
Figures & data
Figure 1. The composition of the modules to represent and learn different parts of an advection-diffusion equation. Red lines indicate gradient flow during training and retrospective inference. Figure from Karlbauer et al. (Citation2022).
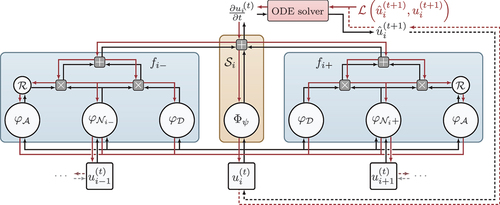
Table 1. Comparison of the training error, test error, and the learnt BC values of all models. For each trial, the average results over 5 repeats are presented. Burgers’ dataset BC and Allen–Cahn dataset BC
.
Figure 2. Convergence of the boundary conditions and their gradients during training in FINN. The dataset for Burgers’ on the first row. On the second row for Allen–Cahn with
.
![Figure 2. Convergence of the boundary conditions and their gradients during training in FINN. The dataset BC=[1.0,−1.0] for Burgers’ on the first row. On the second row for Allen–Cahn with BC=[−6.0,6.0]..](/cms/asset/4d9f62f7-056a-4f6a-ab71-95ef88e465fe/uaai_a_2204261_f0002_oc.jpg)
Table 2. Comparison of multi-BC training and prediction errors along with the inferred BC values by the corresponding models. The experiments were repeated 5 times for each trial and the average results are presented. Burgers’ dataset BC and Allen–Cahn dataset BC
.
Figure 3. Average prediction errors of 5 multi-BC trained models for Allen–Cahn-Equation. As the BC-range grows larger, the error and the standard deviation (SD) increases. This phenomenon applies to FINN as well (SD range from to
). However, due to the scale of the plot, it is not possible to see this shift.
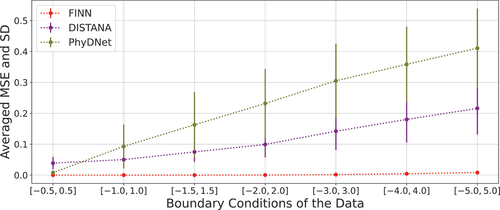
Figure 4. The predictions of the multi-BC trained Allen–Cahn dynamics after inference. First row shows the models’ predictions over space and time. Areas below the red line are the 30 simulation steps that were used for inference and filled with data for visualization. Test error is computed only with the upper area. Second row shows the predictions over and
, i.e.,
in the last simulation step. Data is represented by the red dots and the predictions by the blue line. Best models are used for the plots.
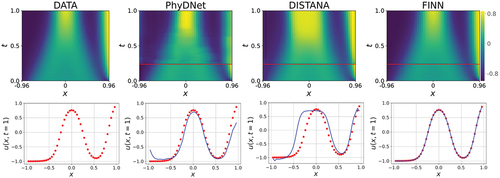
Figure 5. The predictions of the single-BC trained Burgers’ dynamics after inference. First row shows the models’ predictions over space and time. Areas below the red line are the 30 simulation steps that were used for inference and filled with data for visualization. Test error is computed only with the upper area. Second row shows the predictions over and
, i.e.,
in the last simulation step. Data is represented by the red dots and the predictions by the blue line. Best models are used for the plots.
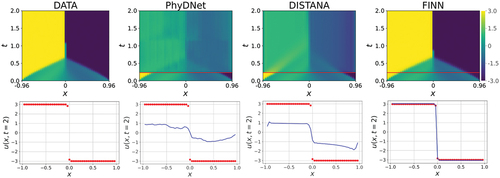
Table 3. Comparison of single-BC training and prediction errors along with the inferred BC values by the corresponding models. The experiments were repeated 5 times for each trial and the average results are presented. Burgers’ dataset BC and Allen–Cahn dataset BC
.
Figure 6. Active tuning algorithm. corresponds to the retrospective tuning horizon as stated in Otte, Karlbauer, and Butz (Citation2020). The blue column represents the retrospective initial state and the BCs, which are optimized depending on the gradient-signal. The red areas in the middle of the columns are so-called seen areas from which the models receive information and that provide the error signal. The brown areas are called unseen area and models need to reconstruct the equation, i.e., the
values for the entire domain. Black and red arrows represent the model forward and backward passes, respectively. The gradient information (red arrows) is used to infer the BCs.
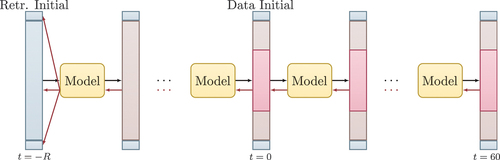
Figure 7. Retrospective state inference. The red lines at show the ground truth, i.e., the initial state of the dataset. The brownish faces indicate the seen area. Best models are used.
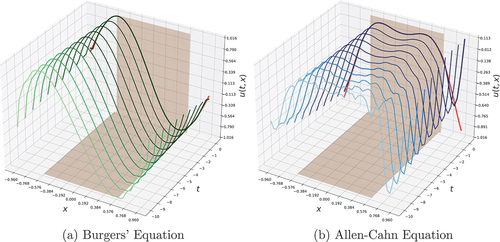
Figure 8. Initial state inference. Figures depict the initial state prediction of the models for trials. Each light blue line corresponds to one trial. Dataset BC are [1.5, −1.5]. BC-Errors are computed as root mean squared error and are depicted as red lines showing the deviation from the red dots which represent the actual BC values. The plots correspond to the results reported in .
![Figure 8. Initial state inference. Figures depict the initial state prediction of the models for 5 trials. Each light blue line corresponds to one trial. Dataset BC are [1.5, −1.5]. BC-Errors are computed as root mean squared error and are depicted as red lines showing the deviation from the red dots which represent the actual BC values. The plots correspond to the results reported in Table 4.](/cms/asset/26956f28-6175-41f1-8729-f510310e0e18/uaai_a_2204261_f0008_oc.jpg)
Table 4. Comparison of seen domain and whole-domain prediction errors along with the inferred BC values by the corresponding models. The experiments were repeated times for each trial and the average results are presented. Burgers’ dataset BC
and Allen–Cahn dataset BC
. R =
. As 60 data points were used in this experiment (compared to 30 time steps in the previous ones) an error comparison with the other experiments is not possible.
Figure 9. FINN prediction with noisy data. The red dots show the data and the blue line is the prediction of the model. The area between brown lines indicates the seen area. Best models are used.
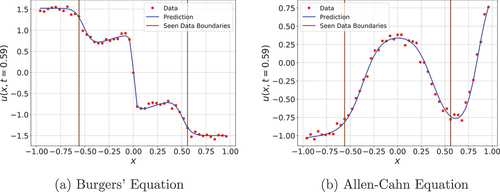
Table 5. Comparison of seen domain and whole-domain prediction errors along with the inferred BC values by the corresponding models inferred on noisy data. The experiments were repeated times for each trial and the average results are presented. Burgers’ dataset BC
and Allen–Cahn dataset BC
. R =
. As 80 data points were used in this experiment (compared to 30 and 60 time steps in the previous ones) a direct error comparison with the other experiments is not possible.