
Figures & data
Figure 1. Overview of the proposed video caption localization method based on visual rhythms.

Figure 2. Example of a caption localization mask.

Figure 3. Examples of visual rhythms extracted from mask videos.

Figure 4. Steps of the visual rhythm processing. Initially, each visual rhythm has its connected components detected. They are then filtered by a subcomponent analysis. Caption positions are retrieved from final visual rhythms.
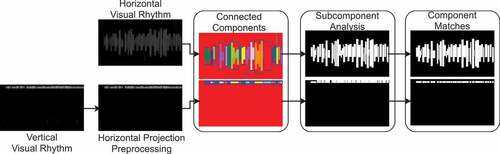
Figure 5. Example of detected and processed components.
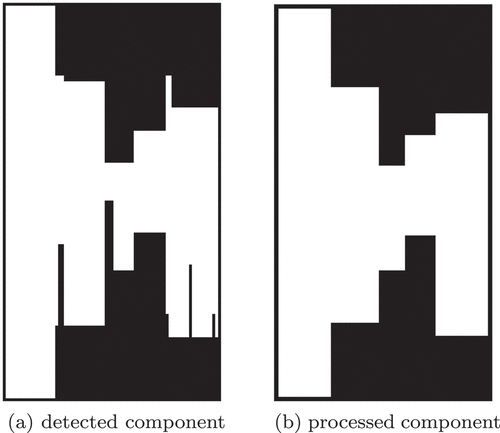
Figure 6. Examples of visual rhythms after processing.

Table 1. Information from videos collected from YouTube to compose the dataset. All videos were tagged with creative commons license.
Figure 7. Frames from each of the videos collected from YouTube.

Figure 8. Representation of text insertion in video and creation of ground-truth information.
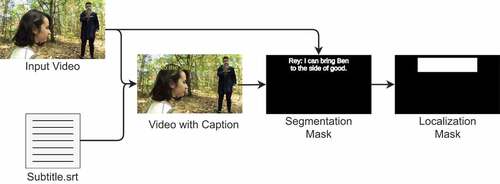
Table 2. Different scripts considered in this work.
Figure 9. Same sentence for different scripts considered.

Figure 10. Statistics for the built dataset.
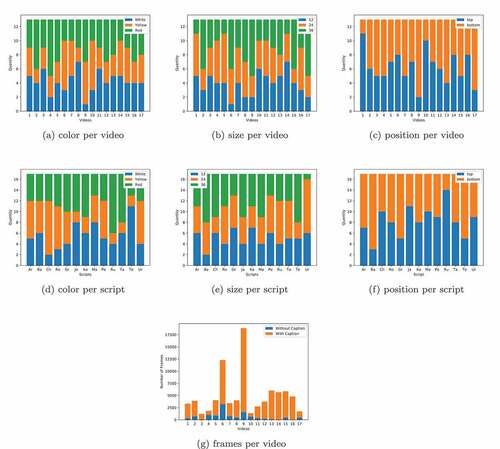
Table 3. Results obtained for detecting frames with captions for the different videos in the dataset.
Table 4. Results obtained for detecting frames with captions for different scripts.
Table 5. Results obtained for detecting frames with captions for different caption characteristics.
Table 6. Average accuracy achieved for video caption localization.
Table 7. Average accuracy obtained for caption location for each script.
Table 8. Average accuracy obtained for caption localization with different characteristics.
Figure 11. Results for frames with scene and caption text.
