

Abstract
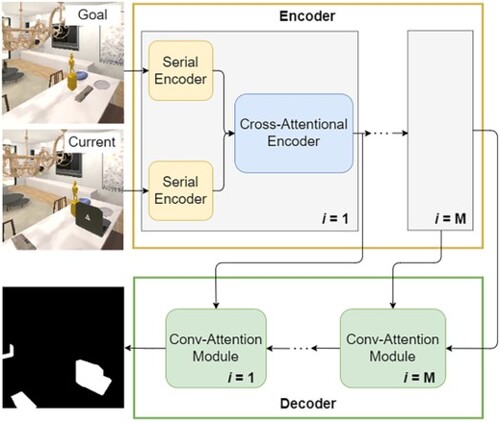
Rearranging objects (e.g. vase, door) back in their original positions is one of the most fundamental skills for domestic service robots (DSRs). In rearrangement tasks, it is crucial to detect the objects that need to be rearranged according to the goal and current states. In this study, we focus on Rearrangement Target Detection (RTD), where the model generates a change mask for objects that should be rearranged. Although many studies have been conducted in the field of Scene Change Detection (SCD), most SCD methods often fail to segment objects with complex shapes and fail to detect the change in the angle of objects that can be opened or closed. In this study, we propose a Co-Scale Cross-Attentional Transformer for RTD. We introduce the Serial Encoder which consists of a sequence of serial blocks and the Cross-Attentional Encoder which models the relationship between the goal and current states. We built a new dataset consisting of RGB images and change masks regarding the goal and current states. We validated our method on the dataset and the results demonstrated that our method outperformed baseline methods on -score and mean IoU.
GRAPHICAL ABSTRACT
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
Additional information
Funding
Notes on contributors
Haruka Matsuo
Haruka Matsuo graduated with a B.E. in computer science from Keio University, Japan, in 2023 and is currently pursuing her M.S. at the same university. Her research interests include service robots, multimodal language understanding, and machine learning.
Shintaro Ishikawa
Shintaro Ishikawa received his B.E. and M.S. degrees in computer science from Keio University, Japan, in 2021 and 2023, respectively. His research interests encompass referring expression comprehension, vision-and-language navigation, and image captioning.
Komei Sugiura
Komei Sugiura is Professor at Keio University, Japan. He obtained a B.E. in electrical and electronic engineering, and an M.S. and a Ph.D. both in informatics from Kyoto University in 2002, 2004, and 2007, respectively. From 2006 to 2008, he was a research fellow at JSPS. From 2006 to 2009, he was also with ATR. From 2008 to 2020, he was Senior Researcher at National Institute of Information and Communications Technology, Japan, before joining Keio University in 2020. His research interests include multimodal language understanding, service robots, machine learning, spoken dialogue systems, cloud robotics, imitation learning, and recommender systems.