Abstract
The present study aimed to predict conformation and fatness grades in bulls based on data available at slaughter (carcass weight, age and breed proportions) by means of counter-propagation artificial neural networks (ANN). For chemometric analysis, 5893 bull carcasses (n=2948 and n=2945 for calibration and testing of models, respectively) were randomly selected from the initial data set (n≈27000; one abattoir, one classifier, three years period). Different ANN models were developed for conformation and fatness by varying the net size and the number of epochs. Tested net parameters did not have a notable effect on models’ quality. Respecting the tolerance of ±1 subclass between the actual and predicted value (as allowed by European Union legislation for on-spot checks), the matching between the classifier and ANN grading was 73.6 and 64.9% for conformation and fatness, respectively. Success rate of prediction was positively related to the frequency of carcasses in the class.
Introduction
Learning ability of artificial neural networks (ANN), a special chemometric tool, was used to predict beef carcass grades based on relevant information (e.g. weight, age, proportion of breeds). If specifically further developed, this method could serve to foretell grading result prior to slaughter or, if properly calibrated, as a standalone grading method. To verify the latter, it would be necessary to use the approach foreseen by the legislation for the certification of automatic grading system.
In the EU, market transparency in beef sector is regulated through Community scales for the classification of beef carcasses (European Commission, Citation2007, Citation2008). The EU classification system is based on the appraisal of conformation and fatness which are visually assessed by trained classifiers. Conformation presents development of carcass profile, in particular the essential parts (round, back and shoulder), and it is graded into five main classes excellent (E), very good (U), good (R), fair (O) and poor (P). Class superior (S) is optional and refers to double-muscled carcasses. Fatness denotes the amount of fat on the outside of the carcass and in the thoracic cavity; here as well five main classes low (1), slight (2), average (3), high (4), and very high (5) are used. Further division into up to three subclasses is allowed (European Commission, Citation2006) and many EU member states implemented this option. Carcass grading is based on human judgement and it is therefore criticised as being subjective and inconsistent despite the assessment is performed by trained classifiers. Namely, a classifier can be influenced by other available information (cattle category, age, weight). It is also difficult to ensure uniform classification over time due to various factors like workload, fatigue, training, experience, working conditions, etc. Literature data on the accuracy of classifiers or factors affecting grading performance is lacking. It has been reported that the performance of the classifiers can be affected by carcass weight (Díez et al., Citation2003). Similarly, grading results (conformation and fatness) were shown to be affected by the abattoir (or classifier associated with it) and carcass weight (Prevolnik et al., Citation2011). European Union legislation allows automatic grading of beef carcasses using devices such as BCC-1 or BCC-2 (Carometec A/S, Herlev, Denmark), VBS 2000 (e+V Technology GmbH & Co.KG, Oranienburg, Germany), VIAscan® (Meat & Livestock, Sydney, Australia), etc., which are based on video image analysis (VIA; for review see Craigie et al., Citation2012). For the authorisation of such methods a certification test on 600 carcasses must be performed and accuracy criteria fulfilled. The present paper presents an alternative approach to predict carcass grades (conformation and fatness) using only the available data (weight, age and breed) and ANN. The idea originates from the practice where we often witness a situation in which buyers of cattle base their offer (price) to the farmer on in vivo visual assessment of the animal. We could consider that they use their brain neural networks for the analysis of image and prediction of grading result. Artificial neural networks, like people, learn by example meaning that their configuration is based on pattern recognition through a learning process. Because factors like weight, age, breed and rearing system influence grading result (Keane and Allen, Citation1998; Albertí et al., Citation2008; Prevolnik et al., Citation2011) we tried to test if and with what accuracy carcass grades could be predicted using ANN and the information available at slaughter (carcass weight, age and breed proportions).
Materials and methods
Data collection
Data for this study was provided by the official classification body. It concerned one abattoir, one category (bulls) and a period of three years (2008 to 2010). Information from the slaughter line (age at slaughter, warm carcass weight, conformation and fatness grades) was checked in cattle database at Agricultural Institute of Slovenia (Ljubljana, Slovenia) and combined with the information on origin (birth date, pedigree, breed proportions). Breed information was included in the data as the percentage of different breeds: Brown, Simmental, Holstein, Limousine, Charolais, Belgian Blue, Montbeliard, Slovenian Cika, American Brown, Hereford, Red Holstein and unknown origin. Percentage of individual breed ranged from 0 to 100% except for the percentage of unknown origin which could not exceed 25%. Animals with unknown origin (>25%) were removed. In order to minimize the effect of classifier one abattoir was chosen in which grading was performed by one operator only.
Chemometric tool
Chemometric analysis was performed using ANN software developed at the National Institute for Chemistry (Ljubljana, Slovenia), written in FORTRAN for IBM-compatible PCs and a Windows operating system. In the present study supervised counter-propagation ANN were applied. Although counter-propagation ANNs are comprehensively explained in the literature (Hecht-Nielsen, Citation1987; Dayhof, Citation1990; Zupan, Citation1994; Zupan et al., Citation1997), a brief description is given in the next paragraph.
The counter-propagation ANN are based on two-steps learning procedure. In the first (unsupervised) step the main goal is to project or map objects from m-dimensional into 2-dimensional space on the basis of input data (or similarity among objects). The map obtained shows only the relationship between the independent variables of the objects, regardless of their property that may be known, but is not represented in object vectors. The second step of the learning is supervised, which means that the response or target value is required. This input-target pairs are the input to the neural network, which, after being trained for a given number of epochs, is capable to predict the unknown samples. Every object excites one single neuron. The algorithm modifies the weight of the neuron with the weights the most similar to the input signal and smoothes the map by making modulated changes to neurons in a defined neighbourhood of that one. These corrections of weights are made around the neuron position in the Kohonen and output layer (Zupan, Citation1994).
Selection of datasets
Due to low frequency of carcasses in the extreme classes, a dataset for the chemometric analyses was constructed using random selection and stratification (survey select procedure of SAS 9.1; SAS Institute Inc., Cary, NC, USA). Stratification was performed to equalize number of carcasses in all the subclasses which represent 95% of the population and to have some representative carcasses in the bordering classes which were under represented. Resulting sample set (n=5893) was randomly divided into the training (n=2948) and test set (n=2945) which were used for the development and validation of models, respectively.
Construction and validation of models
Different ANN models were prepared separately for conformation and fatness varying the net size, i.e. the number of neurons in x and y direction (20×20, 30×30 and 40×40) and number of epochs (30, 50, 100, 150 and 200), whereas the other net parameters remained constant (no toroid boundary conditions, triangular type of neighbourhood correction, minimal and maximal learning rates of 0.01 and 0.5, respectively). Each sample was described with 14 descriptors (input variables), i.e. age at slaughter, carcass weight and proportions of breeds (n=12). The target variables (output) were conformation and fatness class with fifteen levels (P-, P, P+, O-, O, O+, R-, R, R+, U-, U, U+, E-, E, E+ for conformation; 1-, 1, 1+, 2-, 2, 2+, 3-, 3, 3+, 4-, 4, 4+, 5-, 5, 5+ for fatness) and were represented as a combination of fifteen discrete values (ones and zeros) for each level and sample. After the training, for each record (carcass), a combination of fifteen real numbers between 0.0 and 1.0 was obtained denoting the probability of the carcass to belong to a class. To convert this information into a prediction of class the real numbers had to be transformed back to discrete values (ones and zeros). When converting real values into discrete ones we did not focus on the probability of a certain class, but paid regard to the sum of probabilities to predict individual class and its closest neighbour(s). The class with the highest probability was denoted by value one (meaning that particular carcass belongs to the respective class), while other classes were given value zero (denoting that particular carcass does not belong to the respective class). The models were validated on the train and test samples through the rate of correctly classified samples. Perfect matching as well as the tolerance for ±1 class between actual and predicted class was considered as a correct result.
Results
Distribution of conformation and fatness
Distribution of carcasses in the selected population of bulls (n=27,551) according to conformation and fatness and the expected normal distribution is shown in . In the case of conformation, the majority of carcasses were concentrated (98%) in the middle classes O, R, U (≈20%, ≈50% and ≈30%, respectively). It can be noted that, compared to theoretical normal distribution, the subclasses R, O-, U- and U were over represented while subclasses P+, O+, R+, E-, E, E+ were under represented. In the case of fatness, over 95% of carcasses were classified in only two classes; 2 and 3. Related to normal distribution, the middle subclasses, 2 and 3, were over represented, while 2+ and 3- were under represented. After applying the stratified random selection, the distribution of carcasses according to conformation and fatness in training (n=2948) and test (n=2945) sets are presented in .
Agreement in grading of conformation and fatness between classifier and artificial neural networks
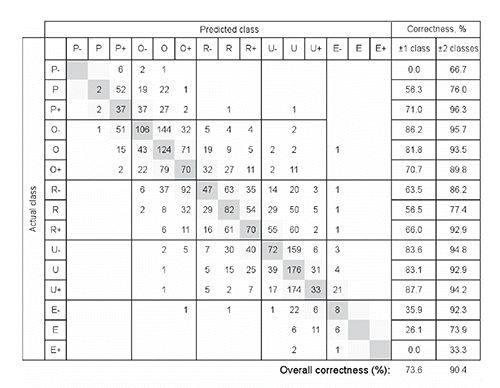
Altogether, 12 ANN prediction models were developed for each, conformation and fatness. In , training and validation results (classification performance) are presented as the percentage of carcasses for which the predicted class was consistent with classifiers’ grade (±1 subclass). For conformation the differences caused by the net size (number of neurons in x and y direction) were negligible. Small variability was also noticed when varying the number of epochs. In the case of conformation, the highest rate of agreement, obtained with net 40×40 and 50 or 100 epochs, averaged for all the subclasses of the test set was 73.5%. However, all the other models also provided very similar results (>70% of correctly classified test samples). Likewise, in the case of fatness, varying net size or number of epochs caused small differences in models’ performance. The highest rate of agreement between actual (classifier’s) and predicted fatness grade was obtained with 40×40 neurons and 30 epochs and amounted to 64.9%. Very similar results were obtained with other models (>60% of correctly classified test samples). Overall, presented models exhibited comparable performance and none of them could be marked as superior. Using information on bull’s weight, age and breed proportions, ANN was capable to agree with classifier in assessment of conformation (using allowed tolerance±1 class) in about three-quarters of cases. The success rate was a bit lower for fatness; two-thirds of carcasses were correctly classified with ANN which is about 10% lower than for conformation (evident on the training and test set). The most important information used by ANN in all the models comes from carcass weight. The information on age and breed improved the result in different models by 5-10% each.
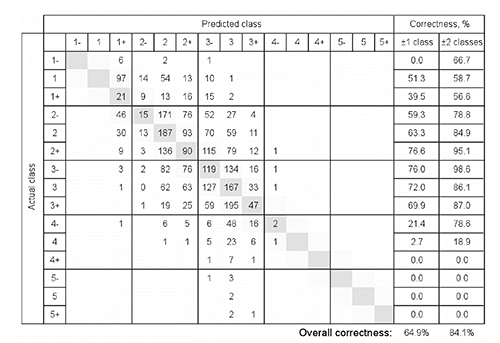
Substantial differences were observed in the success of prediction of the individual class; albeit different models produced rather similar results ( and ). For conformation, the models showed the best matching between ANN and classifier’s grade in the case of U subclasses (70 to 88%) and O subclasses (67 to 88%); matching was lower in R subclasses (57 to 71%). Equivalence between classifier and ANN prediction was lower in the case of the less frequent classes (e.g. class E) and particularly low for two extreme classes P- and E+. For fatness, lower classes with the exception of class 1- had good matching. For subclass 1- quite good matching can be observed in some models in the training, but not in validation which indicates over fitting of the models. Prediction proved much more problematic in the upper classes (4 and 5; <29%). The best matching between ANN and classifier’s grade was observed for subclasses of class 3 (61 to 76%) followed by subclasses of class 2 (57 to 77%). Rate of agreement (40 to 55%) was limited also for two subclasses of class 1 (1+, 1).
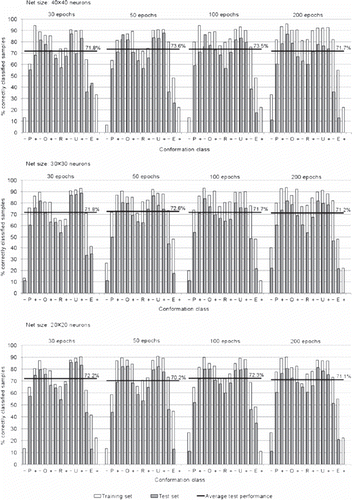
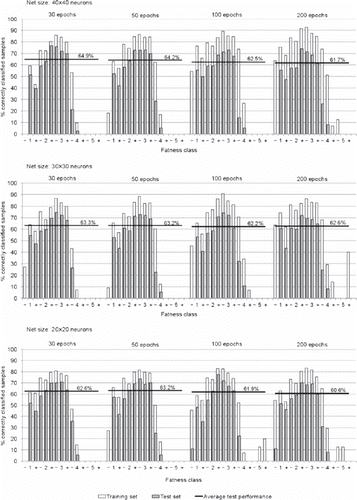
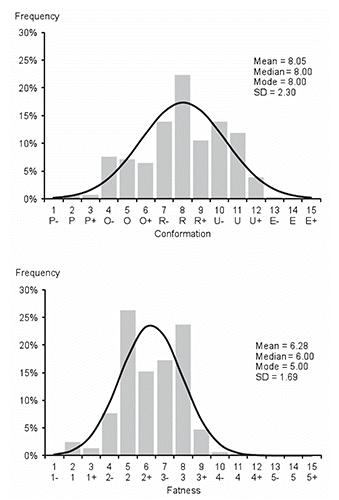
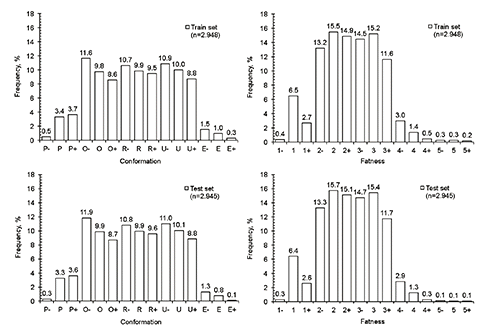
Table 1. Predictive ability of artificial neural networks models (% matching) for determining conformation and fatness class in the training and test set.
Misclassification tables
Misclassification tables for models with the best overall performance and the lowest difference between training and test results (for conformation 40×40 neurons, 50 epochs and for fatness 40×40 neurons, 30 epochs) are presented in and . Misclassification tables were obtained by comparing the actual and predicted classes of the validation data set. Carcasses, for which the predicted class was in agreement with classifier’s grade, are presented as the diagonal elements marked in gray, over classified (false positive) carcasses are situated in the upper triangle and under classified (false negative) carcasses in the lower triangle. Considering ±1 subclass as the correct prediction the rate of agreement was 73.6% for conformation and 64.9% for fatness. Misclassification tables showed no bias meaning that the same proportion of samples was over- and under-scored. In respect to under-and over-scoring, there was no difference between conformation and fatness; 21 to 24%, 9 to 10%, 3 to 7% and 1 to 3% of samples were over and under scored for 1, 2, 3 and >3 fatness subclasses, respectively.
Discussion
In the present study the agreement of grading results by approved classifier and ANN (tolerance of ±1 subclass, which is acceptable difference in on-spot checks) was 73.6% for conformation and 64.9% for fatness (; and ). For the comparison, similar results were reported in the review for various VIA systems by Craigie et al. (Citation2012). However, in case of VIA systems the success rate for exact predictions was higher than in the present study. To evaluate the quality of developed models it would be good to compare the results to the repeatability and reproducibility. However, such data for classifiers working in real abattoir conditions is lacking. For bovine classification system, to our knowledge only Borggaard et al. (Citation1996) reported repeatability and reproducibility which were 0.51 and 0.80 for conformation and 0.73 and 1.15 for fatness, respectively. It is worth noting that in their study matching between classifier and reference (inspector) was lower than between BCC-2 and reference (0.57 and 0.97 for conformation and fatness, respectively). Accuracy of beef carcass classification was also studied by Díez et al. (Citation2003 and Citation2006) who demonstrated also an effect of carcass weight (standard, light) on classifiers’ performance. In the present analysis, the prediction ability of ANN (agreement with the classifier’s grade) was related to the incidence of carcasses belonging to the class. Low prediction ability of ANN models was in particular evident for classes with low incidence, which rarely occur. The classes with low number of carcasses (<100) had very poor success of prediction and the classes with less than 10 samples were practically not identifiable (0 to 10% success rate in E+ class; ). It can be speculated that the classifier is not familiar with exceptionally well conformed carcasses because they are very rare (E-, E and E+ together present ≈0.5% of population used). In addition, low number of carcasses in class E could affect training performance of ANN. On the other hand, the classifier seems more familiar with poorly conformed carcasses despite the fact that are also less typical for bulls. Class P is usual in the case of cows, which explains better predictions (in particular P+ and P). Modest results in the case of well represented middle subclasses (R-, R, R+) could be a consequence of the preferential decision for middle class when in doubt. This is further substantiated by the fact that this class is overrepresented in the population when related to normal distribution (). In addition, the number of classes may be too big. As reviewed by Craigie et al. (Citation2012) a scale 1 to 5 is too narrow, a scale greater than 10 is too wide. In view of these shortcomings it is not likely that the classifier is able to use the scale properly. It also seems ineffective to split classes that occur rarely (e.g. E and P) into subclasses, since the classifiers are unfamiliar with them. A division into subclasses seems reasonable only in the case of well represented middle classes (U, R, O and 2, 3, 4, respectively for conformation and fatness). Moreover, two subclasses (inferior and superior) would most likely be sufficient. A system with lower number of classes would also be more suitable with respect to the human ability for discrimination. In general, about 10% lower accuracy of prediction was observed for fatness than for conformation. Here as well, higher incidence of class was associated with better prediction i.e. the best agreement between classifier and ANN was obtained for classes 2 and 3, which represent 95% of the population. It is worth noting that high fat cover classes (4, 5) which represent around 1%, were very problematic. In agreement with our results, lower prediction accuracy for fatness (12 to 21%) was also reported in calibration trials for various VIA systems (Allen and Finnerty, Citation2001). Higher correspondence between ANN and classifier for conformation, observed in the present study, could be explained by the fact that breed proportion and carcass weight are good descriptors of conformation. On the other hand, factors related to feeding which affect the fatness, were not included as descriptors in our study. To our opinion lower standard deviation for fatness than conformation (1.7 vs 2.3, respectively; ) could also be a reason for less accurate prediction of fatness. Opposite to our justification, Allen and Finnerty (Citation2001) assumed that inferior prediction of fatness than conformation was due to its higher variability (3.4 vs 1.9, respectively). To understand these differences it should be taken into account that calibration trials reported by Allen and Finnerty (Citation2001) include different categories of cattle, whereas only bulls were included in ours. Uneven skin removal could also explain inferior prediction of fatness in the case of automatic VIA grading system. Respecting the rules prescribed in EU legislation regarding the authorisation of automatic grading our models would not meet the criteria (data not shown). It should be noted that it was neither our original aim nor it would be appropriate. Namely, the authorisation (European Commission, Citation2008) involves a certification test consisting of a panel of at least five licensed experts with their median taken as the reference value. It concerns all categories of cattle that are representative of the population. Matching between panel and machine is evaluated through the system of points where incorrect classifications are penalized. In respect of the authorisation current study bears the shortcomings; actual data from the slaughter line are used as the reference value, i.e. only one classifier, only one category of cattle (bulls) is involved, data set risks a number of errors resulting from on-line work, operator bias, typing mistakes, potential outliers, etc., which we could not identify and remove. As a result, such erroneous data were trained as correct ones in development of ANN models, which have the ability to learn and adapt (key characteristic of ANN often mentioned in the literature). In view of the mentioned limitations, the present study is only a preliminary study aiming to demonstrate the potential of ANN for practical use.
Conclusions
Overall predictive ability of ANN for carcass classification of bulls using data on carcass weight, age and breed proportions was better for conformation than fatness (73.6 vs 64.9% matching with approved classifier, respectively). Success rate of prediction varied between classes and was related to the incidence of carcasses in the class. The study shows that ANN has the potential for the prediction of grading result at slaughter; however further tests are needed in view of its potential as a standalone grading method.
Acknowledgements
the authors would like to thank Bureau Veritas, the official classification body, for providing classification data. The financial support of Slovenian Research Agency (programmes P4-0133, P1-0017, P1-0164) and the support of COST Action FA1102 (FAIM) are also greatly appreciated.
References
- AlbertíP.Panea B.Sañudo C.Olleta J.L.Ripoll G.Ertbjerg P.Christensen M.Gigli S.Failla S.Concetti S.Hocquette J.F.Jailler R.Rudel S.Renand G.Nute G.R.Richardson R.I.Williams J.L., 2008. Live weight, body size and carcass characteristics of young bulls of fifteen European breeds. Livest. Sci. 114:19-30.
- AllenP.Finnerty N., 2001. Mechanical grading of beef carcasses. Teagasc-Agriculture and Food Development Authority ed., Dublin Ireland.
- BorggaardC.Madsen N.T.Thodberg H.H., 1996. In-line image analysis in the slaughter industry, illustrated by beef carcass classification. Meat Sci. 43:151-163.
- CraigieC.R.Navajas E.A.Purchas R.W.Maltin C.A.Bünger L.Hoskin S.O.Ross D.W.Morris S.T.Roehe R., 2012. A review of the development and use of video image analysis (VIA) for beef carcass evaluation as an alternative to the current EUROP system and other subjective systems. Meat Sci. 92:307-318.
- Dayhof J.E., 1990. Neural network architectures: an introduction. Van Nostrand Reinhold Co., New York NY USA.
- DíezJ.Albertí P.Ripoll G.Lahoz F.Fernández I.Olleta J.L.PaneaB.SañudoC.Bahamonde A.GoyacheF., 2006. Using machine learning procedures to ascertain the influence of beef carcass profiles on carcass conformation scores. Meat Sci. 73:109-115.
- DíezJ.Bahamonde A.Alonso J.López S.del CozJ.J.Quevedo J.R.Ranilla J.Luaces O.Alvarez I.Royo L.J.Goyache F., 2003. Artificial intelligence techniques point out differences in classification performance between light and standard bovine carcasses. Meat Sci. 64:249-258.
- European Commission, 2006. Council regulation of 24 July 2006 concerning the Community scale for the classification of carcasses of adult bovine animals, 1183/2006/EC. In: Official Journal, L 214, 4/8/2005, pp 1-6.
- European Commission, 2007. Council regulation of 22 October 2007 establishing a common organisation of agricultural markets and on specific provisions for certain agricultural products, 1234/2007/EC. In: Official Journal, L 229, 16/11/2007, pp 1-149.
- European Commission, 2008. Council regulation of 10 December 2008 laying down detailed rules on the implementation of the Community scales for the classification of beef, pig and sheep carcasses and the reporting of prices thereof, 1249/2008/EC. In: Official Journal, L 337, 16/12/2008, pp 3-30.
- Hecht-NielsenR., 1987. Counterpropagation networks. Appl. Optics 26:4979-4984.
- KeaneM.G.Allen P., 1998. Effects of production system intensity on performance, carcass composition and meat quality of beef cattle. Livest. Prod. Sci. 56:203-214.
- PrevolnikM.Knap M.Žabjek A.Čandek-Potokar M., 2011. The effect of the abattoir on beef carcass classification results. In: M. (ed.) Kapš agriculturae conspectus scientificus. Universities of the Quadrilateral Agreement Publ., Zagreb Croatia, pp 169-173.
- ZupanJ., 1994. Introduction to artificial neural network (ANN) methods: what they are and how to use them. Acta Chim. Slov. 41:327-352.
- ZupanJ.Novič M.Ruisanchez I., 1997. Kohonen and counter propagation artificial neural networks in analytical chemistry. Chemomet. Intell. Lab. 38:1-23.
APPENDIX