
Figures & data
Figure 1. Marginal density of the Dirichlet-horseshoe (DHS) in comparison with those of the double exponential (DE), horseshoe (HS), Dirichlet-Laplace (DL), and regularized horseshoe (RHS) priors.
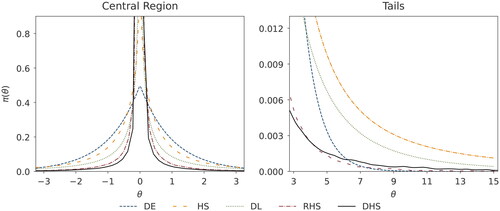
Figure 2. Squared error loss corresponding to the posterior median derived from the normal means problem (Simulation Study I), with a D = 400 dimensional parameter vector for varying signal strengths and sparsity ratios
(left panel) and
(right panel). We abbreviate the considered priors SPSL (spike-and-slab), BAL (Bayesian Adaptive lasso), HS (horseshoe), DL (Dirichlet-Laplace), RHS (regularized horseshoe), and DHS (Dirichlet-horseshoe).
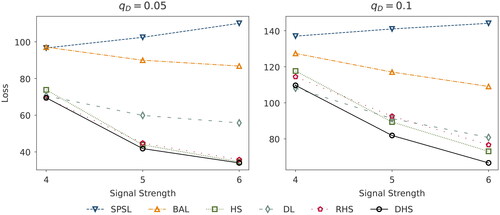
Figure 3. Squared error loss corresponding to the posterior median for different hyperparameter choices ν, derived from the normal means problem with a D = 400 dimensional parameter vector, sparsity ratio and varying signal strengths
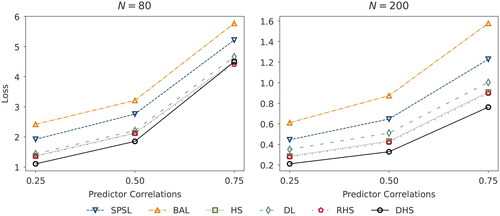
Figure 4. Squared error loss corresponding to the posterior median derived from the multiple regression setting (Simulation Study II) with a D = 100 dimensional parameter vector drawn from a log-normal distribution for varying correlations and observations N = 80 (left panel) and N = 200 (right panel). The design matrix is generated by a multivariate normal distribution with correlated predictors. The parameter vector
has a sparsity ratio of 20%, such that we set 80 of the 100 predictors to 0. We abbreviate the priors SPSL (spike-and-slab), BAL (Bayesian Adaptive lasso), HS (horseshoe), DL (Dirichlet-Laplace), RHS (regularized horseshoe), and DHS (Dirichlet-horseshoe).
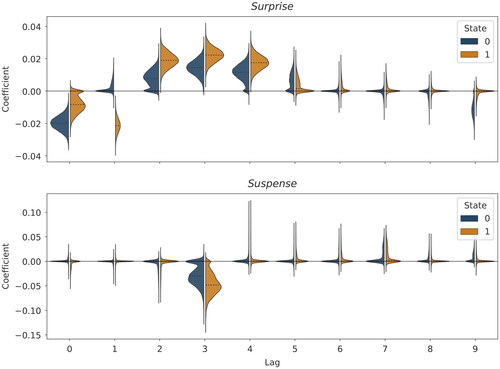
Figure 5. Posterior distributions of the effects of the emotional cues Surprise and Suspense on beer sales, derived from the real-data example. The figure shows posteriors for all lags in both states (negative S = 0 and positive S = 1). The dotted lines indicate the estimated median effect.
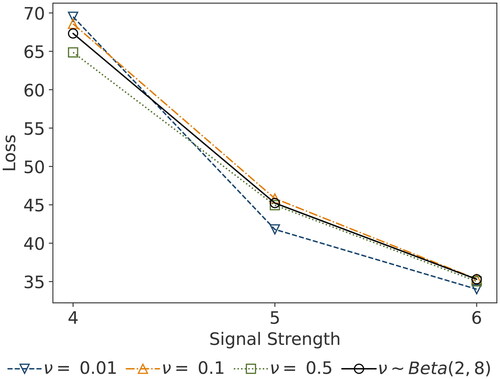
Table 1. This table provides a brief summary of the properties of prior distributions.
Table A1. This table presents performance metrics based on 95% HDIs, averaged across simulation replicates. The measures are derived from the normal means problem (Simulation Study I) with a D = 400 dimensional parameter vector. We perform Ω = 100 replications for all combinations of signals strengths and sparsity ratios
We consider the spike-and-slab (SPSL), Bayesian Adaptive lasso (BAL), horseshoe (HS), Dirichlet-Laplace (DL), regularized horseshoe (RHS), and Dirichlet-horseshoe (DHS) priors.
Table A2. See the descriptive notes to .
Table A3. This table presents performance metrics based on 95% HDIs, averaged across simulation replicates. The measures are derived from the multiple regression setting (Simulation Study II) with a D = 100 dimensional parameter vector drawn from a log-normal distribution. The design matrix is generated by a multivariate normal distribution with correlated predictors. We perform Ω = 100 replications for all combinations of observations and correlations
We consider the spike-and-slab (SPSL), Bayesian Adaptive lasso (BAL), horseshoe (HS), Dirichlet-Laplace (DL), regularized horseshoe (RHS), and Dirichlet-horseshoe (DHS) priors.
Table A4. See the descriptions for .
Data Availability Statement
The data and code that support the findings of this study are openly available at https://zenodo.org/doi/10.5281/zenodo.10707994.