
Figures & data
Table 1. Emergency supplies dispatch table.
Table 2. The parameter list.
Figure 1. Reinforcement learning mechanism.
Figure 2. Location distribution diagram of the example: (a) Example R101: (b) Example C101.
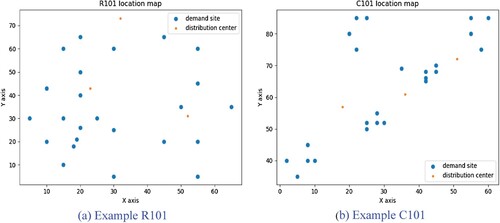
Table 3. R101 example demand point information table.
Table 4. R101 example distribution centre information table.
Table 5. R101 example distribution vehicle information table.
Table 6. C101 example demand point information table.
Table 7. C101 example distribution centre information table.
Table 8. C101 example distribution vehicle information table.
Figure 3. Iteration diagram of fair index optimisation: (a) R101 iterative graph of fair index optimisation: (b) C101 iterative graph of fair index optimisation.
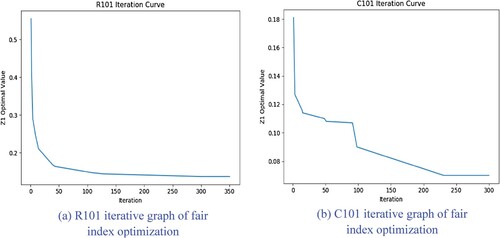
Figure 4. Ant colony parameter tuning: (a) ACS algorithm and parameter: (b) MMAS algorithm and parameter: (c) ACS algorithm parameter selection: (d) MMAS algorithm parameter selection: (e) Ant Quantity.
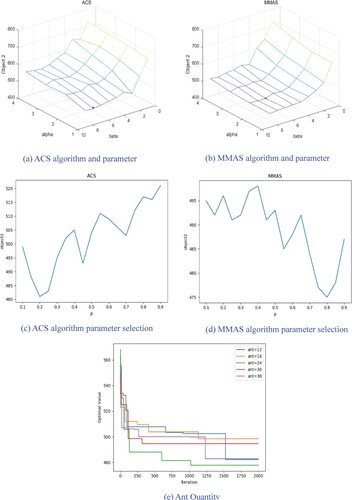
Figure 5. Roadmap of vehicle distribution: (a) R101 Vehicle distribution roadmap: (b) C101 Vehicle distribution roadmap.
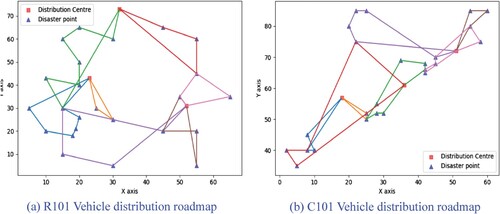
Table 9. R101 is an example of a vehicle distribution route.
Table 10. C101 is an example of a vehicle distribution route.
Table 11. Comparison of the results of two allocation schemes.
Table 12. R101 example algorithm comparison results.
Table 13. C101 example algorithm comparison results.
Figure 6. Comparison of algorithm convergence: (a) Comparison of algorithm convergence in R101 example: (b) Comparison of algorithm convergence in C101 example.
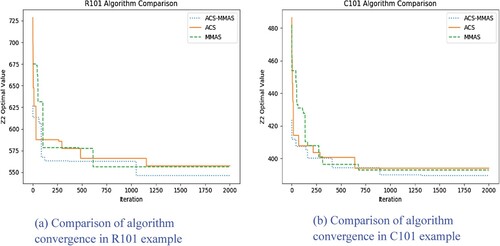
Figure 7. Pareto frontier comparison of algorithms: (a) R101 example Pareto frontier: (b) C01 example Pareto frontier.
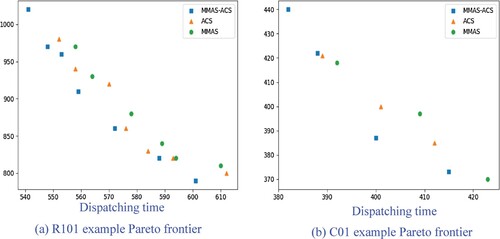
Figure 8. Shadow area is the HV value of the solution set S′.
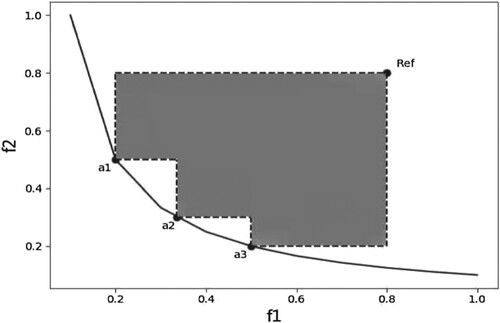
Table 14. Algorithm HV value comparison.
Data availability statement
Data available on request from the authors.