Figures & data
Figure 1. Simulated trajectory of the SWIFT model with attentional zoom lens. To view this figure in colour, please see the online issue of the Journal.
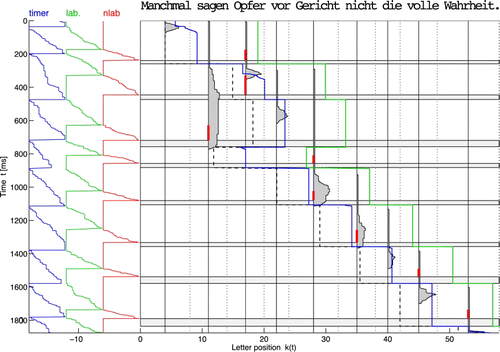
Figure 2. Results from the estimation of model parameters for the normal-SWIFT (triangles) and the shuffled-SWIFT (points) models. A genetic algorithm running for 13,000 generations was used to estimate individual sets of model parameters. This was repeated 10 times with random starting values for normal-SWIFT and for shuffled-SWIFT. Points/triangles show results from individual estimation runs; midlines indicate the average of the parameter estimates across 10 estimation runs; error bars indicate 95% confidence intervals.
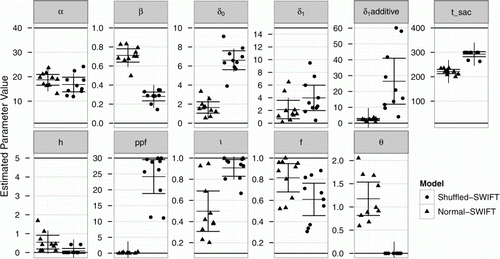
TABLE 1 SWIFT parameters for shuffled and normal text reading
Figure 3. Effects of word length and frequency on different measures of fixation durations and probabilities for model simulations (points) and experimental data (triangles) of shuffled (solid lines) and normal (dashed lines) text reading. Left panel: Mean durations of single, first, and second fixations. Right panel: Mean probabilities for skipping and two fixations, and the mean number of between-word regressions.
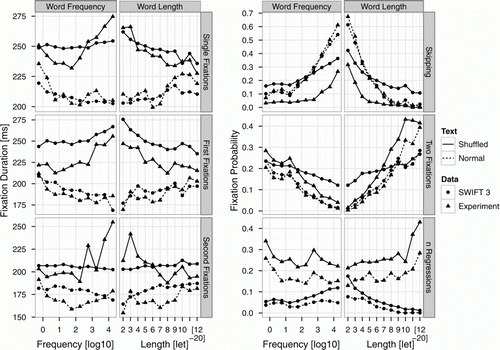
Figure 4. Analysis of distributed processing effects for model simulations of shuffled (triangles & solid lines) and of normal (squares & dotted lines) text and experimental data on shuffled (points & dashed lines) and normal (diamonds & dot-dashed lines) text reading. Top row: Average single fixation durations on word N as a function of word frequency of the previous word (word N–1, left column), the current word (word N, middle column), and the next word (word N+1, right column). Predictions from separate regression analyses involving cubic effects on averaged data for each condition are shown. Bottom row: Corresponding plots as a function of word length.
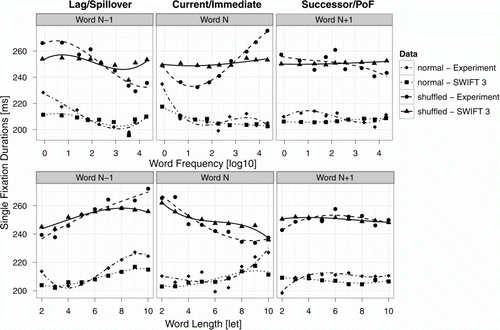
Figure 5. Single fixation durations before skipping (solid triangles) and nonskipping (solid squares) saccades as a function of word length of the skipped word for observed (left panel, dashed lines) and simulated (central panel solid lines) data during normal (upper panel) and shuffled (lower panel) text reading. The right panel displays the skipping difference in single fixation durations [SFD before skipping – SFD before nonskipping] for experimental (dashed lines) and simulated (solid lines) data, where positive difference values indicate skipping costs, and negative difference values indicate skipping benefits. Error bars are cell-based SEM.
![Figure 5. Single fixation durations before skipping (solid triangles) and nonskipping (solid squares) saccades as a function of word length of the skipped word for observed (left panel, dashed lines) and simulated (central panel solid lines) data during normal (upper panel) and shuffled (lower panel) text reading. The right panel displays the skipping difference in single fixation durations [SFD before skipping – SFD before nonskipping] for experimental (dashed lines) and simulated (solid lines) data, where positive difference values indicate skipping costs, and negative difference values indicate skipping benefits. Error bars are cell-based SEM.](/cms/asset/06523438-70ff-41e7-a2c1-6891a1a1225d/pvis_a_670143_o_f0005g.gif)
Figure 6. Shown are correlations between predicted and experimentally observed eye movement measures in the test data sets for normal and for shuffled text. Plotted at the ordinates are observed fixation durations from two tasks (indicated in the left-most column): Normal text reading (A), and shuffled text reading (B, C). Plotted at the abscissae are predicted fixation durations, where predictions are based on different sources (which are indicated in the right-most column): Predictions are based on simulations of the normal-SWIFT model [(A)-upper panel and (B)-upper panel], simulations of the shuffled-SWIFT model [(A)-lower panel and (B)-lower panel], and observed data from normal text reading (C). To compute correlations between observed and predicted data, word frequency (left panel) and length (right panel) were split into bins (the same bins used in ) and correlations were computed over average fixation durations per bin. Analyses were repeated for different measures of fixation durations, including the durations of single fixations (Panels 1+4, counted from left to right), first of multiple fixations (Panels 2+5) and second fixations (Panels 3+6).
![Figure 6. Shown are correlations between predicted and experimentally observed eye movement measures in the test data sets for normal and for shuffled text. Plotted at the ordinates are observed fixation durations from two tasks (indicated in the left-most column): Normal text reading (A), and shuffled text reading (B, C). Plotted at the abscissae are predicted fixation durations, where predictions are based on different sources (which are indicated in the right-most column): Predictions are based on simulations of the normal-SWIFT model [(A)-upper panel and (B)-upper panel], simulations of the shuffled-SWIFT model [(A)-lower panel and (B)-lower panel], and observed data from normal text reading (C). To compute correlations between observed and predicted data, word frequency (left panel) and length (right panel) were split into bins (the same bins used in Figure 3) and correlations were computed over average fixation durations per bin. Analyses were repeated for different measures of fixation durations, including the durations of single fixations (Panels 1+4, counted from left to right), first of multiple fixations (Panels 2+5) and second fixations (Panels 3+6).](/cms/asset/0f7570ba-6565-4541-ac8b-96cf4e10ccad/pvis_a_670143_o_f0006g.gif)
TABLE 2 Correlations between predicted and observed fixation durations in the test data sets for normal and shuffled text
Figure 7. Effects of the dynamical processing span on spatially distributed word processing. Shown are the same results as in (grey), including model simulations of shuffled (triangles & solid lines) and of normal (squares & dotted lines) text and experimental data on shuffled (points & dashed lines) and normal (diamonds & dot-dashed lines) text reading. In addition, simulations of the shuffled-SWIFT model are presented, where the strong dynamic modulation of the processing span was disabled (black stars & solid lines, “shuffled – delta1”). Top row: Average single fixation durations as a function of word frequency of the previous word (word N–1, left column), the current word (word N, middle column), and the next word (word N+1, right column). Predictions from separate regression analyses involving cubic effects on averaged data for each condition are shown. Bottom row: Corresponding plots as a function of word length.
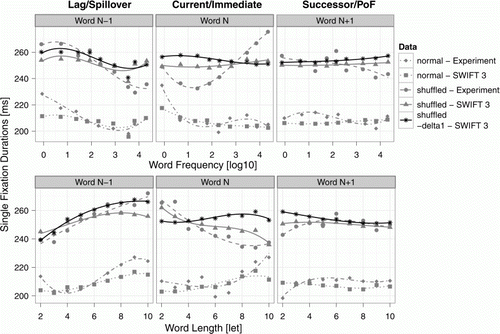
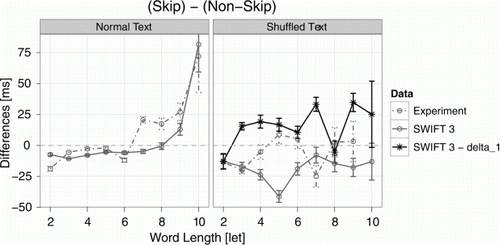
Figure 8. Effects of the dynamic processing span on skipping costs and benefits. Shown are the same results as in the right panel of (grey): Skipping- differences in single fixation durations (SFD before skipping – SFD before nonskipping) as a function of word length of the skipped word for normal (left panel) and shuffled (right panel) text reading for observed (dot-dashed lines & circles) and simulated (solid lines & circles). In addition, simulations of the shuffled-SWIFT model are presented, where the strong dynamic modulation of the processing span was disabled (black lines & stars, “SWIFT 3 – delta_1”, right panel).