
Figures & data
Figure 1. Overall framework of the proposed approach for river network selection.
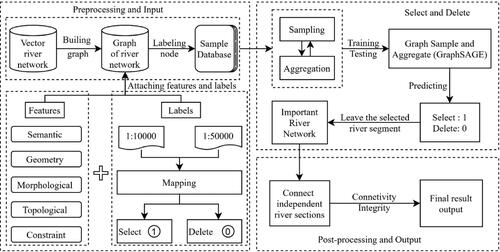
Figure 2. Graph modelling of a river network. (a) River network abstract dual graph representation; (b) primal river network; and (c) river network dual graph.
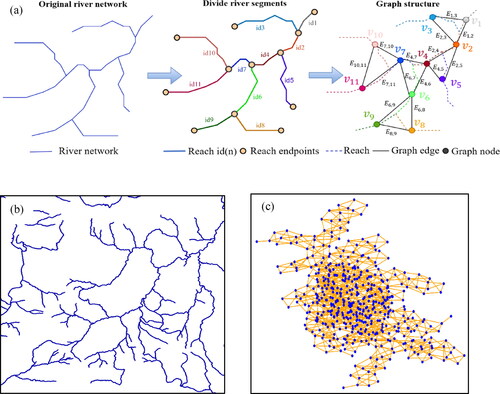
Figure 3. Example of a river network matching result. (a) 1:10,000 scale river network data; (b) 1:50,000 scale river network data; and (c) matching result.
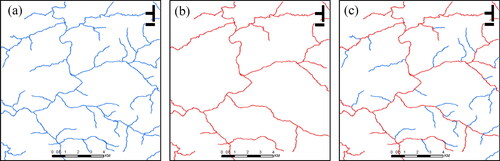
Table 1. Graph node characteristics.
Figure 4. River network selection sample coding. (a) Sample initial features; and (b) sample encoded features.
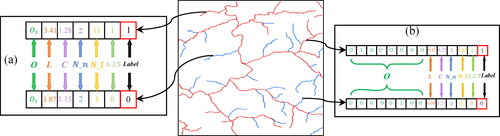
Figure 5. River network neighbour sampling and aggregation. (a) Sample neighbourhood; (b) aggregate feature information from neighbours; and (c) categorisation using aggregated information.
Figure 6. Graph classification model based on GraphSAGE, which contains two convolutional layers (SAGEConv): a fully connected layer (linear) and a normalised exponential layer (Softmax).
Figure 7. Experimental data: (a) 1:10,000 and 1:50,000 overlays; (b) 1:10,000 partial area; and (c) 1:50,000 partial area.
Figure 8. Loss value and accuracy curves of neural network models in different graphs. (a) Loss value change curve of different models; and (b) validation dataset accuracy curve of different models.
Figure 9. Influence of the number of node features on accuracy.
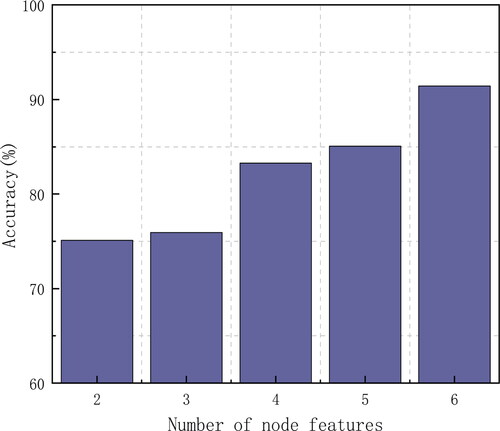
Figure 10. Influence of different hyperparameters on the accuracy of the model.
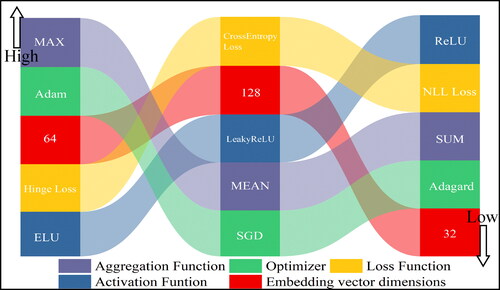
Figure 11. Accuracy and loss values of different depth models.
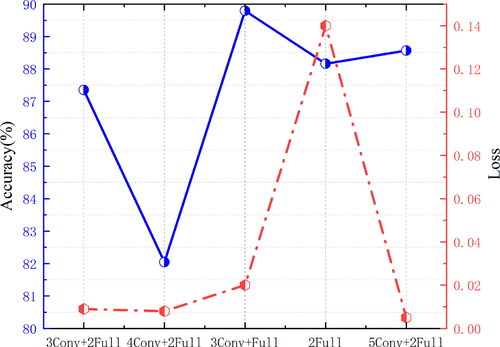
Table 2. Test set classification result statistics.
Figure 12. Accuracy of the compared methods.
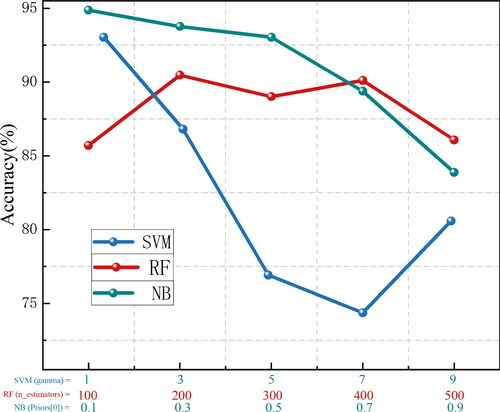
Table 3. Comparison of classification accuracy among similar algorithms.
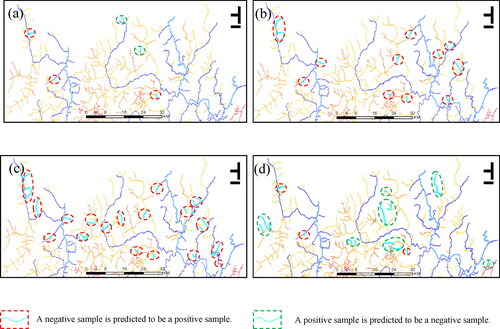
Figure 13. Incorrect results predicted by different classification methods. (a) Misclassified river segment by GraphSAGE. (b) Misclassified river segment by NB. (c) Misclassified river segment by RF. (d) Misclassified river segment by SVM.
Data availability statement
The data and codes that support the findings of this study are available in Figshare at https://doi.org/10.6084/m9.figshare.22793993.v1