
Figures & data
Table 1. An example of synthetic data is generated from the original sentence pair on our TED Talk datasets using various thresholds. If the threshold (ths) is ), standard translation units (tokens) whose frequency is greater than
in the target vocabulary will be replaced by their ATUs respectively. The source sentence is preserved while the target sentence is transformed in the dummy data pairs.
Figure 1. ATUs are corresponding to the standard translation units in the target sentence.

Figure 2. Our overall method for generating synthetic data and integrating it into the NMT system.
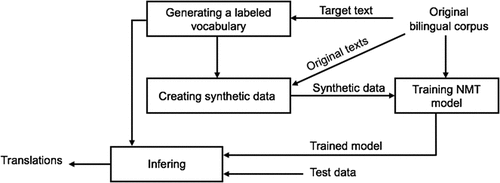
Table 2. The number of the sentence pairs is in our bilingual datasets.
Table 3. The number of monolingual sentences is used for training our BERT model.
Table 4. Our data augmentation systems overcome the baseline systems on TED Talks datasets with the frequency threshold of 7 for replacement ATUs by standard translation units in the synthetic data. Our method is also compared to the Back Translation technique.
Table 5. Our data augmentation systems overcome the baseline systems on ALT datasets with the frequency threshold of 7 for replacement ATUs by standard translation units in the synthetic data.
Table 6. The number of sentences in the target side (Vietnamese) contains ATUs when using the threshold = 7 in TED Talk and ALT datasets.
Table 7. The BLEU scores in backward models from baseline systems and vanilla systems in TED Talk Datasets. We use spacy for segmentation Japanese texts.
Table 8. The practical results of combined translation systems from Chinese, Japanese to Vietnamese on the TED Talks datasets.
Table 9. The practical results in combined training systems from Chinese, Japanese to Vietnamese on the ALT datasets.
Table 10. The practical results of translation systems when incorporating the BERT model on the TED Talks datasets. The system in (4) is then trained continuously to epoch 70 to achieve the state of the art.
Table 11. The practical results of translation systems when incorporating the BERT model on the ALT datasets. The system in (3) is also trained continuously to epoch 70.
Table 12. The number of sentence pairs in the bilingual training dataset of Japanese – Vietnamese when Japanese texts are segmented by kytea, or spacy, or mecab with the limitation in lengths of 150 source tokens in the training process.
Table 13. An example of translations in NMT systems from Japanese to Vietnamese employing our data augmentation (aug) method in the from bilingual systems.
Table 14. Results in the BLEU score and the target vocabulary sizes of combined translation systems with frequency thresholds of replacement are and
on the ALT datasets. Japanese texts are segmented by spacy.
Table 15. Results in the BLEU score and the target vocabulary sizes of combined translation systems which are augmented dummy data with frequency thresholds of replacement are and
on TED Talks datasets. Japanese texts are segmented by spacy.