
Figures & data
Figure 1. Transition from a state with the maximum potentiality to one with minimum potentiality.
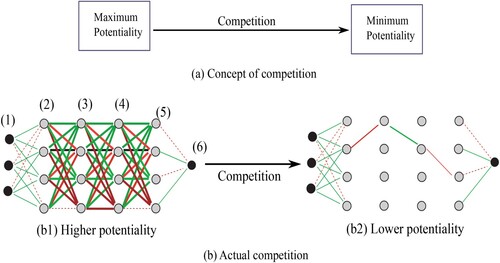
Figure 2. Conventional computing (a) and competitive computation (b), composed of five computational procedures: potentiality max, potentiality min, cost max, cost min, and error min.
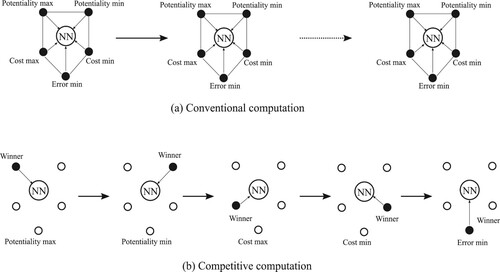
Figure 3. Actual network configurations, corresponding to five computation procedures: potentiality max, potentiality min, cost max, cost min, and error minimisation in Figure .
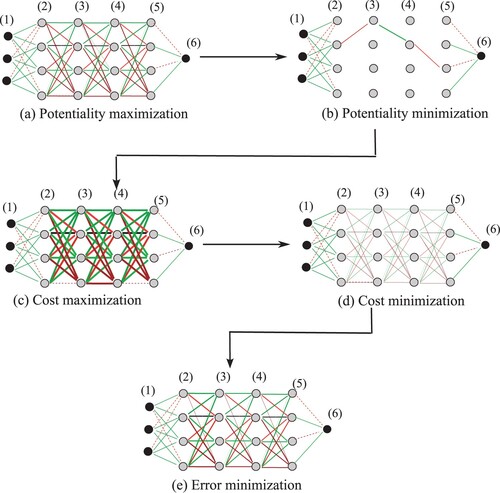
Figure 4. Concept of three computational modules used in this paper: cost-forced potentiality maximisation (cost+potentiality max), cost minimisation, and cost-forced potentiality minimisation (cost+potentiality min).
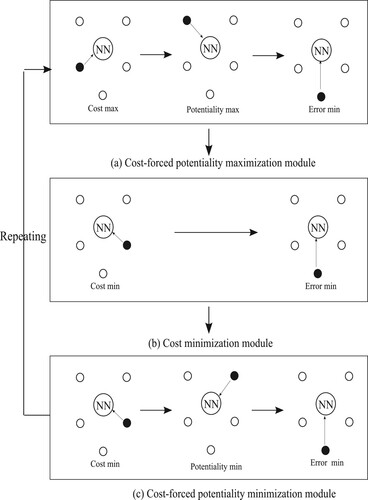
Figure 5. Actual network configurations of three computational modules, corresponding to the concepts in Figure .
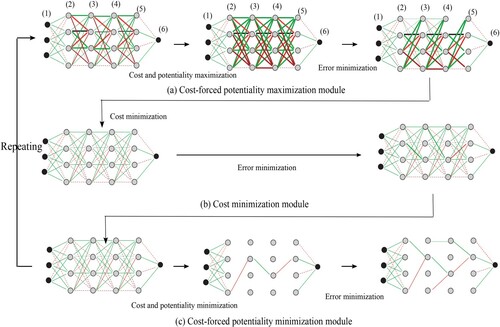
Figure 6. Concept of compression for collective weights by syntagmatic (b) and paradigmatic (c) compression.
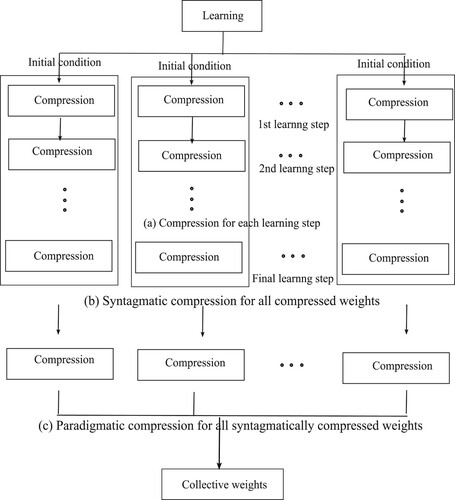
Figure 7. Compression from a multi-layered network to the corresponding simplest network in full (a) and partial (b) way.
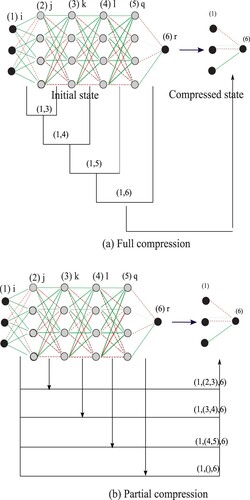
Figure 8. Simple (a), syntagmatic (b), and paradigmatic (c) compression to produce the final collective weights (d).
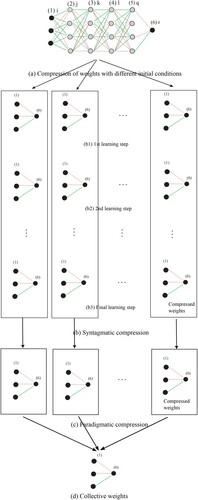
Figure 9. Cost-forced potentiality max (a), cost min (b), cost-forced potentiality min (c), and final collective weights with an important input representing “who” (d) for the L2 data set.
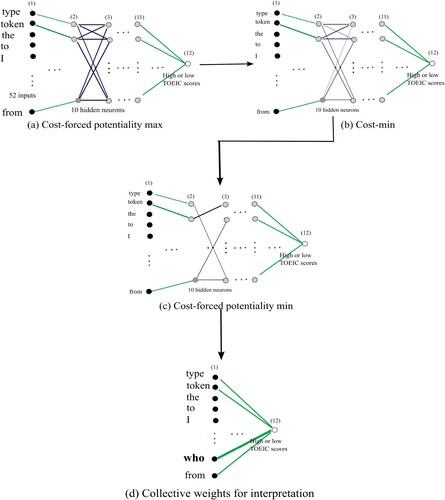
Figure 10. Internal potentiality (left) and cost (right) as a function of the number of steps when the conventional method was used (a) and when the parameter θ was 1.3 (b), 1.0 (c), and 1.5 (d) for the L2 data set.
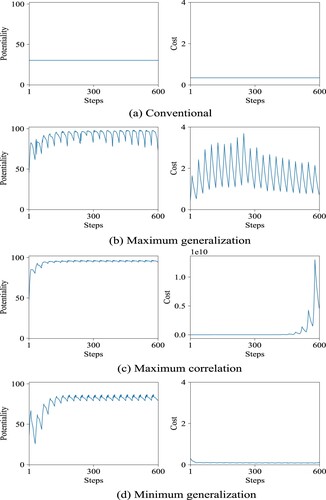
Figure 11. Correlation coefficients between inputs and targets of the original data set (a) and collective weights by the conventional (b) and the impartial methods (c)–(e) with different performance values for the L2 data set.
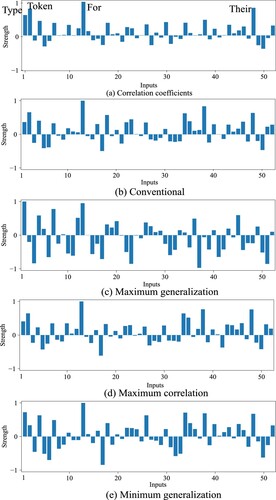
Figure 12. Relative collective weights, computed by dividing the absolute collective weights by the corresponding absolute correlation coefficients by the conventional (a) and three impartial methods (b)–(d) for the L2 data set.
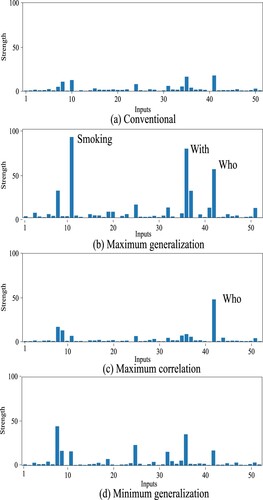
Figure 13. Partial collective weights from the first hidden layer to the tenth hidden layer by the conventional (a) and potentiality method (b)–(d) for the L2 data set.
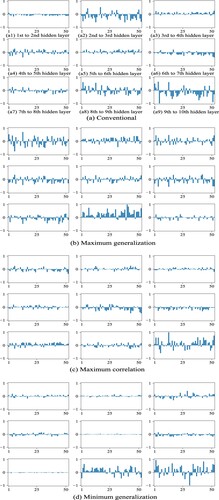
Table 1. Summary of experimental results on average correlation coefficients and generalisation performance for the L2 data set.
Data availability statement
The data set was taken from the data sets of the research project of ICNALE: the international corpus network of Asian learners of English; a collection of controlled essays and speeches produced by learners of English in 10 countries and areas in Asia (https://language.sakura.ne.jp/icnale/). The files on Japanese English learners: W_JPN_PTJB1_2.txt and W_JPN_SMK_B1.txt were taken from the project home page.