
Figures & data
Figure 1. Main experiment flowchart.
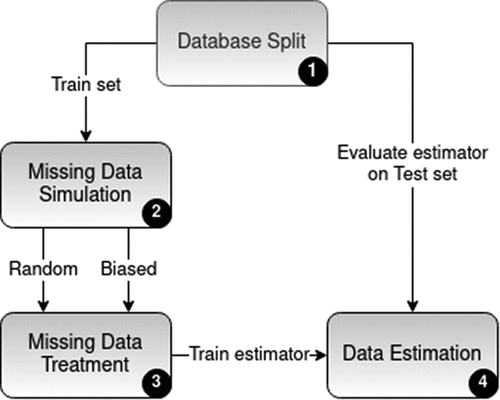
Figure 2. Main experiment detailed flowchart.
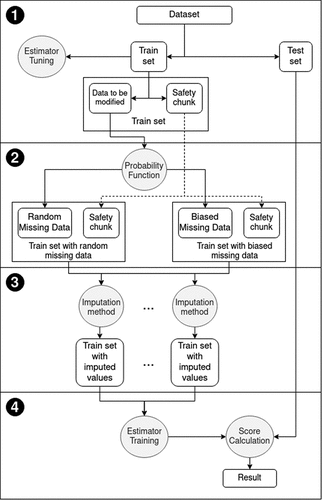
Table 1. Detailed database information. Missing analysis in regression. Feature (Feat.), Integer (Int. and Continuous (Cont.).
Figure 3. On the left: original histogram of the feature values before missing data simulation and histogram after missing data simulation. On the right: the probability function used to induce biased missing.
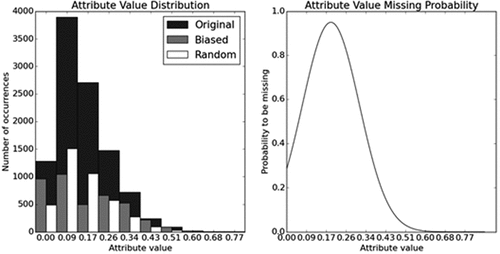
Table 2. Percentage difference means for the regression datasets (according referenced in ). 5% and 95% confidence intervals in parenthesis.
Figure 4. As the number of features with missing data increases, Discard rows become a worse choice than the imputation methods (left). As the proportion of features with missing data () increases the outcome in data regression gets worse (right).
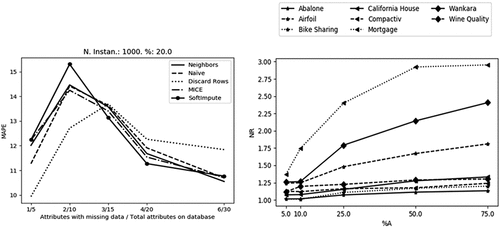
Figure 5. Importance (x axis) and Non improvement (y axis) Ratios relationship.
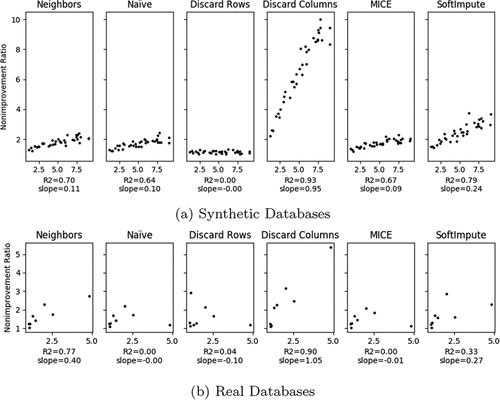
Figure 6. Winner methods separated by ,
, databases and regressors (AdaBoost, DecisionTree, KNeighbors, MLP, RandonForest, SVR).
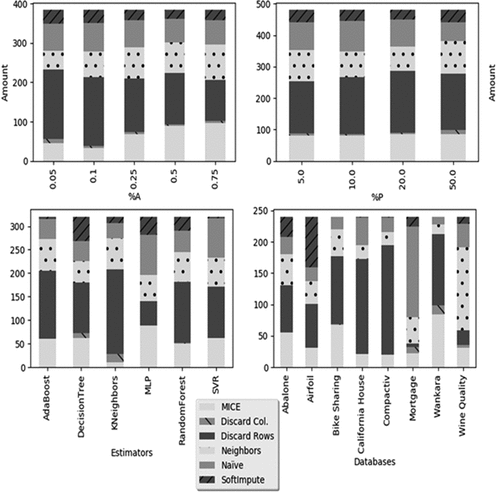
Table 3. Percentage diference means for the regression databases. 5% and 95% confidence intervals in parenthesis.