Figures & data
Table 1. Nvidia Jetson AGX Xavier specifications.
Figure 1. The Nvidia deep learning accelerator architecture. Nvdla.org.
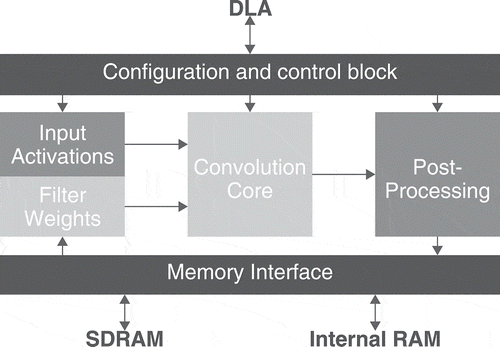
Figure 2. Modified separable convolution block replacing each of the U-net regular and transposed convolutions.
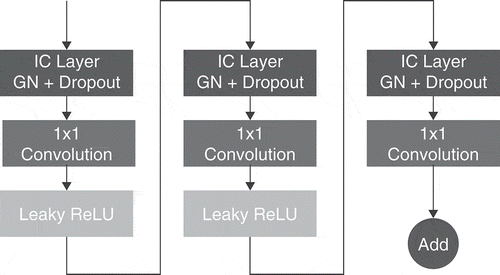
Figure 3. Composition of a separable convolution block.
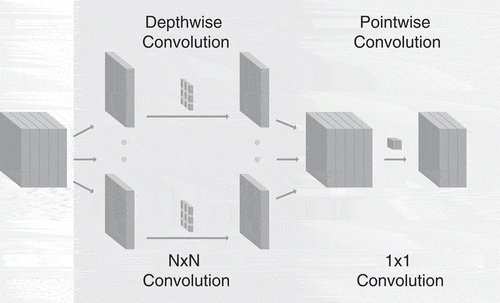
Figure 4. Our compressed U-net architecture. It consists of MobileNetV2-like separable convolution blocks coupled with max-pooling for downsampling in the encoding part of the network and bilinear upsampling in the decoding part.
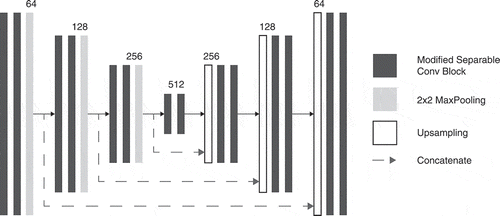
Figure 5. Four sequences and ground truth of an LGG case and two HGG cases taken from the BRaTS 2015 dataset.
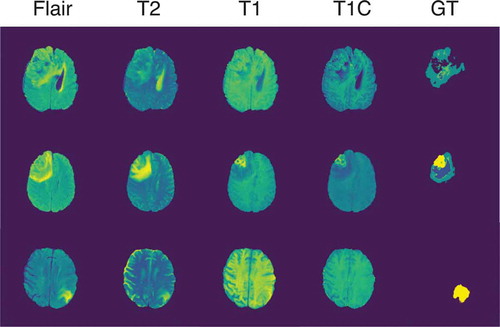
Table 2. Nvidia Jetson AGX Xavier power modes.
Table 3. Results of our proposed approach compared to other similar deep learning based brain tumor segmentation methods.
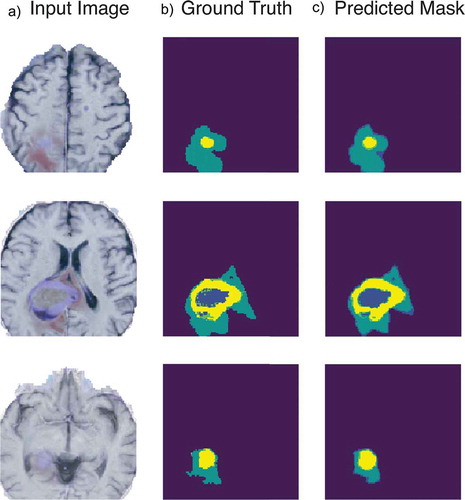
Figure 6. Example of tumor segmentation results. With a 128x128x4 input slice in A, its associated ground truth in B and the compressed model output in C.