
Figures & data
Figure 1. The framework of multi-level feature cross-fusion for SER.
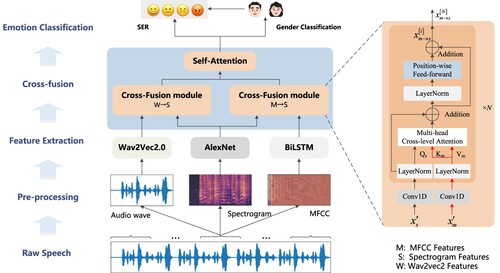
Figure 2. The structure of multi-head cross-level attention for the cross-fusion module.
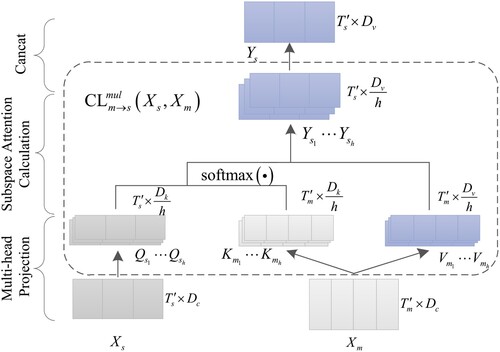
Table 1. The shape settings of the input and output of each module of cross-fusion.
Table 2. Performance of different methods for emotion recognition on the dataset IEMOCAP using 5-fold and 10-fold cross-validation. The scores of WA and UA are reported.
Figure 3. Final normalised confusion matrix: comparison of baseline's reproduced results and experimental results of the proposed fusion model under 10-fold cross-validation.
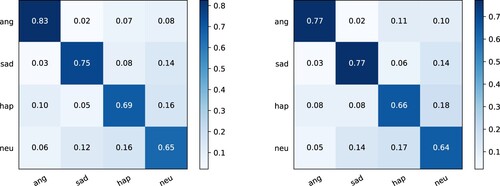
Table 3. The classification report of Cross-Fusion evaluated on IEMOCAP.
Table 4. The table shows the results of the ablation study of cross-fusion on our model. The best results are highlighted in bold font.
Table 5. The table displays the emotion recognition accuracy attained by our model under varying initial values of the parameter α.