Figures & data
Figure 1. (a) The RFN architecture integrates an autoassociative processing constraint into a standard backpropagation network (large arrows represent full connectivity with modifiable weights). Here the emphasis is on the learning algorithm. The network is shown learning a pattern P: Input → Target. (b) An equivalent visualization of the RFN architecture emphasizing the input–hidden layer reverberation. It is crucial to note that the updating of the hidden-to-input weights depends not only on the autoassociative error between the original input and the reverberated input, but also on the difference between the network's actual output and the target. As above, the network is shown learning a pattern, P: Input → Target.
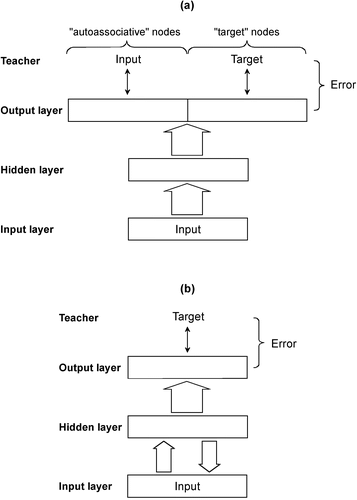
Figure 2. A standard SRN network that is designed to learn a sequence S(0), S(1), … , S(t), … , S(n). At each time t, the relation between item S(t) and the associated target item S(t + 1) is learned along with the context H(t − 1), a copy of the hidden layer activation from time t − 1 when the network was learning the previous association S(t − 1) → S(t).
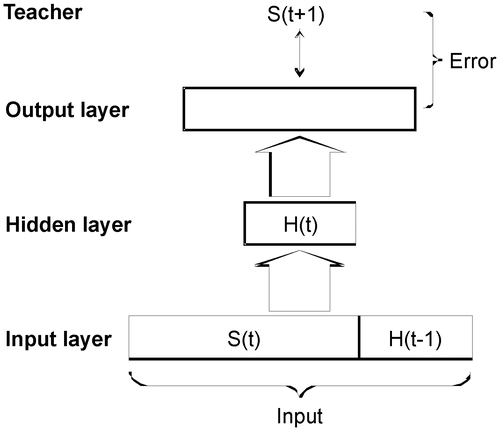
Figure 3. A reverberating SRN. This architecture can also be visualized as in to emphasize the input reverberation between the input and hidden layer.
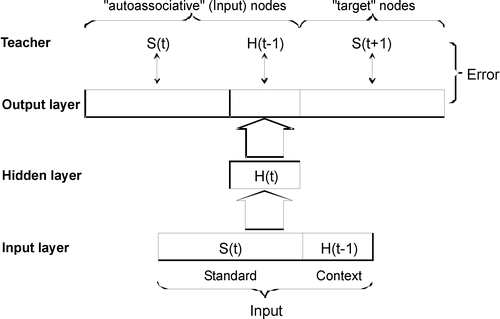
Figure 4. (a) Learning of sequence B (after having previously learned sequence A). By 450 epochs (an epoch corresponds to one pass through the entire sequence), sequence B has been completely learned. Note that it is more difficult to learn the two ‘ambiguous’ target items, S(2) and S(6). (b) The number of incorrect units for sequence A during learning of sequence B. After 450 epochs, the SRN has, for all intents and purposes, completely forgotten the previously learned sequence A. (Note that for the sake of readability of the graphs, the learning epochs increase from left to right in the second graph in the direction of the arrow.)
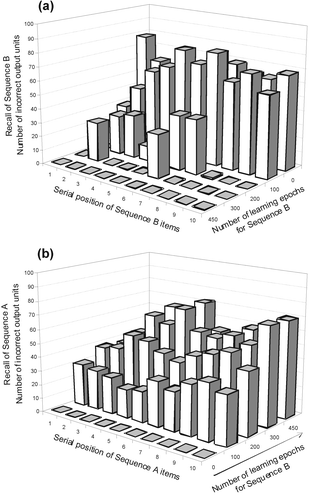
Figure 5. Recall performance for the first sequence A, once the second sequence B is completely learned in a SRN, with (a) and without (b) the pseudo-sequences refreshing. Whatever the learning criterion may be, it appears clearly that refreshing by pseudo-sequences in no way reduces catastrophic forgetting.
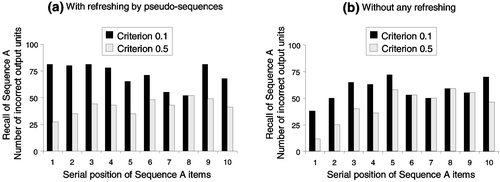
Figure 6. Recall performance for sequences B and A during learning of sequence B by a dual-network RSRN. (a) By 400 epochs, the second sequence B has been completely learned. Note that it is more difficult to learn the two ‘ambiguous’ target items. (b) The previously learned sequence A shows virtually no forgetting. Catastrophic forgetting of the previously learned sequence A has been completely overcome.
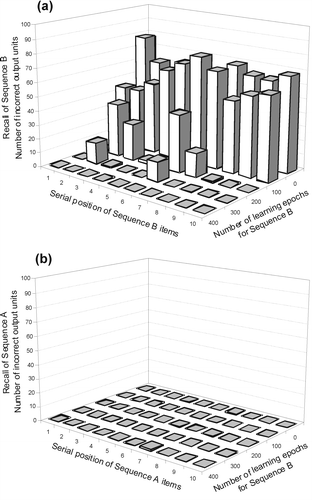
Figure 7. Recall performance for the whole sequence in the course of learning of its second sub-sequence D within a RSRN dual-architecture. By 300 epochs, the second sub-sequence D has been completely learned. The previously learned sub-sequence C shows no forgetting and the whole sequence of 20 ordered items can be perfectly reproduced when starting only from the initializing item S(0) and the neutral context. The two separately learned sub-sequences C and D were correctly linked.
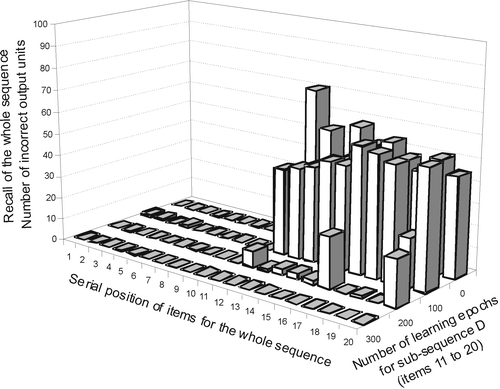
Table 1. Forgetting of sequence A after complete learning of sequence B using different self-refreshing procedures.
Figure 8. Recall performance for the previously learned SOC1 sequence during learning of a second SOC2 sequence (completely learned by 450 epochs). The two SOCs are made up of 13 items and, as in previous simulations, the item in position 0 is not shown because it is used only to initialize sequence learning and recall. (a) Without self-refreshing, catastrophic forgetting is severe. (b) With self-refreshing, the previously learned SOC1 sequence does not show any catastrophic forgetting during SOC2 learning.
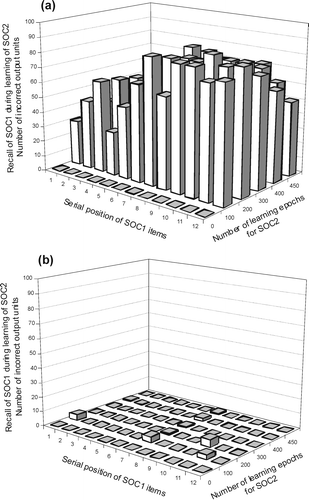
Figure 9. Recall performance of the new sequence and of the previously learned sequences during learning of the new sequence. Vertical bars denote standard errors.
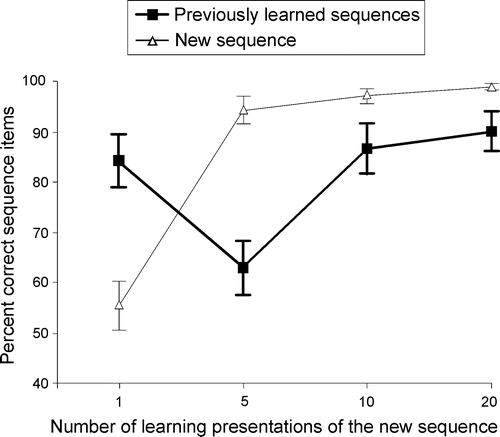
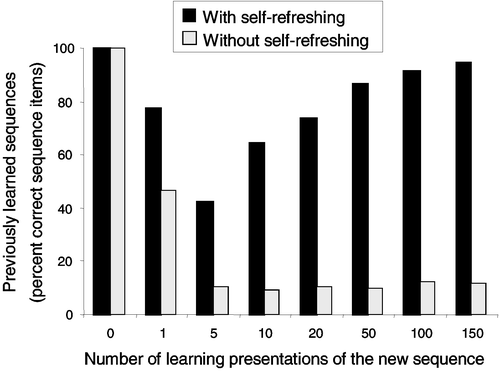
Figure 10. Recall performance, with and without the self-refreshing mechanism at work, of the previously learned sequences during learning of the new sequence (which is completed after 150 presentations). Without refreshing, there is clearly catastrophic forgetting of the previously learned sequences. With refreshing, however, the learning curve exhibits, as for humans, an initial drop and subsequent rise in recall performance.