
Figures & data
Table 1. DESED dataset: “Strong label” indicates the occurence and timestamp of sound events, while “weak label” merely indicates occurrence.
Figure 1. Baseline system: a CRNN model provided by DCASE task4 challenge. Each CNN block consists of a 3 × 3 convolution layer, a batch normalization layer, a GLU activation function, a dropout layer with 50% dropout rate and an average pooling layer. In the RNN part, there are two bidirectional GRU layers with 128 gated recurrent units. The CRNN model uses a fully connected layer and a sigmoid function to generate frame-level (strong) predictions, and then computes the clip-level (weak) predictions based on the frame-level predictions.
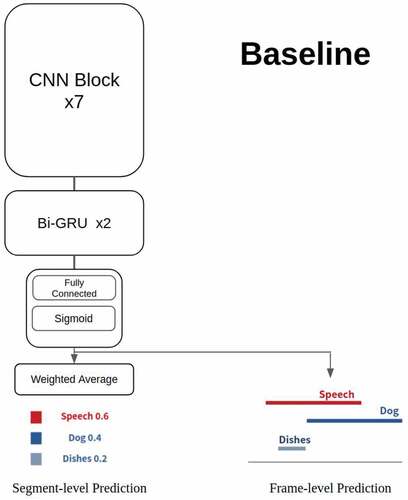
Figure 2. VGGSKCCT system: The CNN part combines one VGG block and four selective kernel units. Afterward, the system is composed of two branches. One branch is two bidirectional GRU layers and the prediction block, as in the baseline system, and the other branch is a CCT classifier.
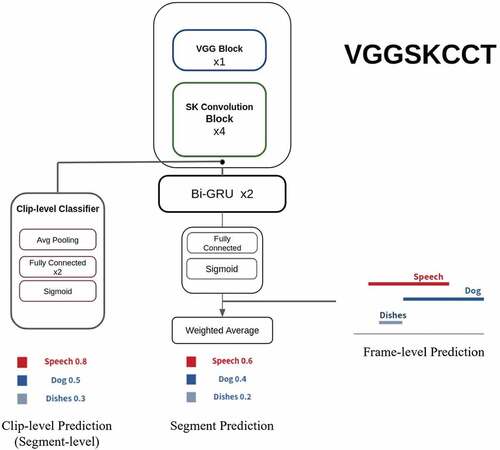
Figure 3. Mean teacher: a structure with two identical models. One is called “Student model” and the other is called “Teacher model.” In the training step, the prediction of the student model needs to be consistent with the ground truth labels and the prediction of the teacher model. After updating the parameters of the student model, the parameters of the teacher model are adjusted via the parameters of the student model using an exponential moving average.
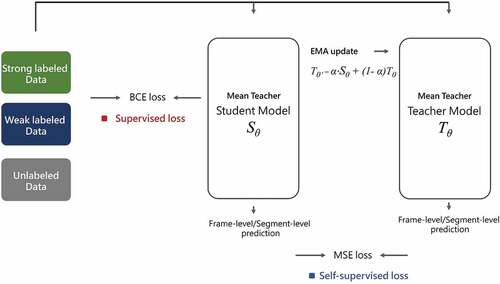
Figure 4. Second phase consistency training: the pre-trained model and (the student model in) the mean teacher model use consistency training with the mixup method. The input data in each batch has a 50% chance of being linearly combined. In addition, the parameters of the pre-trained model will be updated at the training step.
Table 2. Comparison of different models on the validation set: Comparison of different models on the validation set: The terms “Baseline,” “VGGSK” and “VGGSKCCT” denote the three systems in our experiment. Details can be found in Section Materials and methods.
Table 3. Comparison of different models on the public evaluation set: Comparison of different models on the validation set: The terms “Baseline,” “VGGSK” and “VGGSKCCT” denote the three systems in our experiment. Details can be found in Section Materials and methods.
Figure 5. Supervised loss: A figure with loss value and training step (number of total training batches). The blue one is a mean teacher model of VGGSKCCT trained in knowledge distillation (with a pre-trained model), and the red one is the same mean teacher model trained in a normal way. The lighter line in the background is the true value of the supervised loss between strong labels and strong predictions. The darker one in the foreground represents the trend in loss.
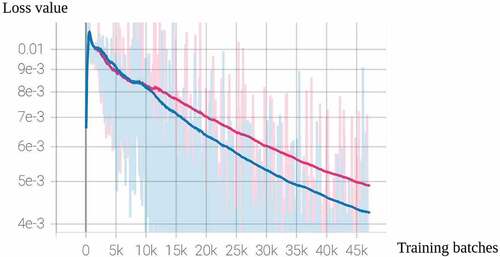
Table 4. Comparison of different training methods on the validation set: “Pre-trained” indicates a simple RepVGG model trained with the same data set. “VGGSKCCT_KD” indicates knowledge distillation with “Pre-trained” as a teacher model and the VGGSKCCT as a student model. “Vggskcct_kdmt” indicates incorporating knowledge distillation and the mean teacher method on the VGGSKCCT model.
Table 5. Comparison of different training methods on the public evaluation set: “Pre-trained” indicates a simple RepVGG model trained with the same data set. “VGGSKCCT_KD” indicates knowledge distillation with “Pre-trained” as a teacher model and the VGGSKCCT as a student model. “Vggskcct_kdmt” indicates incorporating knowledge distillation and the mean teacher method on the VGGSKCCT model.
Table 6. Comparison of two-phase training and data augmentation on the validation set: “Vggskcct_kdmt” is the same as that in Table 4 and 5. “Two-phase training” and “Two-phase training with ICT” indicate updating the parameters of the “Pre-trained” model and not only updating parameters but also using ICT, in the second phase, respectively.
Table 7. Comparison of two-phase training and data augmentation on the public evaluation set: “Vggskcct_kdmt” is the same as that in Table 4 and 5. “Two-phase training” and “Two-phase training with ICT” indicate updating the parameters of the “Pre-trained” model and not only updating parameters but also using ICT, in the second phase, respectively.