
Figures & data
Table 1. An example with 3 jobs and 10 units of resource.
Figure 1. An example that demonstrates job swapping. Two indices are selected randomly, and the corresponding jobs are swapped. In this example, indices 3 and 9 are selected, and the jobs within those indices, 2 and 9, are swapped.
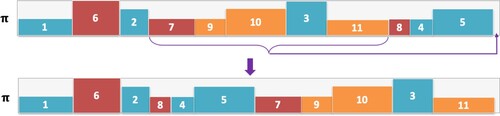
Figure 2. An example that demonstrates β-sampling. From the sequence π, a subset of jobs is selected (7, 9, 10, 3, 11) and moved to the end of the sequence.
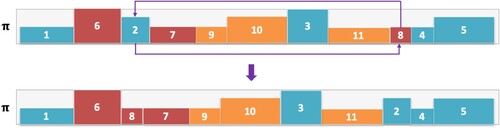
Figure 3. Adaptive probabilities over 200 simulations.
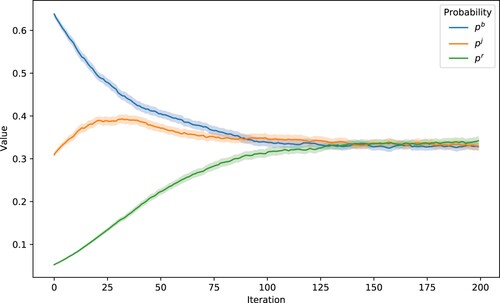
Figure 4. An example of a problem with three machines and 15 jobs. From π, jobs are selected in order (left to right) and scheduled on machines that they belong to (e.g. orange jobs on ). Those jobs that have predecessors that are not yet scheduled will be put on the waiting list
; (a) Job 8 requires Job 2 to be scheduled before it can be scheduled. (b) Job 8 is scheduled once Job 2 has been scheduled, and this will be done as early as possible considering resources.
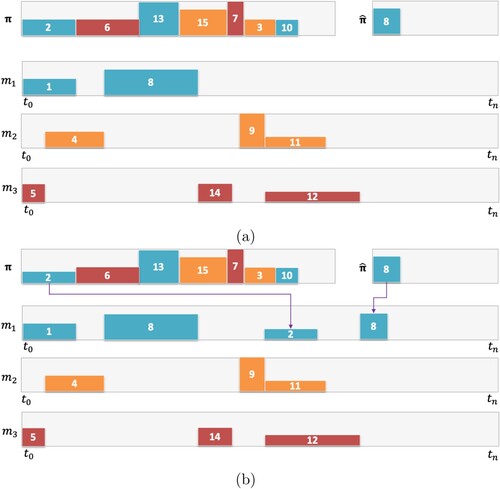
Table 2. Results of ACS, SACS and APSA shown as the percentage difference to the best solution for uncertainty levels 0.5, 0.6 and 0.7; Results in column ‘Best’ are highlighted in bold if APSA finds the best solution; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
Table 3. Results of ACS, SACS and APSA shown as the percentage difference to the best solution for uncertainty levels 0.8, 0.9 and 1.0; Results in column ‘Best’ are highlighted in bold if APSA finds the best solution; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
Figure 5. The figure shows a bar chart of the performance of ACS, SACS and APSA. It shows the average percentage difference to best (y-axis) for each uncertainty level (x-axis). We see that APSA has a distinct advantage across all uncertainty levels.
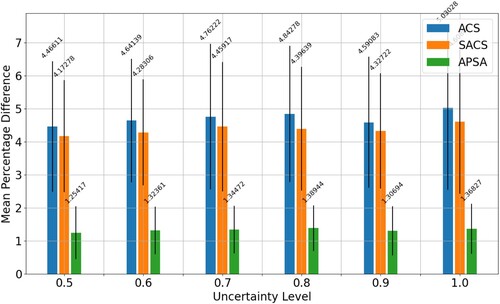
Figure 6. A comparison of SACS (left) and APSA (right) for RCJSU at uncertainty level 0.6 considering varying levels of resource utilisation (top = 0.25, middle = 0.5
, bottom = 0.75
), machine sizes and precedence proportion. Gap
=
, where B is APSA or SACS and b* is the best solution.
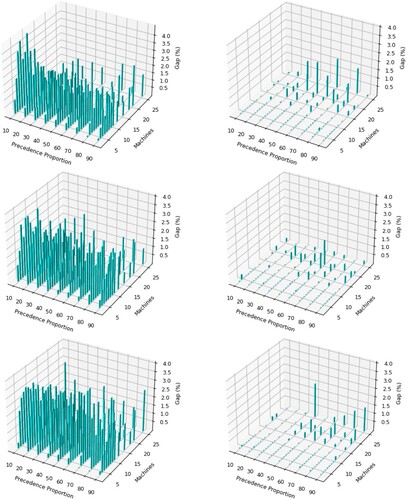
Figure 7. A comparison of SACS (left) and APSA (right) for RCJSU at uncertainty level 0.9 considering varying levels of resource utilisation (top = 0.25, middle = 0.5
, bottom = 0.75
), machine sizes and precedence proportion. Gap
=
, where B is APSA or SACS and
is the best solution.
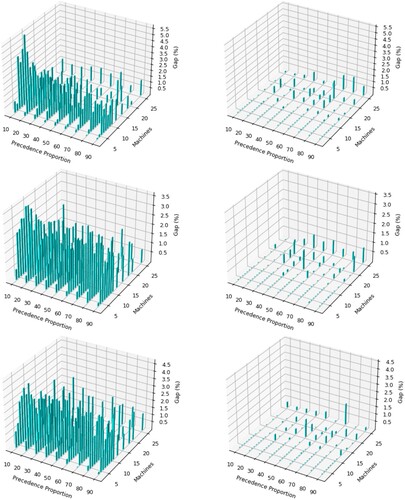
Figure 8. Convergence profiles of ACS, SACS and APSA on four RCJSU problem instances of different sizes. The instances chosen are 3–53, 6–28, 9–47 and 12–14. The TWTs on the y-axes are presented on a logarithmic scale.
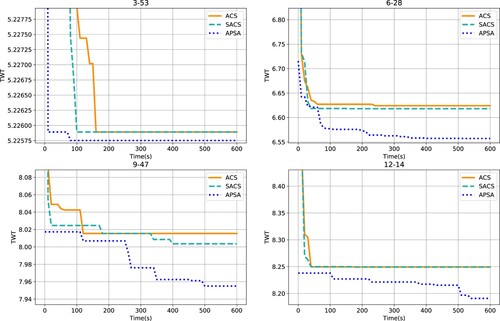
Table 4. A comparison of APSA and the original SA (Singh and Ernst Citation2011) (OSA) for the uncertainty levels of 0.6 and 0.9; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
Table 5. A comparison of APSA with different population sizes, v = 10 and v = 1, on the problem instances with uncertainty levels of 0.6 and 0.9; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
Table 6. A comparison of CGACO (Thiruvady, Singh, and Ernst Citation2014), ACS, SACS and APSA on RCJS.
Table A1. A comparison of APSA variants with different population sizes, , on selected problem instances (4–61, 8–53, 12–14 and 20–6) with uncertainty levels of 0.6 and 0.9.
Table A2. A comparison of APSA variants with different levels of Metropolis-Hastings iterations, , on selected problem instances (4–61, 8–53, 12–14 and 20–6) with uncertainty levels of 0.6 and 0.9.
Table A3. A comparison of APSA variants with different levels of γ, , on selected problem instances (4–61, 8–53, 12–14 and 20–6) with uncertainty levels of 0.6 and 0.9.
Data availability statement
The authors confirm that the data supporting the findings of this study are available within the article.