
Figures & data
Figure 1. Schematic diagram of a three-layer fully-connected feed-forward neural network. The output of neuron i from layer k is denoted and the bias node for layer k denoted
. The arrows connecting pairs of neurons are the trainable weights
. The output of each layer is computed from a weighted sum of outputs of the previous layer passed through a nonlinear activation function (Equation (Equation1
(1)
(1) )). (Image constructed using code downloaded from http://www.texample.net/tikz/examples/neural-network with the permission of the author Kjell Magne Fauske.)
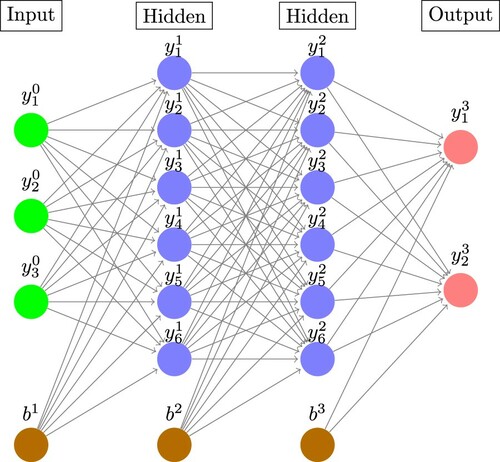
Figure 2. Schematic diagram of the Markov state model (MSM) construction and analysis pipeline. (a) Many short molecular dynamics trajectories are collected. (b) The snapshots constituting each trajectory are featurized, projected into a low-dimensional space, and clustered into microstates. Each frame in each trajectory is assigned to a microstate. For illustrative purposes, four microstates are considered and coloured green, blue, purple, and pink. (c) Counting the number of transitions between microstates furnishes the transition counts matrix. (d) Assuming the system is at equilibrium and therefore follows detailed balance, the count matrix is symmetrised and normalised to generate the reversible transition matrix defining the conditional transition probabilities between microstates. (e) The equilibrium distribution over microstates is furnished by the leading eigenvector of the transition probability matrix, here illustrated in a pie chart. States with greater populations are more thermodynamically stable. (f) The higher eigenvectors correspond to a hierarchy of increasingly fast dynamical relaxations over the microstates. The first of these possess a negative entry corresponding to the green state and positive entries for the other states, therefore characterising the net transport of probability distribution out of the green microstate and into the blue, purple, and pink. If desired, the microstates can be further coarse grained into macrostates, typically by clustering of the microstate transition matrix. Image reprinted with permission from Ref. [Citation20]. Copyright (2018) American Chemical Society.
![Figure 2. Schematic diagram of the Markov state model (MSM) construction and analysis pipeline. (a) Many short molecular dynamics trajectories are collected. (b) The snapshots constituting each trajectory are featurized, projected into a low-dimensional space, and clustered into microstates. Each frame in each trajectory is assigned to a microstate. For illustrative purposes, four microstates are considered and coloured green, blue, purple, and pink. (c) Counting the number of transitions between microstates furnishes the transition counts matrix. (d) Assuming the system is at equilibrium and therefore follows detailed balance, the count matrix is symmetrised and normalised to generate the reversible transition matrix defining the conditional transition probabilities between microstates. (e) The equilibrium distribution over microstates is furnished by the leading eigenvector of the transition probability matrix, here illustrated in a pie chart. States with greater populations are more thermodynamically stable. (f) The higher eigenvectors correspond to a hierarchy of increasingly fast dynamical relaxations over the microstates. The first of these possess a negative entry corresponding to the green state and positive entries for the other states, therefore characterising the net transport of probability distribution out of the green microstate and into the blue, purple, and pink. If desired, the microstates can be further coarse grained into macrostates, typically by clustering of the microstate transition matrix. Image reprinted with permission from Ref. [Citation20]. Copyright (2018) American Chemical Society.](/cms/asset/1b52a065-8ca2-451f-8ae5-9d9a07fb437d/tmph_a_1737742_f0002_oc.jpg)
Figure 3. Schematic illustration of iMapD. The curved teal sheet is a cartoon representation of a low-dimensional manifold residing within the high-dimensional coordinate space of the molecular system (black background) and to which the system dynamics are effectively restrained. This manifold supports the low-dimensional molecular free energy surface of system (red contours denote potential wells). The dimensionality of the manifold, good collective variables with which to parameterise it, and topography of the free energy surface are a priori unknown. iMapD commences by running short unbiased simulations to perform local exploration of the underlying manifold and which define an initial cloud of points . Boundary points are identified, here
and
, and local PCA applied to define a locally-linear approximation to the manifold geometry that is locally valid in the vicinity of each point. An outward step is then taken within these linear subspaces, here from
to expand the exploration frontier. The projected point may lie off the manifold due to the linear approximation inherent in the outward projection and so a short ‘lifting’ operation is employed to relax it back to the manifold. This point then seeds a new unbiased simulation that generates a new cloud of points
and the process is repeated until the manifold is fully explored. In this manner iMapD explores the manifold by ‘walking on clouds’. Image adapted with permission from Ref. [Citation63].
![Figure 3. Schematic illustration of iMapD. The curved teal sheet is a cartoon representation of a low-dimensional manifold residing within the high-dimensional coordinate space of the molecular system (black background) and to which the system dynamics are effectively restrained. This manifold supports the low-dimensional molecular free energy surface of system (red contours denote potential wells). The dimensionality of the manifold, good collective variables with which to parameterise it, and topography of the free energy surface are a priori unknown. iMapD commences by running short unbiased simulations to perform local exploration of the underlying manifold and which define an initial cloud of points C(1). Boundary points are identified, here BP1(1) and BP2(1), and local PCA applied to define a locally-linear approximation to the manifold geometry that is locally valid in the vicinity of each point. An outward step is then taken within these linear subspaces, here from BP1(1) to expand the exploration frontier. The projected point may lie off the manifold due to the linear approximation inherent in the outward projection and so a short ‘lifting’ operation is employed to relax it back to the manifold. This point then seeds a new unbiased simulation that generates a new cloud of points C(2) and the process is repeated until the manifold is fully explored. In this manner iMapD explores the manifold by ‘walking on clouds’. Image adapted with permission from Ref. [Citation63].](/cms/asset/c3aa5750-ea24-4fea-bd88-b36f9519c305/tmph_a_1737742_f0003_oc.jpg)
Figure 4. Schematic illustration of SandCV. Molecular configurations are aligned to a reference configuration
then projected onto the Isomap manifold using a nearest neighbour projection and a basis function expansion in a number of landmark points
. Enhanced sampling using adaptive biasing force (ABF) is effected by propagating biasing forces over the manifold
into forces on atoms
through the Jacobian of the explicit and differentiable composite mapping function
. Image reprinted from Ref. [Citation39], with the permission of AIP Publishing.
![Figure 4. Schematic illustration of SandCV. Molecular configurations r are aligned to a reference configuration A(r) then projected onto the Isomap manifold using a nearest neighbour projection and a basis function expansion in a number of landmark points M−1∘P(x). Enhanced sampling using adaptive biasing force (ABF) is effected by propagating biasing forces over the manifold F(ξ) into forces on atoms F(r) through the Jacobian of the explicit and differentiable composite mapping function C(r)=M−1∘P∘A(r). Image reprinted from Ref. [Citation39], with the permission of AIP Publishing.](/cms/asset/ffe90e9b-25ee-43a3-8651-16a2edd0f05b/tmph_a_1737742_f0004_oc.jpg)
Figure 5. Molecular enhanced sampling with autoencoders (MESA). An autoencoding neural network (autoencoder) is trained to reconstruct molecular configurations via a low-dimensional latent space where the CVs are defined by neuron activations within the bottleneck layer. The encoder performs the low-dimensional projection from molecular coordinates
in the high dimensional atomic coordinate space
into the low-dimensional latent space
and the decoder
performs the approximate reconstruction back to
. The encoder furnishes, by construction, an exact, explicit, and differentiable mapping from the atomic coordinates to CVs that can be modularly incorporated into any off-the-shelf CV biasing enhanced sampling technique.
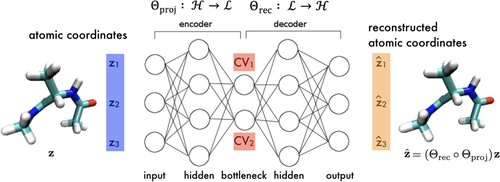
Figure 6. Block diagram of a time-lagged autoencoder (TAE). The encoder projects a molecular configuration at time t into a low-dimensional latent embedding
from which a time-lagged molecular configuration
at time
is subsequently reconstructed. For τ = 0 the TAE reduces to a standard AE and the CV discovery process is equivalent to MESA (Section 3.3). Image reprinted from Ref. [Citation108], with the permission of AIP Publishing.
![Figure 6. Block diagram of a time-lagged autoencoder (TAE). The encoder projects a molecular configuration zt at time t into a low-dimensional latent embedding et from which a time-lagged molecular configuration zt+τ at time (t+τ) is subsequently reconstructed. For τ = 0 the TAE reduces to a standard AE and the CV discovery process is equivalent to MESA (Section 3.3). Image reprinted from Ref. [Citation108], with the permission of AIP Publishing.](/cms/asset/a5bce448-1438-4a61-b1d5-4bccb86551d6/tmph_a_1737742_f0006_ob.jpg)
Figure 7. State-free reversible VAMPnets. Pairs of time-lagged molecular configurations are featurized and transformed by a twin-lobe ANN into a space of nonlinear basis functions
. These basis functions are employed within a linear VAC to furnish approximations
to the leading eigenfunctions of the transfer operator. The twin-lobed ANN is trained to maximise a VAMP-r score measuring the cumulative kinetic variance explained and which reaches a maximum when the eigenfunction approximations are coincident with the true eigenfunctions of the transfer operator.
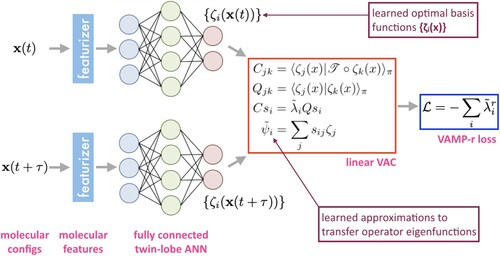
Figure 8. Deep Generative MSM (DeepGenMSM) and the ‘rewiring trick’. (left) The encoder within the twin-lobe ANN is trained to learn mappings of molecular configurations
to probabilistic memberships
of one of m macrostates. The generator is trained against the learned ‘landing probabilities’
that a system prepared in macrostate i will transition to molecular configuration
after a time τ. (right) The rewiring trick reconnects the generator and encoder to furnish a valid estimate
for the MSM transition matrix between the embedding into the m discrete states learned by the encoder. Image adapted from Ref. [Citation135], with permission from the author Prof. Frank Noé (Freie Universität Berlin).
![Figure 8. Deep Generative MSM (DeepGenMSM) and the ‘rewiring trick’. (left) The encoder χ(x) within the twin-lobe ANN is trained to learn mappings of molecular configurations x to probabilistic memberships y of one of m macrostates. The generator is trained against the learned ‘landing probabilities’ qi(z;τ) that a system prepared in macrostate i will transition to molecular configuration z after a time τ. (right) The rewiring trick reconnects the generator and encoder to furnish a valid estimate K~ for the MSM transition matrix between the embedding into the m discrete states learned by the encoder. Image adapted from Ref. [Citation135], with permission from the author Prof. Frank Noé (Freie Universität Berlin).](/cms/asset/a8651b78-660e-4b44-89c7-36db57fd80f4/tmph_a_1737742_f0008_oc.jpg)