. [Citation13] constructed an event-trigger adaptive finite control scheme by combining backstepping and varying threshold condition for stochastic nonlinear systems with unmodelled dynamics. Saravanakumar et al. [Citation14] first investigated the finite-time stability problem. The authors in [Citation15–17] studied the issue of finite-time control for nonlinear systems in accordance with full-state constraints. Nguyen et al. [Citation18] introduced a fuzzy control strategy for parallel manipulators to guarantee that the error of tracking converges fast in a finite time. Wang et al. [Citation19] constructed a finite-time control algorithm for stochastic nonlinear systems with actuator faults. Nevertheless, the above literature take the finite time into account and the designed control strategies ensure that the control objective can be achieved within the finite time. However, these literature do not involve the optimal control to deal with the problem of resource consumption.
In recent years, optimal control has been a striking topic, and it is concerned with establishing control strategies to achieve control objectives with the least resources in regard to optimal policy. In other words, the goal of optimal control is to consume the least amount of resources to achieve the control objective. For nonlinear systems, it is noteworthy that the resolve of Hamilton–Jacobi–Bellman (HJB) equation is imperative in the control process, but it is problematic to get analytic solutions because of the dynamic uncertainty and strong nonlinearity in the actual control. To overcome this problem, the dynamic programming (DP) was developed by Bellman [Citation20]. Noted that although DP is an effective tool for obtaining optimal solutions, it is prone to the curse of dimensionality, that is, increasing dimensions bring computational disasters. Adaptive dynamic programming (ADP)-based algorithms were demonstrated to efficiently conquer the problem. Werbos [Citation21] developed ADP for discrete systems and Abu-Khalaf and Lewis [Citation22] proposed ADP control scheme for continue-time nonlinear systems where the neural networks approximation structure was established to estimate the value function of the HJB equation. Vamvoudakis et al. [Citation23] developed an online actor-critic scheme combined with neural networks for continue-time systems. Wen et al. [Citation24] designed an optimized formation control strategy in reference with identifier-actor-critic structure and approximation characteristic of fuzzy logic systems. Li and Li [Citation25] introduced a fuzzy adaptive optimal fault-tolerant control scheme for stochastic multiagent systems to incorporate Butterworth low-pass filter, which leverages to compensate for negative influence caused by nonlinear fault on the system. Wen et al. [Citation26] reviewed the fuzzy adaptive optimized control issue subject to unmeasured states with nonlinear systems, in which the state observer satisfies the Hurwitz condition that sidestep constant designing. Lan et al. [Citation27] introduced an adaptive optimal formation control technology for multiagent systems with unmeasurable states. Li et al. [Citation28] designed a neural network adaptive optimized control algorithm exposing to immeasurable states and constrained states with nonlinear systems. The authors in [Citation29–31] discussed the problem of adaptive optimal control for nonlinear systems. Wen et al. [Citation32] built an adaptive optimal control scheme by virtue of identifier–critic–actor architecture. To achieve high precision control requirements, it is necessary to consider the influence of external disturbance on the system, which makes sense to design an optimal finite-time control strategy for the controlled system with external disturbance. However, the proposed approaches in [Citation20–32] ignored the external disturbance in the controller system.
It is a prominent prospect to eliminate the influence of external disturbances on the systems [Citation33–38]. Ji et al. [Citation39] designed an adaptive fault-tolerant optimized formation control for multiagent systems with disturbances, in which a disturbance observer was constructed to alleviate the negative effects of external disturbance. Liu et al. [Citation40] developed an adaptive control scheme for Markovian jump systems that suffer from external disturbances and actuator faults, in which external disturbances contain matched and mismatched part. Xu et al. [Citation41] designed a neural network disturbance observer for strict-feedback systems to achieve good control performance in spite of unknown dynamics and time-varying disturbance. Song and Lewis [Citation42] introduced a robust optimal control scheme with a disturbance observer to estimate disturbances for nonlinear systems. Zerari and Chemachema [Citation43] studied the continuously stirred tank reactor systems containing external disturbances and introduced the compensator to confront the influence of external interference in the designed control strategy. Ran et al. [Citation44] proposed a disturbance rejection optimal control for nonlinear systems, in which the perturbances and other uncertainties are estimated by the designed disturbance observer. Chen and Ge [Citation45] presented an adaptive neural control strategy for nonlinear systems with unmeasured states, hysteresis and disturbances. However, the foregoing advancements rarely studied the optimized finite-time control problem based on fuzzy systems for nonlinear systems with full-state constraints and external disturbances.
Motivated by the aforementioned researches, this paper considers the fuzzy adaptive optimal finite-time control issue for nonlinear systems with full-state constraints, external disturbance and bias fault. Combining backstepping and ADP tricks, a fuzzy adaptive optimal finite-time control strategy is designed. The unknown system functions are approximated by the fuzzy logic system and disturbance observers are designed to solve the influence of external disturbances and bias fault signal. Virtual and actual controllers are introduced by being incorporated with actor-critic architecture and backstepping framework. The main contributions are summarized as follows.
In comparison with [Citation25,Citation27,Citation28], the designed scheme via actor-critic framework and finite-time stability theory can ensure the controller systems not only has a faster convergence rate and limits the tracking error derives within a temperate area of the origin in a finite time.
An disturbance observer-based fuzzy finite-time strategy based on actor-critic structure is proposed. Discriminating the control schemes in [Citation26,Citation32,Citation46], it not only considers the full-state constraint for strict-feedback nonlinear systems but also addresses the effects of bias fault and external disturbance on the system by designing the disturbance observer.
The remainder of this article is organized as follows. In Section 2, the system description and preliminary knowledge are presented. Section 3 proposes an observer-based fuzzy optimal control scheme. Subsequently, stability analysis is given in Section 4. A simulation example is shown in Section 5. Finally, the conclusion is presented in Section 6.
2. Preliminaries and problem statement
2.1. System description
The strict-feedback nonlinear system consisting of unknown dynamics is formulated by
(1)
(1) where
(
) represent the states vector of the system,
is the control output.
(
)
are the unknown functions and
denote the external disturbances where
. All system states are restricted to a compact set, that is,
where
are positive constants with
.
In actual engineering applications, the actuator bias faults often occur during the operation of the actuator. Thus we consider the actuator bias fault signal as
(2)
(2) where u denotes the control input and
represents the actuator bias fault signal. Suppose
is bounded and there is a constant F that
.
Assumption 2.1
[Citation39]
The external disturbances are unknown and bounded, i.e. there exist real numbers
and
satisfying
and
where
.
Assumption 2.2
[Citation25]
The reference trajectory is known and bounded, and the derivatives of the
,
are bounded.
2.2. Finite-time theory
The following lemmas are beneficial to facilitate the design of the controller.
Lemma 2.1
[Citation15]
For any positive numbers ,
, 0<l<1, there exist a
function
satisfying
(3)
(3) then the system is finite-time stable, where the setting time
.
Lemma 2.2
[Citation29]
For any , there exist an integer constant ξ and a positive constant
, one has
(4)
(4)
Lemma 2.3
[Citation29]
There exists real variables and
satisfying the following inequality:
(5)
(5) where
,
and
are positive constants.
2.3. Fuzzy logic system
A host of real-world systems exit unknown dynamics which affect the control performance, and fuzzy logic system approximation approach facilitates to solve the negative effect problem of unknown dynamics. The knowledge base constitutes IF–THEN rules which are stated in the following forms:
where
and y are the input and output of fuzzy logic system.
and
represent fuzzy sets, and N denotes the number of rules. Then the fuzzy logic system can be described by
(6)
(6) where
and
are fuzzy membership functions, and
.
The basis functions are defined as
(7)
(7) Denote
, and
, and (Equation6
(6)
(6) ) can be stated as follows:
(8)
(8)
Lemma 2.4
[Citation24]
Let be a continuous function defined on compact set ℘. There exists a positive constant φ that satisfies the following inequality:
(9)
(9)
By means of (Equation9(9)
(9) ), the following fuzzy logic systems are served to approximate the functions
(
):
(10)
(10) where
represents the approximation of
and
denotes the estimations of
. The ideal weight vectors
can be described as
(11)
(11) where
is a bounded set.
The control objective of this article is to design a disturbance observer-based fuzzy adaptive optimal finite-time control scheme for nonlinear systems (Equation1(1)
(1) ), so that (1) all the signals in systems are finite time stable; (2) all the system states are in constrained sets; (3) the output of systems admits to track the reference trajectory.
3. Optimal controller design
In what follows, a fuzzy adaptive optimal finite-time strategy is designed to achieve the control objective by virtue of backstepping process and actor-critic framework, in which the barrier-type function is accustomed to cost functions. Consider the bias function in (Equation2
(2)
(2) ) and external disturbance
as whole disturbance. The nonlinear systems (Equation1
(1)
(1) ) can be expressed as
(12)
(12) where
and
.
Remark 3.1
Extensive practical systems contain perturbation items, which have a negative effect for control quality. Different from the strategies proposed in [Citation40,Citation47], this paper employs disturbance observer to track external disturbances online to mitigate the negative effects on the systems and improve the control performance of the systems. The term is bounded and
, the external disturbance
, and we deduce
. Thus the total disturbance
is bounded.
Then the following coordinate transformation is introduced as (13)
(13) where
is the optimal virtual control and
is the desire tracking trajectory.
Step 1: The time derivative of can be yielded from (Equation1
(1)
(1) ) and (Equation13
(13)
(13) ) as
(14)
(14) Choose the infinite integral barrier-type performance index function that satisfies (Equation1
(1)
(1) ) as
(15)
(15) where
is the cost function where
0,
is the virtual controller and a compact set
. Let
be the optimal virtual control. The optimal performance index function is constructed by the following to achieve the minimum control performance index in (Equation15
(15)
(15) ),
(16)
(16) Taking the time derivative of (Equation16
(16)
(16) ), we acquire
(17)
(17) Define HJB equation associating with (Equation17
(17)
(17) ) as
(18)
(18) By solving the equation
, the optimal virtual controller is obtained as
(19)
(19) With the aim of realizing finite-time optimal control,
is decomposed as
(20)
(20) where
and
are designed positive parameters, and
is the optimal weight.
. Merging (Equation19
(19)
(19) ) and (Equation20
(20)
(20) ), we verify
(21)
(21) In (Equation21
(21)
(21) ),
and
are unknown functions that can be approximated as
(22)
(22)
(23)
(23) where
is the ideal weight and
is the basis vector. Combining (Equation20
(20)
(20) ), (Equation21
(21)
(21) ), (Equation22
(22)
(22) ) and (Equation23
(23)
(23) ), we get
(24)
(24)
(25)
(25) where
. It is noteworthy that
is inaccessible directly since
and
are unknown ideal weights. The estimate of the unknown function
can be represented as
. The adaptive law
is constructed as
(26)
(26) where
0. To obtain available
, the critic-actor structure with the critic and actor adaptive laws is introduced as follows:
(27)
(27) where
is the estimation of
. Design the critic updated law as
(28)
(28) where
0. The virtual controller consists of actor adaptive law
(29)
(29) Correspondingly, the actor updated law is designed by
(30)
(30) where
0. By substituting (Equation29
(29)
(29) ) and (Equation27
(27)
(27) ) into (Equation18
(18)
(18) ), we obtain
The Bellman residual error
is expressed as
(31)
(31) It is emphasized that the optimal virtual controller
is constructed to guarantee
. If
has a unique solution, then one obtains
(32)
(32) Construct a positive function
(33)
(33) It is obvious that
which is equal to (Equation32
(32)
(32) ). The actor and critic adaptive laws can be designed in view of the following relation:
(34)
(34) Thus we have
(35)
(35)
Therefore, (Equation28
(28)
(28) ) and (Equation30
(30)
(30) ) enable (Equation32
(32)
(32) ) to be finally realized. The disturbance observer is designed as
(36)
(36) where
0. Define the Lyapunov function as follows:
(37)
(37) where
. In view of (Equation13
(13)
(13) ), (Equation28
(28)
(28) ) and (Equation30
(30)
(30) ), the time derivative of
is
(38)
(38) The following correlations hold by utilizing the Young's inequality
(39)
(39)
(40)
(40)
(41)
(41)
(42)
(42)
(43)
(43) From (Equation39
(39)
(39) )–(Equation43
(43)
(43) ), we yield
(44)
(44) In light of
,
and
, we get
(45)
(45)
(46)
(46)
(47)
(47)
(48)
(48) Substituting (Equation45
(45)
(45) )–(Equation48
(48)
(48) ) into (Equation44
(44)
(44) ), we confirm
(49)
(49) where
/2,
and
by reason of
. Let
and
be the minimal eigenvalue of
and
, respectively. The following inequalities hold:
(50)
(50)
(51)
(51)
(52)
(52)
(53)
(53)
(54)
(54) Substituting (Equation50
(50)
(50) )–(Equation54
(54)
(54) ) into (Equation49
(49)
(49) ), we deduce
(55)
(55) where
and
.
Step : The time derivative
can be derived from (Equation12
(12)
(12) ) and (Equation13
(13)
(13) ) as
(56)
(56) Introduce the performance index function as
(57)
(57) where
represents the cost function and
denotes the virtual controller. Let
be the optimal virtual controller. Similar to (Equation16
(16)
(16) ), to achieve the minimum control performance index in (Equation57
(57)
(57) ), the optimal performance index function is established as follows:
(58)
(58) Taking the time derivative of (Equation58
(58)
(58) ), we deduce
(59)
(59) Define HJB equation associating with (Equation59
(59)
(59) ) as follows:
(60)
(60) Solve the equation
/
, the optimal virtual controller is determined by
(61)
(61) For the purpose of the optimal control,
can be decomposed as
(62)
(62) where
,
0 and
. Thus (Equation61
(61)
(61) ) can be represented as
(63)
(63) In (Equation63
(63)
(63) ),
and
are approximated by fuzzy logic systems as
(64)
(64)
(65)
(65) The following equations are established in light of combining (Equation64
(64)
(64) ) and (Equation65
(65)
(65) ) with (Equation62
(62)
(62) ) and (Equation63
(63)
(63) ) respectively,
(66)
(66)
(67)
(67) where
. It is noticeable that
is unavailable because
and
are the unknown ideal weights. Resembling (Equation27
(27)
(27) ) and (Equation29
(29)
(29) ), the actor-critic structure is developed as
(68)
(68) Design the critic updated law, optimal virtual control law and actor updated law as
(69)
(69)
(70)
(70)
(71)
(71) where
and
are positive numbers. The fuzzy updated law is constructed as
(72)
(72) where
is a positive constant. By lumping (Equation68
(68)
(68) ), (Equation70
(70)
(70) ) and (Equation72
(72)
(72) ) into (Equation60
(60)
(60) ), we acquire
(73)
(73) The disturbance observer is devised as
(74)
(74) Construct the Lyapunov function as
(75)
(75) where
and
. By combining (Equation13
(13)
(13) ), (Equation69
(69)
(69) ) and (Equation71
(71)
(71) ), the time derivative of (Equation75
(75)
(75) ) yields
(76)
(76) The following relationship can be deduced by utilizing the Young's inequality,
(77)
(77)
(78)
(78)
(79)
(79)
(80)
(80)
(81)
(81) Associate (Equation77
(77)
(77) )–(Equation81
(81)
(81) ) with (Equation76
(76)
(76) ), we can derive
(82)
(82) Due to
,
and
the following correlations are inferred:
(83)
(83)
(84)
(84)
(85)
(85)
(86)
(86)
(87)
(87) By lumping (Equation83
(83)
(83) )–(Equation87
(87)
(87) ) into (Equation76
(76)
(76) ), we get
(88)
(88) where
by virtue of
. Assuming that
represents the minimal eigenvalue of
, the following inequalities yields:
(89)
(89)
(90)
(90)
(91)
(91)
(92)
(92)
(93)
(93) Substituting (Equation92
(92)
(92) ) and (Equation93
(93)
(93) ) into (Equation88
(88)
(88) ), we obtain
(94)
(94) where
.
Step n: can be showcased from (Equation12
(12)
(12) ) and (Equation13
(13)
(13) ) as
(95)
(95)
The time derivative of (Equation95
(95)
(95) ) is stated by
(96)
(96) Define the integral performance index function as
(97)
(97) where
. Let
be the optimal actual controller, then the optimal performance index function is represented by
(98)
(98) Akin to (Equation20
(20)
(20) ), we have
(99)
(99) By associating with (Equation95
(95)
(95) ), the HJB equation is formalized by
(100)
(100) Similar to (Equation61
(61)
(61) ), dealing with the (
) = 0, we yield
(101)
(101) Let
, where
0. The optimal actual controller can be stated by
(102)
(102)
and
can be approximated by the fuzzy logic system as
(103)
(103)
(104)
(104) Merging (Equation103
(103)
(103) ), (Equation104
(104)
(104) ) and (Equation102
(102)
(102) ), we yield
(105)
(105) where
Combining with (Equation103
(103)
(103) ),
can be formulated by
(106)
(106) The critic for evaluating (Equation106
(106)
(106) ) and critic updated law is conceived as
(107)
(107)
(108)
(108) The law of the actor and the actual controller are constructed as
(109)
(109)
(110)
(110) The adaptive law
is updated as
(111)
(111) where
is a positive constant. The HJB equation is derived as
(112)
(112) The disturbance observer is built as
(113)
(113) The Lyapunov function is selected as follows:
(114)
(114) Merging with (Equation108
(108)
(108) ), (Equation110
(110)
(110) ), (Equation113
(113)
(113) ) and (Equation95
(95)
(95) ), the time derivative of (Equation114
(114)
(114) ) is determined by
(115)
(115) By Young's inequality, we acquire
(116)
(116)
(117)
(117)
(118)
(118)
(119)
(119) Integrate (Equation116
(116)
(116) )–(Equation119
(119)
(119) ) into (Equation115
(115)
(115) ), we have
(120)
(120) From
,
and
, we get the following relations:
(121)
(121)
(122)
(122)
(123)
(123)
(124)
(124) Invoking (Equation121
(121)
(121) )–(Equation124
(124)
(124) ) and (Equation94
(94)
(94) ) for (Equation115
(115)
(115) ), we infer
(125)
(125) where
. Suppose that
represents the minimal eigenvalue of
, the following inequalities yield:
(126)
(126)
(127)
(127)
(128)
(128)
(129)
(129)
(130)
(130) Substituting (Equation129
(129)
(129) ), (Equation130
(130)
(130) ) and similar to (Equation94
(94)
(94) ), we obtain the following inequality:
(131)
(131) where
.
4. Stability analysis
In this section, the stability of the system is demonstrated.
Theorem 4.1
Consider the nonlinear system (Equation1(1)
(1) ) with actuator bias fault signal and external disturbances. Suppose that Assumptions 2.1 and 2.2 hold. Taking into account the designed critic adaptive laws as (Equation28
(28)
(28) ), (Equation69
(69)
(69) ) and (Equation108
(108)
(108) ), actor updated laws as (Equation30
(30)
(30) ), (Equation71
(71)
(71) ) and (Equation110
(110)
(110) ), fuzzy adaptive laws (Equation26
(26)
(26) ), (Equation72
(72)
(72) ) and (Equation111
(111)
(111) ), and disturbance observers (Equation36
(36)
(36) ), (Equation74
(74)
(74) ) and (Equation113
(113)
(113) ). The proposed fuzzy adaptive optimal finite-time control scheme ensures that (1) all signals within the closed-loop system are bounded; (2) all states are in their specific intervals.
Proof.
Let , on the basis of (Equation131
(131)
(131) ), we have
(132)
(132) Let
,
,
,
,
and
. From (Equation132
(132)
(132) ), we acquire
(133)
(133) In light of (Equation4
(4)
(4) ), define
,
,
,
, one has
(134)
(134) In view of the same fashion as (Equation134
(134)
(134) ), it leads to
(135)
(135)
(136)
(136)
(137)
(137) It follows from (Equation5
(5)
(5) ) that
(138)
(138) According to (Equation135
(135)
(135) )–(Equation138
(138)
(138) ), (Equation133
(133)
(133) ) can be rewritten as
(139)
(139) Define
and
. It is worth noting that
(
) in constraint sets, we can get
, rewrite (Equation139
(139)
(139) ) as
(140)
(140) where
. In light of (Equation140
(140)
(140) ), we know that
, therefore, it is easy to obtain V is bounded. The similarity follows that
,
and
are bounded. Therefore,
,
and
are bounded. From previous analysis, we get
, it can be further deducted by Assumption 2.2 that
, where
is the upper bounded of
.
is also bounded and
, and we can derive that
. In the same way, it is true that
, where
. Thus all system states are confined within constraint sets.
Setting , where 0<l<1. We can deduce that
, thus
(141)
(141) It follows from (Equation141
(141)
(141) ) that
(142)
(142) which means that the tracking error remains within the origin of the area after the setting time.
Remark 4.1
The adaptive optimal control schemes described in [Citation26,Citation28,Citation32] ensure that all signals are semi-globally uniformly ultimately bounded with , the convergence time may be infinite. The strategy proposed in this paper, the time derivative of V satisfies
, which means that it can achieve the faster response.
Remark 4.2
It is worth noting that the tracking error is remained within the origin of the area after the setting time by choosing appropriate parameters. Reduce the area of origin by adjusting the value of δ or increasing . Therefore, the parameters should be chosen carefully.
5. Simulation example
This section aims to verify the effectiveness of the proposed fuzzy control method with a simulation instance.
Example 5.1
A model with external disturbances and bias fault signal is presented below
(143)
(143) where
,
, the output reference trajectory is defined as
, and
(144)
(144) where
. The chosen membership functions are referred to
(145)
(145) Thus the basis function vector
is denoted as
(146)
(146) Analogously, the basis function vectors
,
and
are formulated as
The initial values are configured as
,
,
,
,
, and
.
The parameters in adaptive laws, optimal virtual controller and optimal actual controller are designed as and
.
Figure manifests the trajectories of y, and constraint bound
, which shows the control performance and the system state staying within the restricted interval. Figure represents the trajectories of tracking error
and
, showing that the tracking error is maintained in a small neighbourhood of about 0. Figure shows the trajectories of
and
and the state
remains within the blue dashed line. Figures display the curves of
,
and
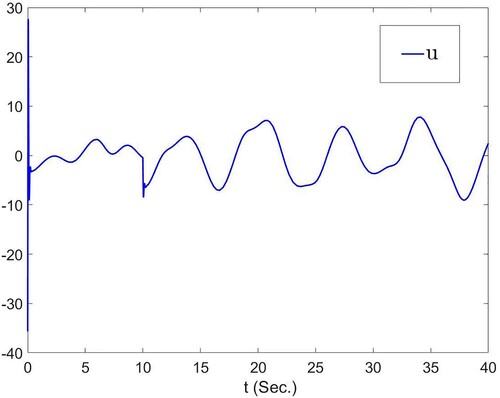
where i = 1, 2, and the curves from these figures are decreasing. Figure showcases the trajectory of optimal actual controller u. From the simulation results, the proposed scheme in this paper can achieve the desired control objective.
Figure 1. The trajectories of y, and
.
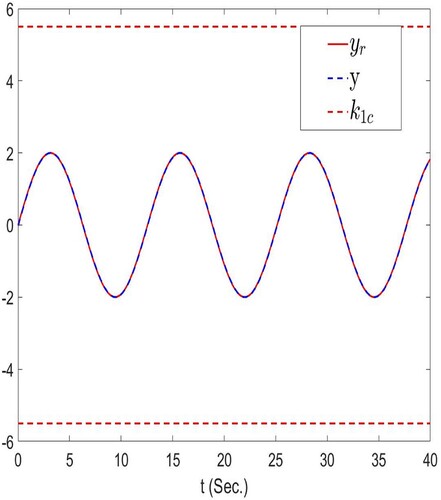
Figure 2. The trajectories of and
.
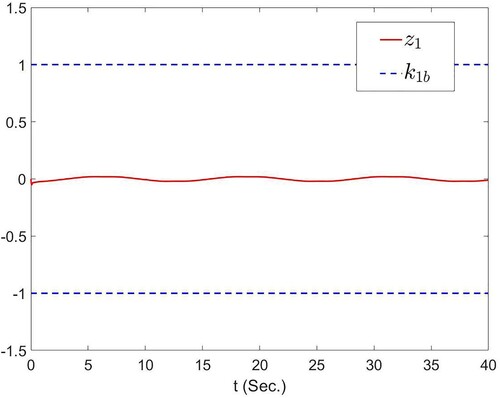
Figure 3. The trajectories of and
.
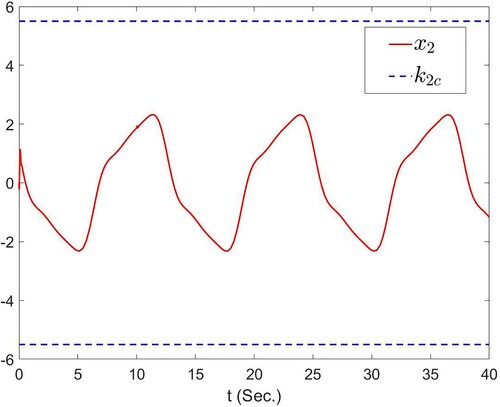
Figure 4. The curves of and
.
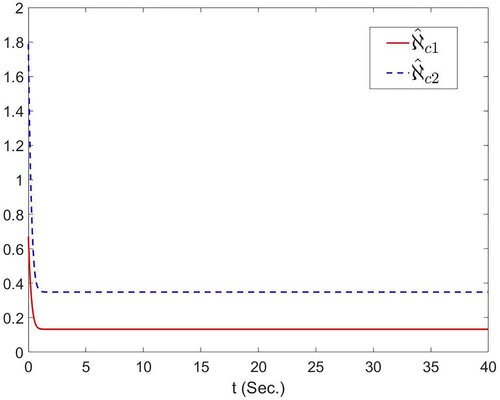
Figure 5. The curves of and
.
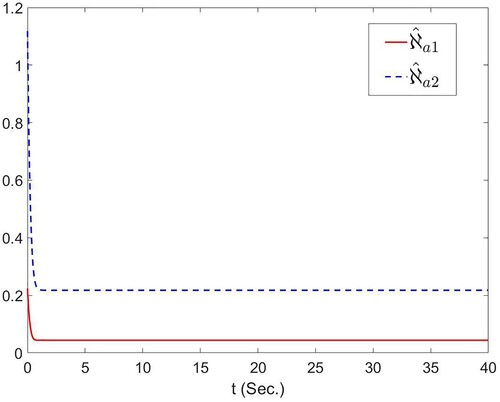
Figure 6. The curves of and
.
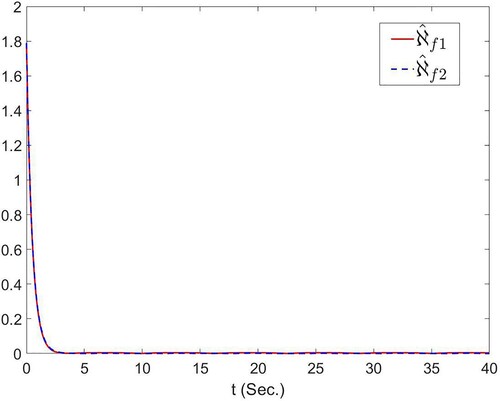
Figure 7. The trajectory of u.
Example 5.2
Similar to [Citation9] and [Citation48], this paper considers the robotic manipulator system as follows:
(147)
(147) where S and
are the angle and angular velocity of the link, respectively, M is the total mass of the link, J is the rotational inertia of the motor, G is the gravitational acceleration, A is the damping coefficient. Assuming the effect of external disturbance and bias fault on the system is taken into account, (Equation147
(147)
(147) ) is rewritten as
(148)
(148) The parameter selection in (Equation148
(148)
(148) ) is similar to that in [Citation48], that is,
. Let
,
thus the system (Equation147
(147)
(147) ) can be rewritten as
(149)
(149) where
,
, the reference signal
. The fuzzy logic system we used and bias fault signal are the same as in Example 5.1. The parameters used in the control strategy are designed as
and
. The reference trajectory
and external disturbance
are defined as
and
. The initial values are configured as
,
,
,
,
, and
.
Figures are the simulation results of the robotic manipulator system. Figure demonstrates the trajectories of y, and
, showing satisfactory control performance. As shown in Figure , the tracking error
represented by the red solid line does not exceed the blue dashed line
and remains within a small neighbourhood relating to the origin. The trajectory of
, which does not cross the blue dashed line
, is shown in Figure . Figures display the curves of
,
and
where i = 1, 2. Figure shows the trajectory of optimal actual controller u.
Figure 8. The trajectories of y, and
.
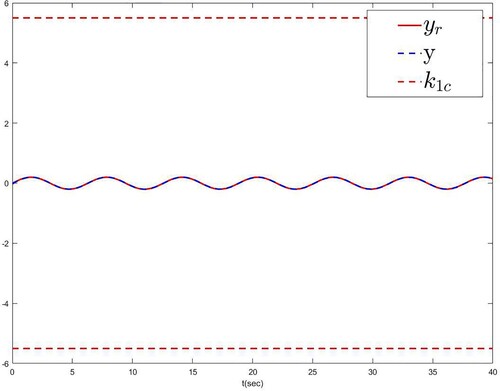
Figure 9. The trajectories of and
.
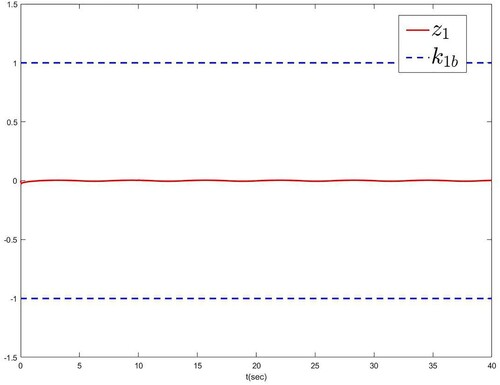
Figure 10. The trajectories of and
.
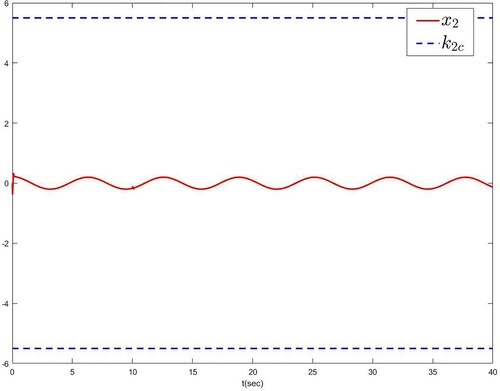
Figure 11. The curves of and
.
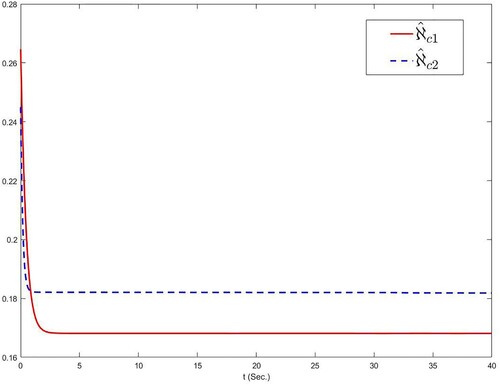
Figure 12. The curves of and
.
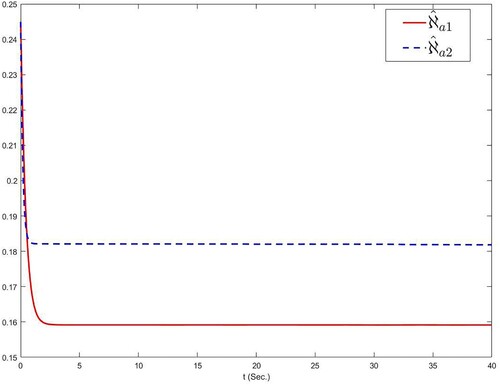
Figure 13. The curves of and
.
Figure 14. The trajectory of u.
6. Conclusion
In this article, the issue of adaptive fuzzy optimal finite-time control for uncertain nonlinear systems with bias fault and external disturbances is studied. Consider bias fault term and external disturbance as total disturbance, the disturbance observer is designed to track the total disturbance online, where the total disturbance consists of bias fault term and external disturbance. By combining with backstepping and ADP technologies, an adaptive fuzzy optimal finite-time control approach is proposed. It proves that all signals of closed-loop are finite-time stable, and the all system states in constrained sets. One future research direction is to extend the proposed method to more general systems such as stochastic systems [Citation49], switched nonlinear systems [Citation50,Citation51] and uncertain under-actuated switched nonlinear systems [Citation52]. In addition, it is another research direction to study unknown nonaffine nonlinear fault problems and unmodelled dynamics problems based on fixed time control [Citation53–55].
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Acknowledgments
The authors thank the reviewers for their constructive comments in improving the quality of this paper. Zhidong Sun wrote the manuscript, Wei Gao and Li Liang revised and made improvements on the manuscript. The authors have worked equally when writing this paper. All authors read and approved the final manuscript.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
Some or all data, models, or code generated or used during the study are available from the corresponding author by request.
Additional information
Funding
References
- Ma ZY, Ma HJ. Adaptive fuzzy backstepping dynamic surface control of strict-feedback fractional-order uncertain nonlinear systems. IEEE Trans Fuzzy Sys. 2020;28:122–133.
- Liang YJ, Li YX, Che WW, et al. Adaptive fuzzy asymptotic tracking for nonlinear systems with nonstrict-feedback structure. IEEE Trans Cybern. 2021;51:853–861.
- Ma H, Liang HJ, Zhou Q, et al. Adaptive dynamic surface control design for uncertain nonlinear strict-feedback systems with unknown control direction and disturbances. IEEE Trans Syst Man Cybern Syst. 2019;49:506–515.
- Wang HQ, Liu XP, Liu KF, et al. Approximation-based adaptive fuzzy tracking control for a class of nonstrict-feedback stochastic nonlinear time-delay systems. IEEE Trans Fuzzy Sys. 2015;23:1746–1760.
- Lai GY, Liu Z, Chen CLP, et al. Adaptive compensation for infinite number of time-varying actuator failures in fuzzy tracking control of uncertain nonlinear systems. IEEE Trans Fuzzy Sys. 2018;26:474–486.
- Zou AM, Hou ZG, Tan M. Adaptive control of a class of nonlinear pure-feedback systems using fuzzy backstepping approach. IEEE Trans Fuzzy Sys. 2008;16:886–897.
- Zhang HC, Song AG, Li HJ, et al. Novel adaptive finite-time control of teleoperation system with time-varying delays and input saturation. IEEE Trans Cybern. 2021;51:3724–3737.
- Bhat SP, Bernstein DS. Continuous finite-time stabilization of the translational and rotational double integrators. IEEE Trans Automat Contr. 1998;43:678–682.
- Qiu JB, Wang T, Sun KK, et al. Disturbance observer-based adaptive fuzzy control for strict-feedback nonlinear systems with finite-time prescribed performance. IEEE Trans Fuzzy Sys. 2022;30:1175–1184.
- Li Y, Qu F, Tong S. Observer-based fuzzy adaptive finite-time containment control of nonlinear multiagent systems with input delay. IEEE Trans Cybern. 2021;51:126–137.
- Zhang HG, Liu Y, Wang YC. Observer-based finite-time adaptive fuzzy control for nontriangular nonlinear systems with full-state constraints. IEEE Trans Cybern. 2021;51:1110–1120.
- Meng B, Liu WH, Qi XJ. Disturbance and state observer-based adaptive finite-time control for quantized nonlinear systems with unknown control directions. J Franklin Inst. 2022;359:2906–2931.
- Sui S, Chen CLP, Tong SC. Event-trigger-based finite-time fuzzy adaptive control for stochastic nonlinear system with unmodeled dynamics. IEEE Trans Fuzzy Sys. 2021;29:1914–1926.
- Saravanakumar R, Stojanovic SB, Radosavljevic DD, et al. Finite-time passivity-based stability criteria for delayed discrete-time neural networks via new weighted summation inequalities. IEEE Trans Neural Netw Learn Syst. 2019;30:58–71.
- Xia JW, Zhang J, Sun W, et al. Finite-time adaptive fuzzy control for nonlinear systems with full state constraints. IEEE Trans Syst Man Cybern. 2019;49:1541–1548.
- Wang YD, Zong GD, Yang D, et al. Finite-time adaptive tracking control for a class of nonstrict feedback nonlinear systems with full state constraints. Int J Robust Nonlinear Control. 2022;32:2551–2569.
- Zhao L, Liu GQ, Yu JP. Finite-time adaptive fuzzy tracking control for a class of nonlinear systems with full-state constraints. IEEE Trans Fuzzy Sys. 2021;29:2246–2255.
- Nguyen VT, Lin CY, Su SF, Sun W. Finite-time adaptive fuzzy tracking control design for parallel manipulators with unbounded uncertainties. Int J Fuzzy Syst. 2019;21:545–555.
- Wang LB, Wang HQ, Liu XP. Adaptive fuzzy finite-time control of stochastic nonlinear systems with actuator faults. Nonlinear Dyn. 2021;104:523–536.
- Bellman RE, Corporation R. Dynamic programming. Princeton (NJ): Princeton University Press; 1957.
- Werbos PJ. Approximate dynamic programming for real-Time control and neural modeling. Handb Intell Control Neural Fuzzy & Adapt Approaches. 1992;15:493–525.
- Abu-Khalaf M, Lewis FL. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica. 2005;41(5):779–791.
- Vamvoudakis KG, Lewis FL. Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica. 2010;46(5):878–888.
- Wen GX, Chen CLP, Feng J, et al. Optimized multi-agent formation control based on an identifier–actor–critic reinforcement learning algorithm. IEEE Trans Fuzzy Sys. 2018;26:2719–2731.
- Li KW, Li YM. Fuzzy adaptive optimal consensus fault-tolerant control for stochastic nonlinear multiagent systems. IEEE Trans Fuzzy Sys. 2022;30:2870–2885.
- Wen GX, Li B, Niu B. Optimized backstepping control using reinforcement learning of observer-critic-actor architecture based on fuzzy system for a class of nonlinear strict-feedback systems. IEEE Trans Fuzzy Sys. 2022;30:4322–4335.
- Lan J, Liu YJ, Yu DX, et al. Time-varying optimal formation control for second-order multiagent systems based on neural network observer and reinforcement learning. IEEE Trans Neural Netw Learn Syst. 2022. DOI:10.1109/TNNLS.2022.3158085
- Li YM, Liu YJ, Tong SC. Observer-based neuro-adaptive optimized control of strict-feedback nonlinear systems with state constraints. IEEE Trans Neural Netw Learn Syst. 2022;33:3131–3145.
- Bhasin S, Kamalapurkar R, Johnson M, et al. A novel actor–critic-identifier architecture for approximate optimal control of uncertain nonlinear systems. Automatica. 2013;49:82–92.
- Vamvoudakis KG, Miranda MF, Hespanha JP. Asymptotically stable adaptive-optimal control algorithm with saturating actuators and relaxed persistence of excitation. IEEE Trans Neural Netw Learn Syst. 2016;27:2386–2398.
- Zargarzadeh H, Dierks T, Jagannathan S. Optimal control of nonlinear continuous-time systems in strict-feedback form. IEEE Trans Neural Netw Learn Syst. 2015;26:2535–2549.
- Wen GX, Chen CLP, Ge SS. Simplified optimized backstepping control for a class of nonlinear strict-feedback systems with unknown dynamic functions. IEEE Trans Cybern. 2021;51:4567–4580.
- Zerari N, Chemachema M. Event-triggered adaptive output-feedback neural-networks control for saturated strict-feedback nonlinear systems in the presence of external disturbance. Nonlinear Dyn. 2021;104:1343–1362.
- Li HY, Zhao SY, He W, et al. Adaptive finite-time tracking control of full state constrained nonlinear systems with dead-zone. Automatica. 2019;100:99–107.
- Liu YC, Zhu QD, Wen GX. Adaptive tracking control for perturbed strict-feedback nonlinear systems based on optimized backstepping technique. IEEE Trans Neural Netw Learn. 2022;33:853–865.
- Sariyildiz E, Ohnishi K. On the explicit robust force control via disturbance observer. IEEE Trans Ind Electron. 2015;62:1581–1589.
- Tong SC, Li YM, Liu YJ. Observer-based adaptive neural networks control for large-scale interconnected systems with nonconstant control gains. IEEE Trans Neural Netw Learn Syst. 2021;32:1575–1585.
- Sun HB, Guo L. Neural network-based DOBC for a class of nonlinear systems with unmatched disturbances. IEEE Trans Neural Netw Learn Syst. 2017;28:482–489.
- Ji WY, Pan YN, Zhao M. Adaptive fault-tolerant optimized formation control for perturbed nonlinear multiagent systems. Int J Robust Nonlinear Control. 2022;32:3386–3407.
- Liu M, Ho DWC, Shi P. Adaptive fault-tolerant compensation control for Markovian jump systems with mismatched external disturbance. Automatica. 2015;58:5–14.
- Xu B, Shou YX, Luo J, et al. Neural learning control of strict-feedback systems using disturbance observer. IEEE Trans Neural Netw Learn. 2018;30:1296–1307.
- Song RZ, Lewis FL. Robust optimal control for a class of nonlinear systems with unknown disturbances based on disturbance observer and policy iteration. Neurocomputing. 2020;390:185–195.
- Zerari N, Chemachema M. Robust adaptive neural network prescribed performance control for uncertain CSTR system with input nonlinearities and external disturbance. Neural Comput Appl. 2020;32:10541–10554.
- Ran MP, Li JC, Xie LH. Reinforcement-learning-based disturbance rejection control for uncertain nonlinear systems. IEEE Trans Cybern. 2022;52:9621–9633.
- Chen M, Ge SS. Adaptive neural output feedback control of uncertain nonlinear systems with unknown hysteresis using disturbance observer. IEEE Trans Ind Electron. 2015;62:7706–7716.
- Li KW, Li YM. Adaptive NN optimal consensus fault-tolerant control for stochastic nonlinear multiagent systems. IEEE Trans Neural Netw Learn. 2023. 34(2):947–957. doi:10.1109/TNNLS.2021.3104839.
- Li HY, Wu Y, Chen M. Adaptive fault-tolerant tracking control for discrete-time multiagent systems via reinforcement learning algorithm. IEEE Trans Cybern. 2021;51:1163–1174.
- Xing LT, Wen CY, Liu ZT, et al. Adaptive compensation for actuator failures with event-triggered input. Automatica. 2017;85:129–136.
- Li YL, Liu B, Zong GD, et al. Command filter-based adaptive neural finite-time control for stochastic nonlinear systems with time-varying full state constraints and asymmetric input saturation. Int J Syst Sci. 2022;53:199–221.
- Zhang HY, Wang HQ, Niu B, et al. Sliding-mode surface-based adaptive actor-critic optimal control for switched nonlinear systems with average dwell time. Inf Sci. 2021;580:756–774.
- Wang HQ, Tong M, Zhao XD, et al. Predefined-time adaptive neural tracking control of switched nonlinear systems. IEEE Trans Cybern. 2022. DOI:10.1109/TCYB.2022.3204275
- Zhang HY, Zhao XD, Zhang L, et al. Observer-based adaptive fuzzy hierarchical sliding mode control of uncertain under-actuated switched nonlinear systems with input quantization. Int J Robust Nonlinear Control. 2022;32:8163–8185.
- Li YM, Sun KK, Tong SC. Observer-based adaptive fuzzy fault-tolerant optimal control for SISO nonlinear systems. IEEE Trans Cybern. 2019;49:649–661.
- Wang HQ, Xu K, Zhang HG. Adaptive finite-time tracking control of nonlinear systems with dynamics uncertainties. IEEE Trans Automat Contr. 2022. DOI:10.1109/TAC.2022.3226703
- Ma JW, Wang HQ, Qiao JF. Adaptive neural fixed-time tracking control for high-order nonlinear systems. IEEE Trans Neural Netw Learn. 2022. DOI:10.1109/TNNLS.2022.3176625