
Figures & data
Table 1. Summary of the literature on the decision-making for product lifecycle management.
Figure 1. AI for product lifecycle management.
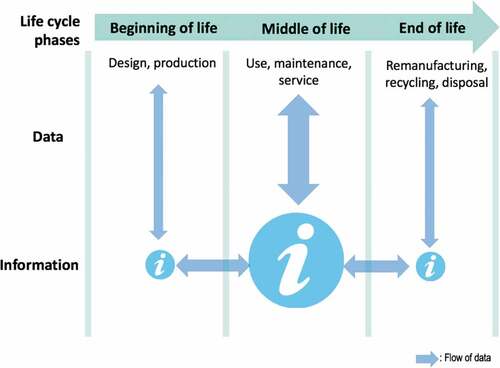
Figure 2. The simplified product lifecycle from a maintenance perspective.
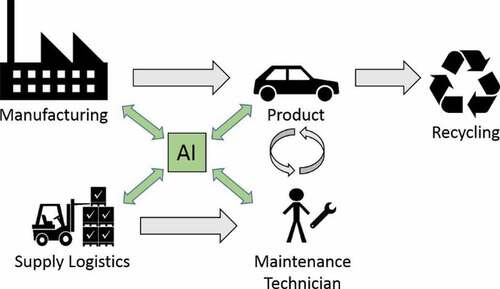
Figure 3. Some RL scenarios.
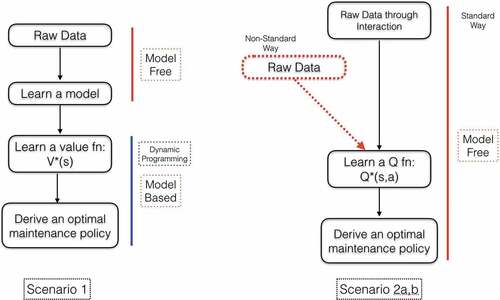
Figure 4. Example 1: Hidden failure rate for Product-X.
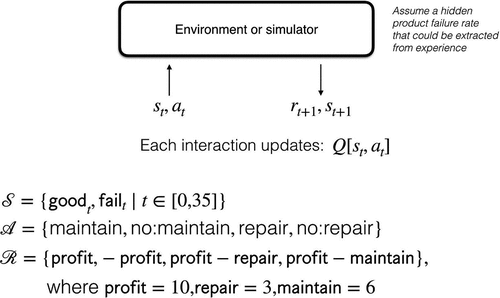
Figure 5. Example 1: the simulation model.
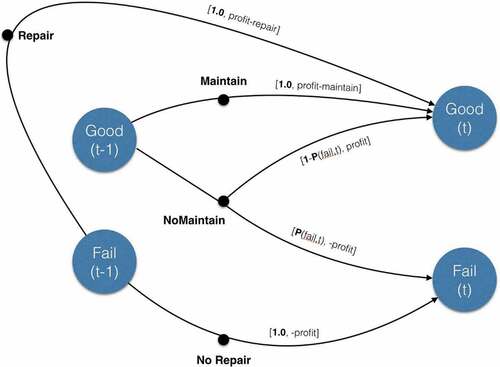
Figure 6. Example 1: optimal policy.
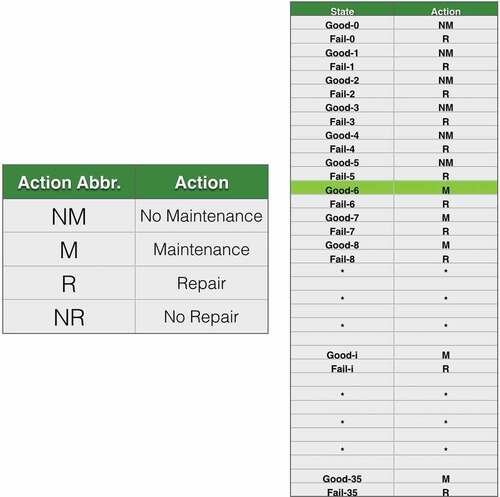
Figure 7. Example 1: maintenance crossover.
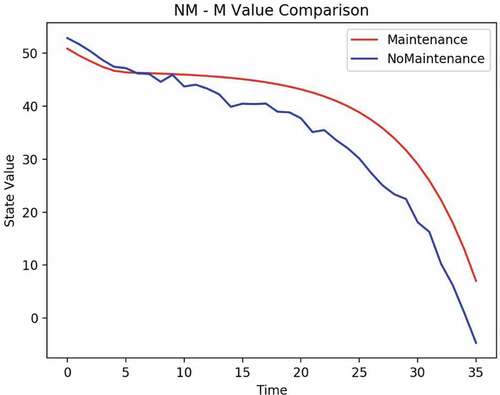
Figure 8. Example 1: reward validation.
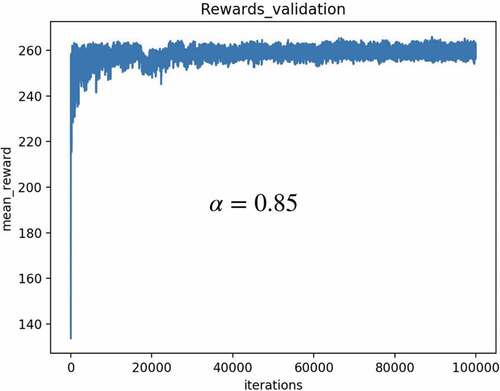
Figure 9. Example 1: mean rewards.
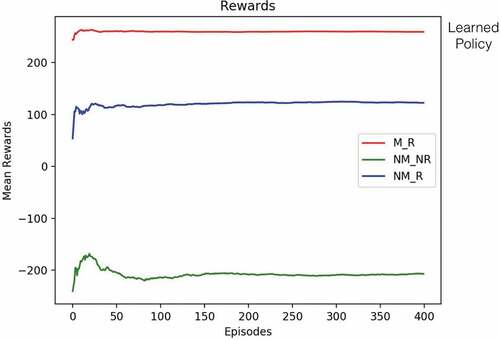
Figure 10. Example 1: MTTF.
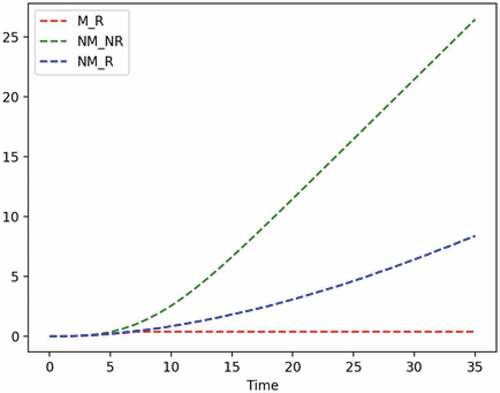
Figure 11. Example 2: hidden failure rate with energy cost.
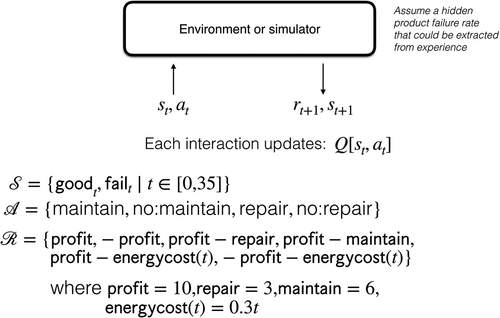
Figure 12. Example 2: the simulation model.
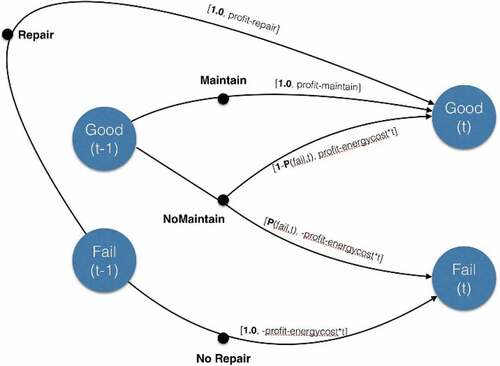
Figure 13. Example 2: optimal policy.
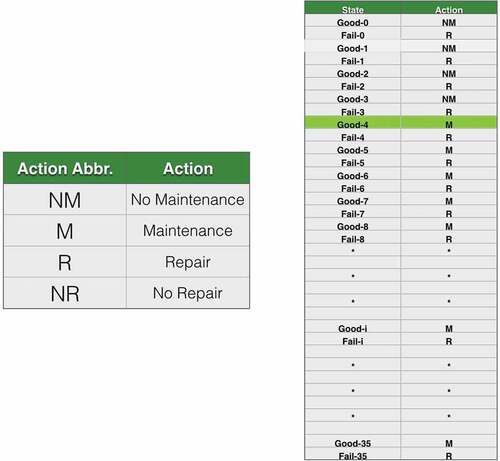
Figure 14. Example 2: maintenance crossover.
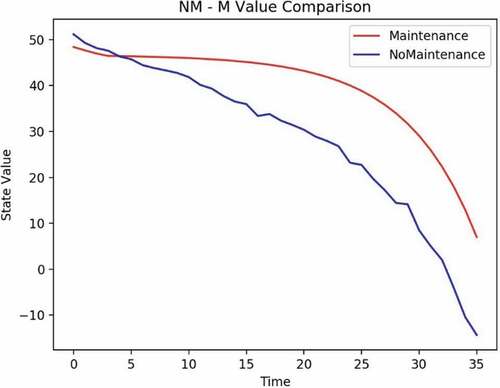
Figure 15. Example 2: reward validation.
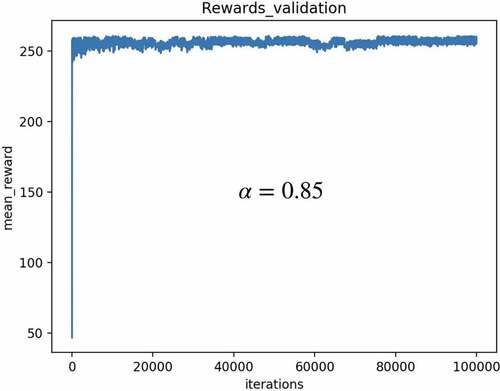
Figure 16. Example 2: mean rewards.
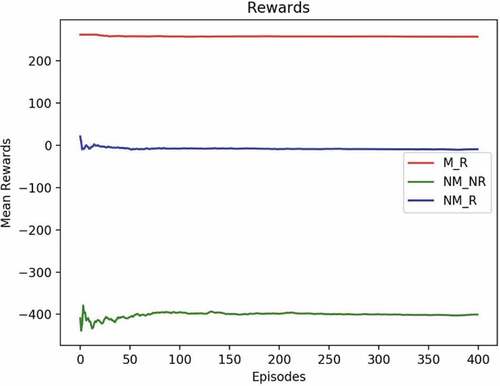
Figure 17. Example 2: MTTF.
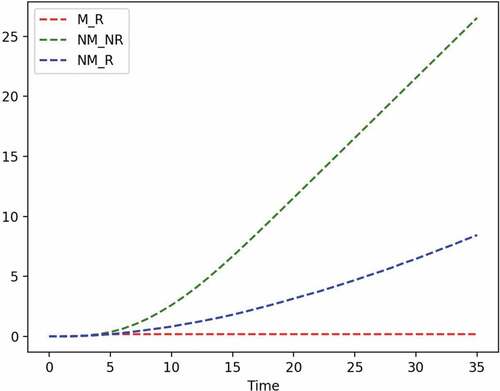
Figure 18. Comparison of learned and simulated failure rate.
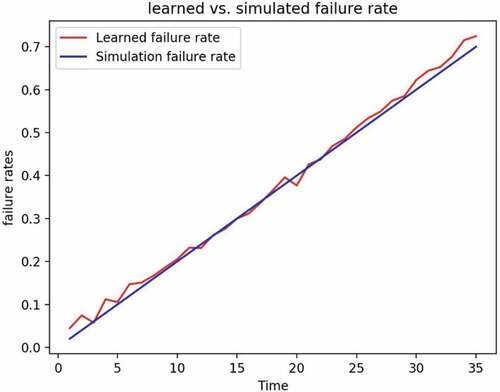
Figure 19. RL extends learning to simultaneously solving a decision problem. Given just a problem state xt and a reward for that state rt, the agent will try to learn how to maximise the profits or minimise the costs over time. This can be visualised as a Bayesian network augmented with action nodes, where at each point in time t it has to make a decision based on the history of observed states and rewards.
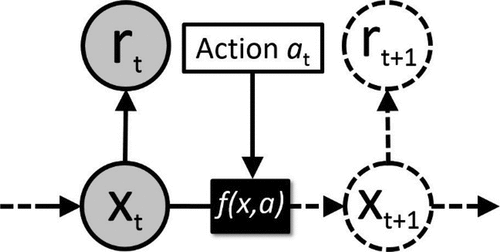
Figure A1. RL overview.
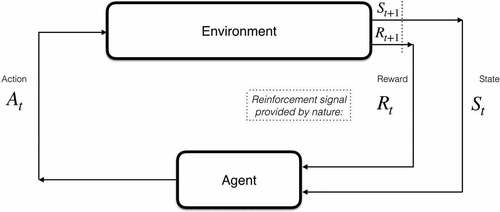
Figure B1. Q-Learning using interaction.

Figure B2. Q-Learning using raw data.

Figure C1. Months 0–9.

Figure C2. Months 10–19.

Figure C3. Months 20–29.

Figure C4. Months 30–35.
