Figures & data
Figure 1. Our table-top object manipulation scenario in the simulation environment: the NICO robot is moving the blue cube on the table. The performed action is labeled as “slide blue quickly.” Our approach can translate from language to action and vice versa; i.e., we perform actions that are described in language and also describe the given actions using language.

Figure 2. The architecture of the PTAE model. The inputs are a language description (incl. a task signal) and a sequence of visual features (extracted using the channel-separated convolutional autoencoder) and joint values, while the outputs are a description and a sequence of joint values. Language encoder can be an LSTM, the BERT Base model (Devlin et al. Citation2019), or the descriptions can be directly passed to the transformer word by word. The action encoder can be an LSTM or the action sequence can be passed directly to the transformer. Both decoders are LSTMs – we show unfolded versions of the LSTMs. The bottleneck, where the two streams are connected, is based on the Crossmodal Transformer. h is the shared representation vector.
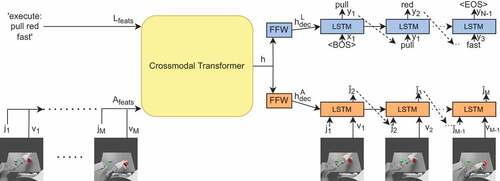
Figure 3. The architecture of the Crossmodal Transformer: Language features are embedded and used as the query vector (Q), whereas the embedded action features are used as the key (K) and value (V) vectors. The positional embedding is applied only to the language features. The multi-head attention (MHA) involves the Q-, K- and V-specific feedforward (FFW) and scaled dot product attention layer following the original Transformer architecture. The multiple heads are then concatenated and fed to the final FFW, which outputs the common hidden representation vector h.
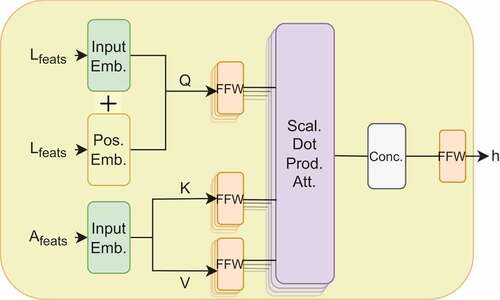
Figure 4. Sentence accuracy for action-to-language translation on the test set wrt. supervised training iterations. Supervised training refers to crossmodal translation cases “describe” and “execute.” The two crossmodal signals receive the same number of iterations between them out of the supervised iterations. We report the results for 1%, 2%, 10%, 20%, 50%, and 66.6% (the regular training case) crossmodal (supervised) iterations. These percentages correspond to the fraction of supervised training iterations for PGAE and PTAE. Note that the 100% case is not shown here, since the models need unsupervised iterations (unimodal repeat signals) to be able to perform the “repeat language” and “repeat action” tasks.
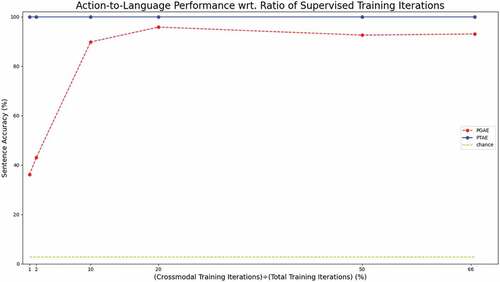
Figure 5. Sentence accuracy for action-to-language translation on the test set wrt. supervised training samples. Supervised training refers to crossmodal translation cases “describe” and “execute.” We limit the number of training samples for the supervised tasks. We report the results for the 1%, 2%, 5% 10%, 20%, 50%, and 66.6% cases as well as the 100% regular training case. These percentages correspond to the fraction of training samples used exclusively for the supervised training for PGAE and PTAE, i.e., both “execute” and “describe” signals are trained with only a limited number of samples corresponding to the percentages.
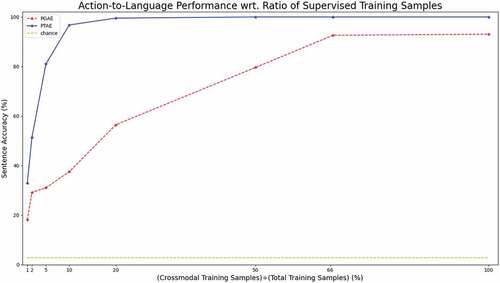
Figure 6. Joint value prediction error in language-to-action translation on the test set wrt. supervised training samples. Supervised training refers to crossmodal translation cases “describe” and “execute.” We limit the number of training samples for the supervised tasks. We report the results for the 1%, 2%, 5% 10%, 20%, 50%, and 66.6% cases as well as the 100% regular training case. These percentages correspond to the fraction of training samples used exclusively for the supervised training for PGAE and PTAE. “execute” and “describe” translations are shown the same limited number of samples.
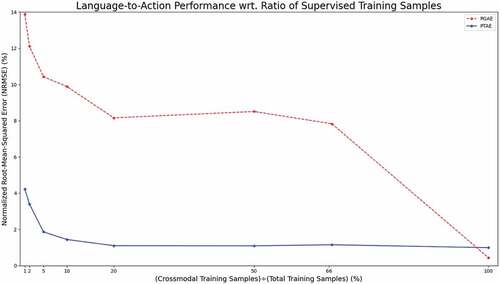
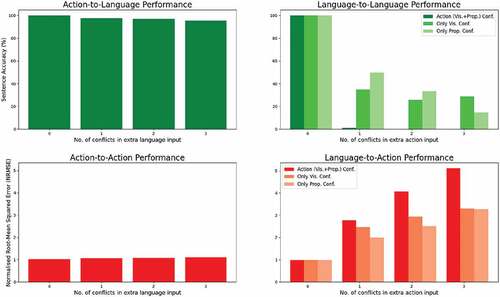
Figure 7. Model performance on the test set wrt. no. of conflicts introduced in the extra input. For action-to-language and language-to-language (the top row), we show the predicted sentence accuracies. For language-to-action and action-to-action, we show the normalized root-mean-squared error (NRMSE) for predicted joint values. The modality in which the conflicts are introduced is given in the x-axis. For each signal, we add extra conflicting inputs either in the action or language input. When the conflict is introduced in action, we also test having the conflict only in the vision and only in the proprioception submodality - in this case, the other submodality has the matching input.