
Figures & data
Figure 1. Overall organization of the paper.
Figure 2. The architecture of CBOW and Skip-gram as described in (Mikolov et al. Citation2013b).
Table 1. Word embedding mapping methods
Table 2. An approximate count of articles and tokens in Wikipedia dumps for each language (K = 1000)
Figure 3. The process of learning word vectors in each language.
Table 3. The number of words in seed dictionaries and size of the training, validation, and test sets (K = 1000)
Figure 4. Overview of the proposed model.
Figure 5. Encoder-Decoder architecture with an attention mechanism (Bahdanau, Cho, and Bengio Citation2016).
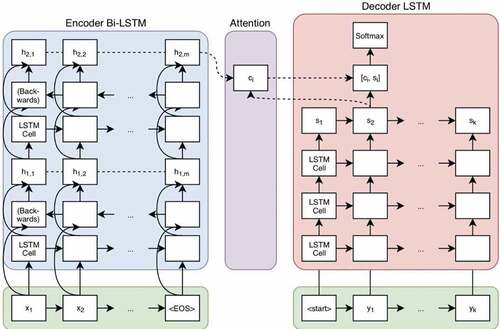
Table 4. Implemented model’s performance in different networks
Figure 6. Initial seed dictionary impact on the bilingual transform mapping.
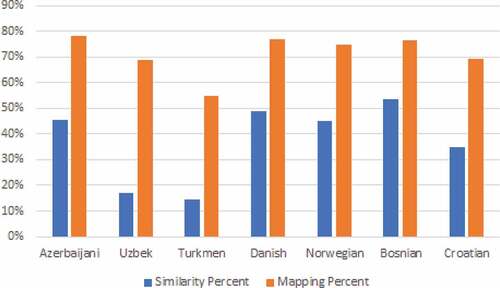
Figure 7. Differences between real and generated vectors in 3 sample words.
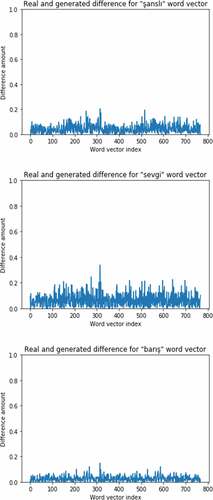
Table 5. Accuracy of the proposed method compared with previous works