Figures & data
Fig. 1 Examples of hypergraph datasets. (b) shows co-tagging data and (c) shows a subsample of the coauthorship network of Ji and Jin (Citation2016). The figures were made with R packages HyperG (Marchette Citation2021) and igraph (Csardi and Nepusz Citation2006).
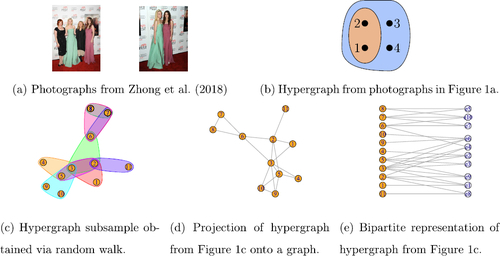
Fig. 2 Example of a Čech complex. Left: for
in
. Middle: the graph obtained by taking pairwise intersections. Right: the hypergraph obtained by taking intersections of arbitrary order. The shaded region indicates an order 3 hyperedge.
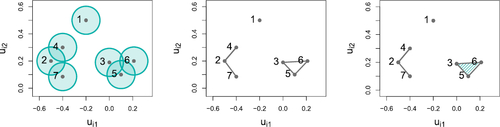
Fig. 3 Example of a nsRGH (see Definition 3.1) with . Left:
. Middle:
. Right:
.
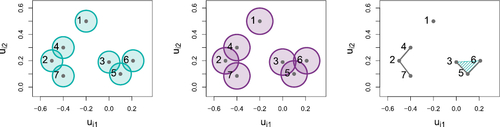
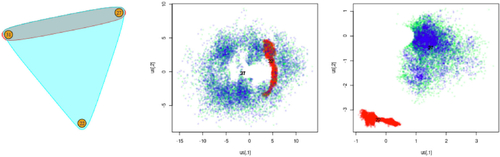
Fig. 4 Comparison of theoretical (solid) and Monte Carlo (dashed) estimates of for varying rk
. We take
and consider connection probabilities for k = 2, 3, 4. In the left plot
and in the right plot
. The same study with
is provided in Supplement F.3.
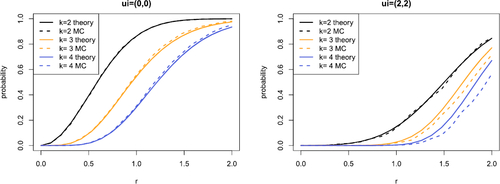
Fig. 5 Comparison between empirical (dashed line) and Poisson approximation (points) of the order k = 3 degree distribution conditional on the latent coordinate ui
. We take and evaluate the distribution for
. The left plot shows
and the right plot shows
. The equivalent Figures with
and N = 20 are given in Supplement F.3.
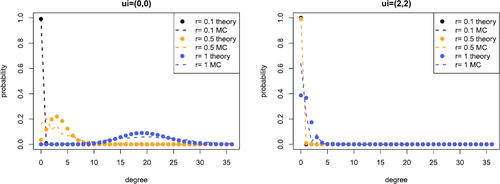
Fig. 6 Comparison of true and posterior predictive degree distributions for hyperedges of order k = 2 (left) and k = 3 (right). Vertical lines and black dots correspond to the range and median of the probabilities of observing each degree as calculated via the posterior predictive. The observed degree is shown as green triangles.
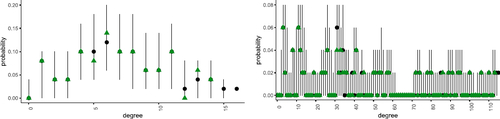
Fig. 7 Summary of average per-iteration costs after 200 iterations for an MCMC implemented with and without delayed acceptance (DA) for 10 datasets sampled from data regimes (R1) (black, circle) and (R2) (red, triangle). Left: average per-iteration cost in seconds for a DA scheme. Right: ratio of average per-iteration cost for a DA scheme and a scheme without DA. Numbers less than 1 imply DA offers a computational speed-up.
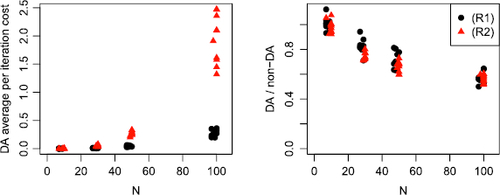
Fig. 8 Visualization of the datasets considered in Section 7. The hyperedges correspond to the observations for each dataset. Each figure shows the full hypergraph (left) and a subset sampled according to a random walk (right).
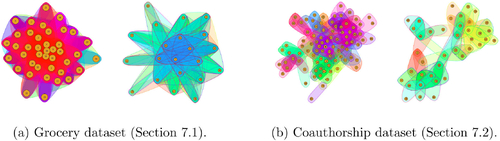
Fig. 9 Summary of predictive distributions for additional nodes for the Grocery dataset. For each measure we report the proportion of predictions which are distance D from the truth, where D is the absolute difference between the predictive and the truth.
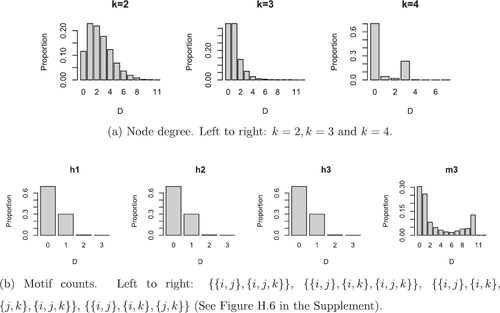
Fig. 10 Summary of predictive distributions for additional nodes for the coauthorship dataset. For each measure we report the proportion of predictions which are distance D from the truth, where D is the absolute difference between the predictive and the truth.
Fig. 11 Comparison between latent positions for subset of the coauthorship network on nodes {22, 27, 31}. Left: observed interactions. Middle: traceplot of latent positions for model with rk
= r. Right: traceplot of latent positions for our model with .