Figures & data
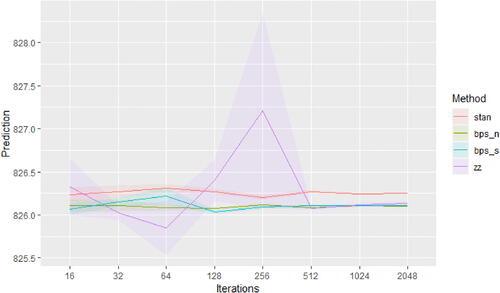
Fig. 1 Sample paths of PDMPs implementing variable selection in one dimension. The left and centre plots show the trajectories for a continuous spike-and-slab prior where
. As c decreases the spike component in the mixture approaches a Dirac mass. The figure on the right is the limiting process where we set the velocity to zero allowing the variable to stay fixed at zero.
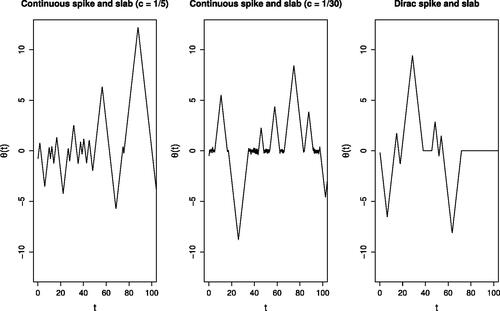
Table 1 Scenario 1 (pair of correlated variables): Relative efficiencies for methods, against a Reversible Jump algorithm, for the marginal posterior means (Mean) and marginal posterior probabilities of inclusion (PI).
Table 2 Scenario 2 (General correlation): Relative efficiency for methods, against a Reversible Jump algorithm, for the marginal posterior means (Mean) and marginal posterior probabilities of inclusion (PI). Bold figures show the best performing sampler.
Table 3 Scenario 3 (No correlation): Relative efficiency for methods, against a Reversible Jump algorithm, for the marginal posterior means (Mean) and marginal posterior probabilities of inclusion (PI).
Table 4 Scenario 4 (multiple correlated pairs): Relative efficiency for methods, against a Reversible Jump algorithm, for the marginal posterior means (Mean) and marginal posterior probabilities of inclusion (PI).
Fig. 2 Log-log plots of efficiency, relative to the Gibbs sampler, of different samplers as we vary the number of observations. Plotted are the relative efficiencies for the posterior mean conditional on model where
corresponds to the true data generated model. The dataset was generated with a 15-dimensional regression parameter
. The methods run are the Zig-Zag applied to the full dataset (zz, black), Zig-Zag with subsampling using global bounds (ss, blue), Zig-Zag with control variates (cv, magenta) and Gibbs sampling (Gibbs, green). All methods were initialized at the location of the control variate. Methods were given the same computational budget, for details see the supplementary materials.
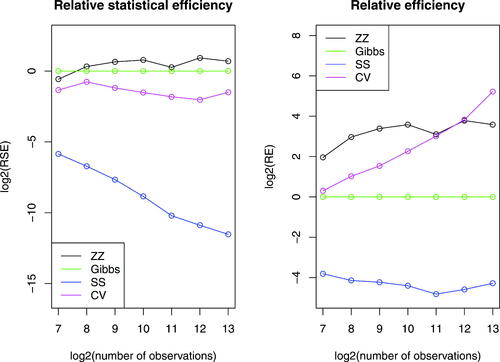
Fig. 3 Dynamics of the samplers on a robust regression example with spike and slab or horseshoe prior. The top row shows the posterior for θ1 and θ2, bottom row shows the estimates for θ2 and θ3. The spike-and-slab distributions are sampled using the reversible jump PDMP samplers with reversible jump parameter 0.6 and refreshment for the BPS methods set to 0.5. All methods are shown with 103 samples (red) and the PDMP dynamics are shown in black. Sampling with the Horseshoe prior was implemented in Stan using NUTS. Both Stan and PDMP methods were run for the same computing time. To aid visualization only the first 30% of the PDMP trajectories are shown.
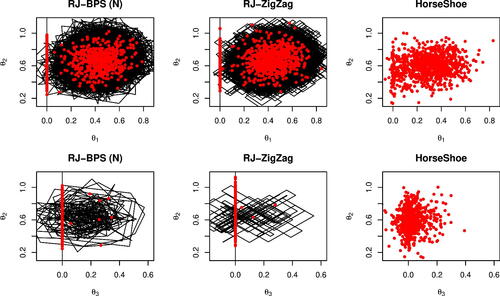
Fig. 4 Sampling efficiency for reversible jump PDMP versus Stan for the robust regression example. The PDMP samplers are ZigZag (zz), Bouncy Particle Sample with normally distributed velocities (bps_n) and with velocities distributed uniformly on the sphere (bps_s). The top figure shows boxplots of the posterior mean of θ1 for increasing computational budget, with outliers from the sampler removed for visualization purposes. These removed outliers correspond to times that the sampler has become stuck in a local mode where . The subplot shows the full results including outliers from the samplers. The Stan sampler is sampling from a different posterior to the PDMP methods, and this is seen in the estimates converging to slightly different values; but Monte Carlo efficiency can be assessed by comparing the variability of the estimates. The bottom figure shows the number of times that the samplers did not find the global mode.
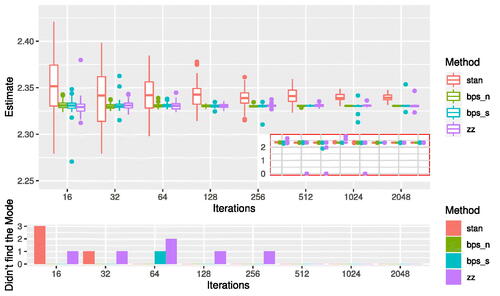
Fig. 5 Predictive ability of reversible jump PDMP versus Stan for the robust regression example. The PDMP samplers are ZigZag (zz), Bouncy Particle Sample with normally distributed velocities (bps_n) and with velocities distributed uniformly on the sphere (bps_s). The predictive ability is measured by Monte Carlo estimates of the mean square predictive performance.