Figures & data
Figure 1. a. Example of face stimuli used in all experiments. b. Illustration of the main aspects of the design of Experiment 1. In Experiment 2, the same design was used, except that the voices were replaced by sounds.
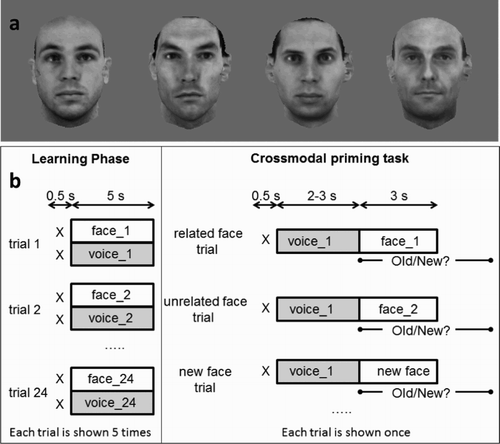
Table 1. Mean RT and response sensitivity results for each of the voice–face priming conditions in Experiment 1. Standard error of the mean is shown in parenthesis.
Figure 2. Plot showing the mean response times in Experiment 1. For each related, unrelated and new face priming condition, the mean response time (in ms) for trials with distinctive and typical voice primes are shown. Error bars represent ±1 standard error of the mean.
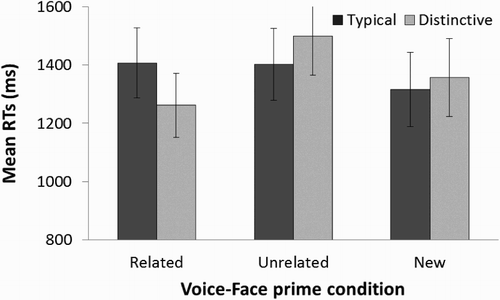
Table 2. Mean RT and response sensitivity results for each of the sound-face priming conditions in Experiment 2. Standard error of the mean is shown in parenthesis.
Figure 3. Plot showing the mean response times in Experiment 2. For each related, unrelated and new sound-face priming condition, the mean response time (in ms) for trials with distinctive and typical voice primes are shown. Error bars represent ±1 standard error of the mean.
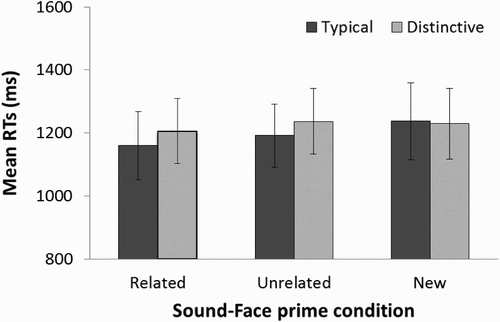
Table 3. Mean response times to each of the voice and sound priming conditions, to each of the distinctive and typical primes, across Experiments 1 and 2 respectively. Standard error of the mean is shown in parenthesis.
Figure 4. Main aspects of the design of Experiment 3.
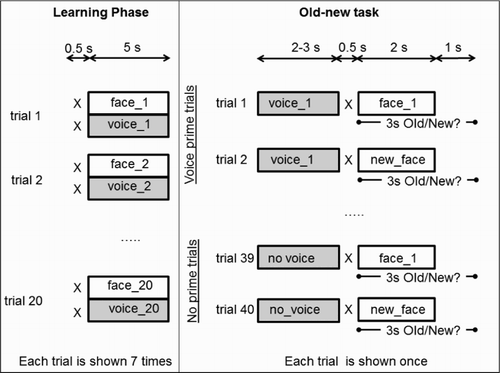
Table 4. Mean RT and accuracy results for each of the voice prime and no-prime conditions to the related and new face conditions in Experiment 3. Standard error of the mean is shown in parenthesis.
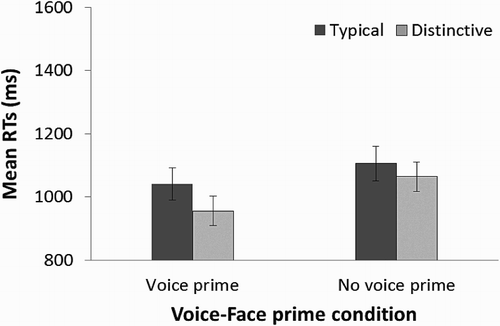
Figure 5. Plot showing the mean response times in Experiment 3. For each voice prime and no voice prime condition, the mean response time (in ms) for trials with distinctive and typical voice primes are shown. Error bars represent ±1 standard error of the mean.