Figures & data
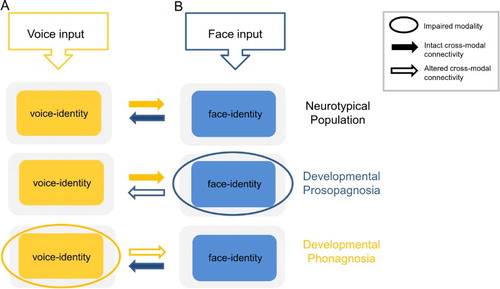
Figure 1. A schematic representation of the interactions between voice and face information, during identity processing based on unisensory input, in the neurotypical population, developmental prosopagnosia, and developmental phonagnosia. Neurotypical population. Auditory-only voice-identity processing (A) is facilitated by visual face-identity information in the FFA. The FFA shares connections with voice-sensitive regions in the a/m STS/G (solid yellow and blue arrows) (Blank et al., Citation2011; von Kriegstein et al., Citation2008; Schall et al., Citation2013). Although speculative, visual face processing (B) may also be facilitated by connections between these regions (see Bülthoff and Newell, Citation2015, for behavioural effects). Although the solid yellow and blue arrows are depicted here with equal strength, it is likely that the actual strength of the interactions will vary depending on the saliency of the unisensory input. Developmental prosopagnosia. Auditory-only voice-identity processing (A) does not benefit from prior face-voice learning owing to impaired face-identity processing. Although connections between the FFA and STS/G exist in this cohort (von Kriegstein et al., Citation2006; Schall & von Kriegstein, Citation2014), they are not sufficient to optimise speaker recognition. This is likely owing to atypical recruitment of the FFA during voice-identity processing which may alter the nature of the information transferred between these regions (outline blue arrow) (von Kriegstein et al., Citation2006, Citation2008). Hypothetically, visual face processing (B) could be enhanced through audio-visual face-voice learning in this cohort (solid yellow arrow). Developmental phonagnosia. Auditory-only voice-identity processing (A) may be enhanced through compensatory recruitment of intact visual face-identity mechanisms (solid blue arrow) (Roswandowitz et al., Citation2014; Roswandowitz et al., Citation2017). However, visual face processing (B) may not benefit from additional vocal information in this cohort, owing to the failure to represent the voice at the level of the individual identity (outline yellow arrow).