
Figures & data
Figure 1. Our proposed lightweight multi-modal free-space detection network. An encoder-decoder architecture is employed. The input of the network is a pair of RGB and depth images. They are processed by the ResNets (K. He et al., Citation2016) encoders. The multi-modal fusion strategy is the concatenation of the feature maps. A U-shape segmentation decoder (Ronneberger et al., Citation2015) is propagated for the final prediction.
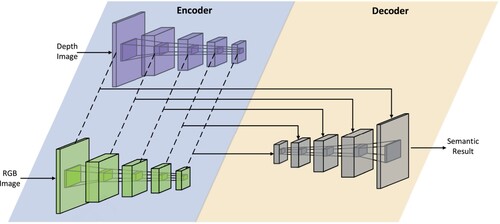
Figure 2. Replacing the convolution with
convolutions.
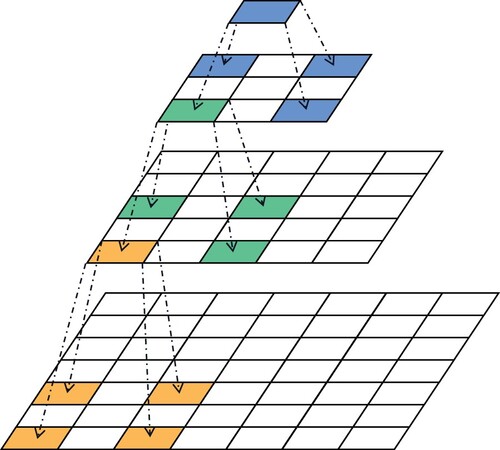
Figure 3. (a) Detail of the optimised accelerating convolution layer. (b) Detail of the dimensionality reduction for large features.
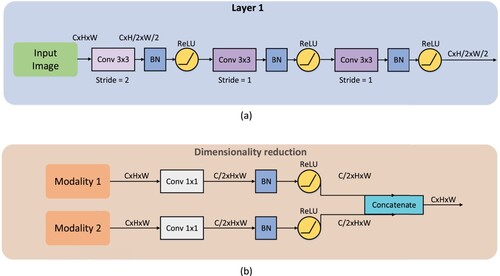
Figure 4. Block diagram of hardware architecture.
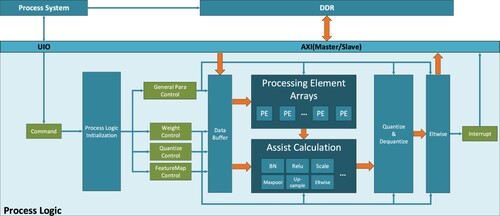
Figure 5. (a) convolution unit. (b)
convolution unit.
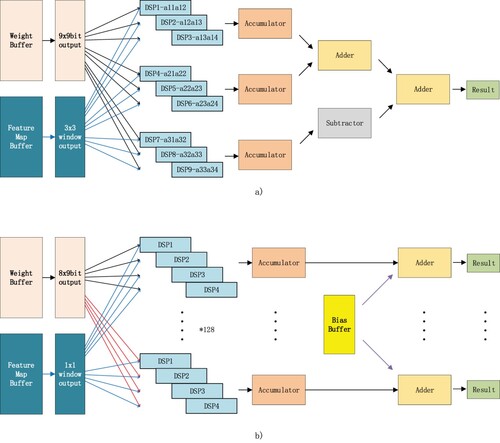
Table 1. Performance on Kitti-road compared to other methods(GPU).
Table 2. Pruned multi-modal unet-resnet50 on Kitti-road.
Figure 6. Examples of detection results by FPGA.

Table 3. 8-Bit quantised results on FPGA.
Table 4. Resource usage on the FPGA implementation.
Table 5. Performance evaluation of FPGA inference.