
Figures & data
Figure 1. The first phrase of two variants of a folk song, notated at different octaves and in different meters. Similarity comparison of the pitches and durations might lead to no agreement between the two variants, even though they are clearly very related.

Figure 2. An example for two melodies from the same tune family with annotations. The first phrase of each melody is labelled with the same letter (A), but different numbers, indicating that the phrases are ‘related but varied’, the second phrase is labelled B0 in both melodies, indicating that the phrases are ‘almost identical’.

Table 1. An overview of the measures for music similarity compared in this research, with information on the authors and year of the related publication.
Figure 3. The first two phrases of a melody from the tune family ‘Daar ging een heer 1’, with the values of the Haar wavelet coefficient underneath.

Table 2. The glass ceiling (top), or the annotators’ agreement with the majority vote, and the majority vote agreement of the baselines (bottom), assuming every note (always) or no note (never) to be an occurrence. We report Matthews’ correlation coefficient () for the overall agreement, and the associated sensitivity (SEN), specificity (SPC), positive and negative predictive values (PPV, NPV).
Figure 4. The ROC curves for the various similarity measures, showing the increase of false positive rate against the increase of the true positive rate, with the threshold as parameter.
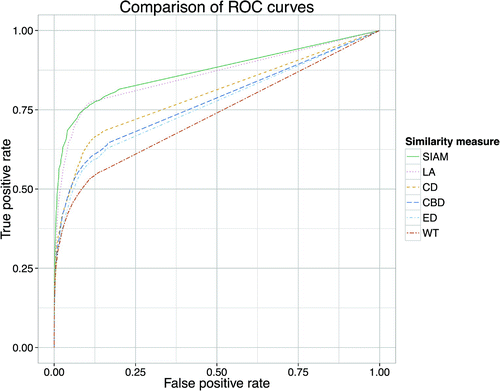
Table 3. Results of the compared similarity measures: area under the ROC curve (AUC), maximal correlation coefficient with associated sensitivity (SEN), specificity (SPC), positive and negative predictive values (PPV, NPV).
Figure 5. The area under the ROC curves (AUC) of the similarity measures for different music representations: pitch interval (PI), pitch (P), duration weighted (DW), pitch adjusted (PA), pitch adjusted and duration weighted (PADW), metrically adjusted (DA), hand adjusted (HA), and pitch/onset (PO). For wavelet transform (WT) and structure induction (SIAM), not all music representations are applicable, and only SIAM uses the pitch/onset representation.
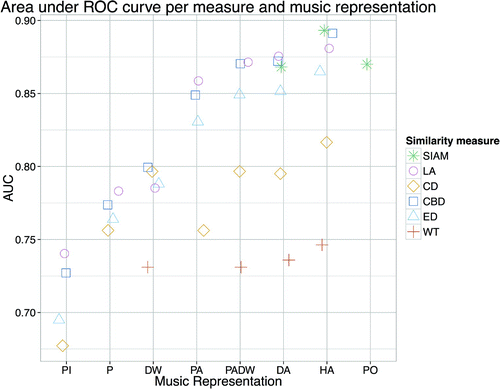
Figure 6. The ROC curves for the various similarity measures with optimised music representations, showing the increase of false positive rate against the increase of the true positive rate, with the threshold as parameter.
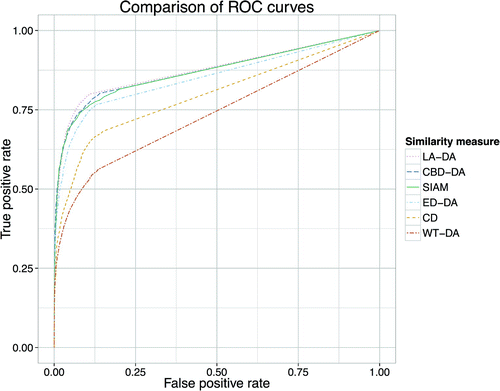
Table 4. Results of the similarity measures with optimised music representations: area under the ROC curve (AUC), maximal correlation coefficient with associated sensitivity (SEN), specificity (SPC), positive and negative predictive values (PPV, NPV).
Table 5. Results of a combined similarity measure from SIAM, CBD-DA and LA-DA, represented by the maximal correlation coefficient with associated sensitivity (SEN), specificity (SPC), positive and negative predictive values (PPV, NPV).
Figure 7. The thresholds resulting from ‘leave one tune family out’ optimisation. The black stripes indicate the threshold of the optimisation of the full data-set. All of the measures’ thresholds are close to each other.
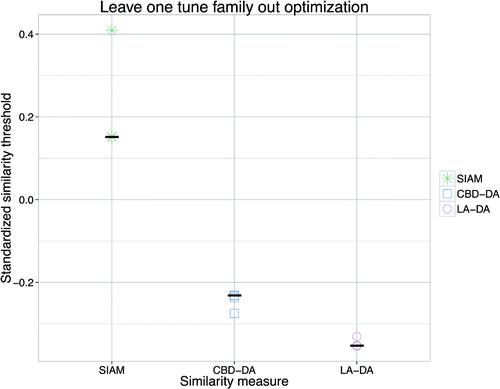
Figure 8. The agreement (in ) of the three similarity measures and the annotators with the majority vote, evaluated separately for each tune family. The similarity measures show more variation than the annotators, even though there are also some remarkable low outliers for the annotators.
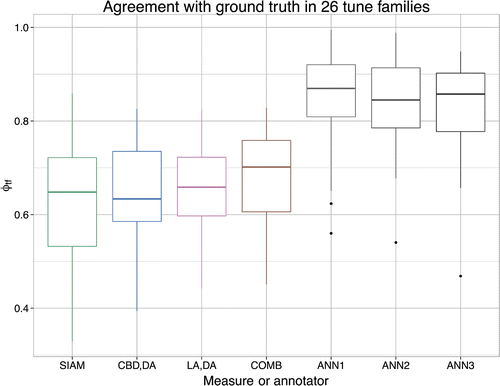
Table A1. Area under ROC curve, maximal correlation coefficient with associated sensitivity (SEN), specificity (SPC), positive and negative predictive values (PPV, NPV) for all similarity measures in all applicable music representations.