Figures & data
Fig. 1 Schematic of the DeepSets representation. Each independent replicate is transformed independently using the function
. The set of transformed inputs are then aggregated elementwise using a permutation-invariant function,
, yielding the summary statistic T. Finally, the summary statistic is mapped to parameter estimates estimates
by the function
. Many classical estimators take this form; in this work, we use neural networks to model
and
.
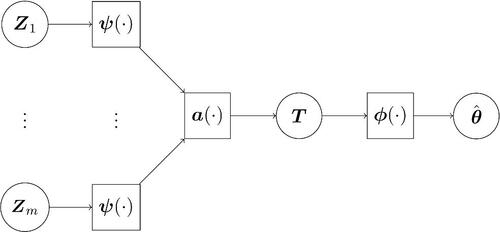
Fig. 2 Kernel density approximations to the distribution of the Bayes estimator (green line), our neural Bayes estimator (red line), the maximum likelihood estimator (purple line), and the one-at-a-time estimator (orange line), for θ from data, where
(gray dashed line) and where the sample size is m = 10.
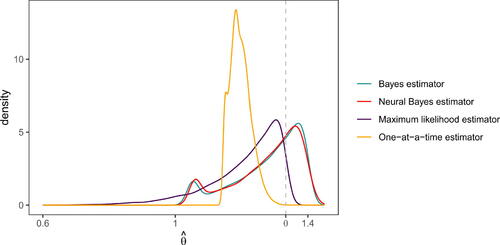
Fig. 3 The risk with respect to the 0–1 loss against the number of replicates, m, evaluated using the parameter vectors in the test parameter set, for the estimators considered in Section 3.2. The estimators ,
, and the MAP estimator are shown in green, orange, and purple, respectively.
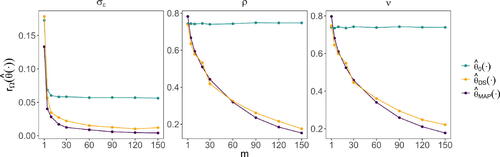
Fig. 4 The empirical joint distribution of the estimators considered in Section 3.2 for a single parameter vector. The true parameters are shown in red, while estimates from ,
, and the MAP estimator are shown in green, orange, and purple, respectively. Each estimate was obtained from a simulated dataset of size
.
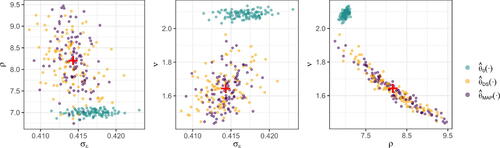
Fig. 5 Diagnostic plots for the simulation study of Section 3.3. (Left and center) The risk with respect to the 0–1 loss against the number of replicates, m, evaluated using the parameter vectors in the test parameter set. (Right) True parameters (red) and corresponding estimates, each of which was obtained using a simulated dataset of size m = 150. In all panels, ,
, and the pairwise MAP estimator are shown in green, orange, and purple, respectively.
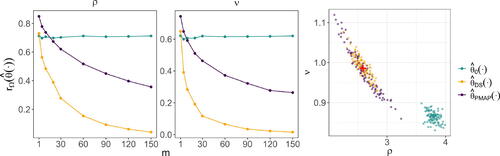
Fig. 6 The risk with respect to the 0–1 loss against the number of replicates, m, evaluated using the parameter vectors in the test parameter set, for the estimators considered in Section 3.4. The estimators and
are shown in green and orange, respectively.
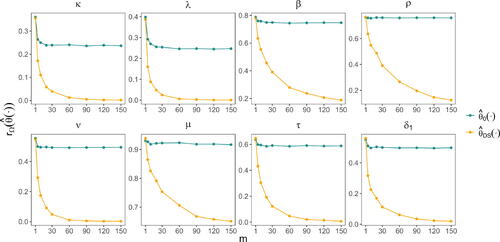
Fig. 7 (Lower triangle) The empirical joint distribution of the estimators considered in Section 3.4 for a single parameter vector. The true parameters are shown in red, while estimates from and
are shown in green and orange, respectively. Each estimate was obtained from a simulated dataset of size m = 150. (Upper triangle) Simulations from the model.
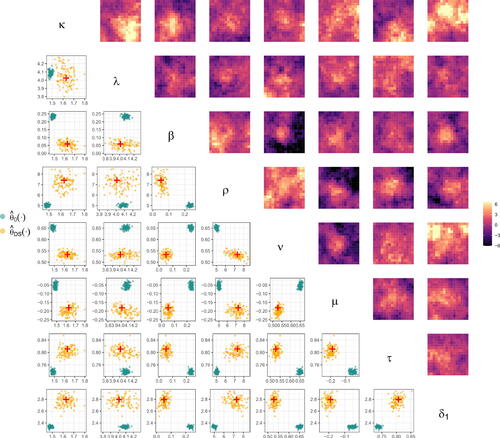
Table 1 Parameter estimates and 95% bootstrap confidence intervals (provided via the 2.5 and 97.5 percentiles of the bootstrap distribution) for the Red Sea dataset of Section 4.
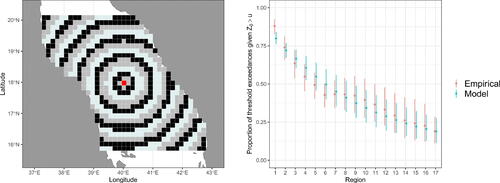
Fig. 8 (Left) The spatial domain of interest for the Red Sea study of Section 4, with the conditioning site, , shown in red, and the remaining locations separated into 17 regions; the region labels begin at 1 in the center of the domain and increase with distance from the center. (Right) The estimated proportion of locations for which the process exceeds u given that it is exceeded at
(points) and corresponding 95% confidence intervals (vertical segments) using model-simulated datasets (blue) and bootstrap samples of the observed dataset (red).