Figures & data
Figure 1. Schematics of linear (a) and Reinforcement Learning (b) control methods applied to a Rayleigh–Bénard system and aiming at reducing convective effects (i.e. the Nusselt number). The system consists of a domain with height, H, aspect ratio, , no-slip boundary conditions, constant temperature
on the top boundary, adiabatic side boundaries and a controllable bottom boundary where the imposed temperature
can vary in space and time (according to the control protocol) while keeping a constant average
. Because the average temperature of the bottom plate is constant, the Rayleigh number is well defined and constant over time. The control protocol of the linear controller (a) works by calculating the distance measure
from the ideal state (cf. Equation Equation10
(10)
(10) –Equation11
(11)
(11) ) and, based on linear relations, applies temperature corrections to the bottom plate. The RL method (Figure b) uses a Neural Network controller which acquires flow state from a number of probes at fixed locations and returns a temperature profile (see details in Figure ). The parameters of the Neural Network are automatically optimised by the RL method, during training. Moreover, in the RL case, the temperature fluctuations at the bottom plate are piece-wise constant and can have only prefixed temperature value between two states, hot or cold (cf. Equation Equation12
(12)
(12) ). Operating with discrete actions reduces significantly the complexity and the computational resources needed for training.
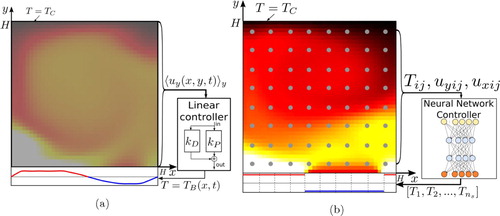
Figure 2. Sketch of the neural network determining the policy adopted by the RL-based controller (policy network, π, cf. Figure (b) for the complete setup). The input of the policy network is a state vector, , which stacks the values of temperature and both velocity components for the current and the previous D−1 = 3 timesteps. Temperature and velocity are read on an evenly spaced grid of size
by
. Hence,
has dimension
. The policy network π is composed of two fully connected feed forward layers with
neurons and
activation. The network output is provided by one fully connected layer with
activation (Equation Equation16
(16)
(16) ). This returns the probability vector
. The kjth bottom segment has temperature C with probability
(Equation Equation17
(17)
(17) ). This probability distribution gets sampled to produce a proposed temperature profile
. The final temperature fluctuations
are generated with the normalization step in Equation (EquationA7
(A7)
(A7) ) (cf. Equations (Equation7
(7)
(7) ) and (Equation9
(9)
(9) )). The temperature profile obtained is applied to the bottom plate during a time interval
(control loop), after which the procedure is repeated.
![Figure 2. Sketch of the neural network determining the policy adopted by the RL-based controller (policy network, π, cf. Figure 1(b) for the complete setup). The input of the policy network is a state vector, s, which stacks the values of temperature and both velocity components for the current and the previous D−1 = 3 timesteps. Temperature and velocity are read on an evenly spaced grid of size GX=8 by GY=8. Hence, s has dimension nf⋅GX⋅GY⋅D=3⋅8⋅8⋅4=768. The policy network π is composed of two fully connected feed forward layers with nneurons=64 neurons and σ(⋅)=tanh(⋅) activation. The network output is provided by one fully connected layer with σ(⋅)=ϕ(⋅) activation (Equation Equation16(16) yk=ϕ(zk)=11+exp(−zk),k=1,2,…,ns(16) ). This returns the probability vector y=[y1,y2,…,yns]. The kjth bottom segment has temperature C with probability yk (Equation Equation17(17) πk(T~k=+C|si)=Bernoulli(p=yk).(17) ). This probability distribution gets sampled to produce a proposed temperature profile T~=(T~1,T~2,…,T~ns). The final temperature fluctuations T^1,T^2,…,T^ns are generated with the normalization step in Equation (EquationA7(A7) T^B(x,t)=T~B″(x,t)maxx′(1,|T~B″(x,t)|/C).(A7) ) (cf. Equations (Equation7(7) TH=⟨TB(x,t)⟩x,(7) ) and (Equation9(9) T^B(x,t)|≤C∀x,t,(9) )). The temperature profile obtained is applied to the bottom plate during a time interval Δt (control loop), after which the procedure is repeated.](/cms/asset/1d58b6f8-5144-4122-9cf6-c02686d3d447/tjot_a_1797059_f0002_oc.jpg)
Table 1. Rayleigh–Bénard system and simulation parameters.
Table 2. Parameters used for the linear controls in Lattice Boltzmann units (cf. Equation (Equation10 (10) (10) ); note: a P controller is obtained by setting ). At we were unable to find PD controllers performing better than P controllers, which were anyway ineffective.
(10) (10) ); note: a P controller is obtained by setting ). At we were unable to find PD controllers performing better than P controllers, which were anyway ineffective.
Figure 3. Comparison of Nusselt number, averaged over time and ensemble, measured for uncontrolled and controlled Rayleigh–Bénard systems (note that all the systems are initialised in a natural convective state). We observe that the critical Rayleigh number, , increases when we control the system, with
in case of state-of-the-art linear control and
in case of the RL-based control. Furthermore, for
, the RL control achieves a Nusselt number consistently lower than what measured in case of the uncontrolled system and for state-of-the-art linear controls (P and PD controllers have comparable performance at all the considered Rayleigh numbers, see also [Citation13]). The error bars are estimated as
, where N = 161 is the number of statistically independent samplings of the Nusselt number.
![Figure 3. Comparison of Nusselt number, averaged over time and ensemble, measured for uncontrolled and controlled Rayleigh–Bénard systems (note that all the systems are initialised in a natural convective state). We observe that the critical Rayleigh number, Rac, increases when we control the system, with Rac=104 in case of state-of-the-art linear control and Rac=3⋅104 in case of the RL-based control. Furthermore, for Ra>Rac, the RL control achieves a Nusselt number consistently lower than what measured in case of the uncontrolled system and for state-of-the-art linear controls (P and PD controllers have comparable performance at all the considered Rayleigh numbers, see also [Citation13]). The error bars are estimated as μNu/N, where N = 161 is the number of statistically independent samplings of the Nusselt number.](/cms/asset/ab6b551f-8171-43a8-9fef-53de3b381cc0/tjot_a_1797059_f0003_oc.jpg)
Figure 4. Time evolution of the Nusselt number at four different Rayleigh regimes, with the control starting at t = 0. The time axis is in units of control loop length, (cf. Table ). Up to
(a,b), the RL control is able to stabilise the system (i.e.
), which is in contrast with linear methods that result in a unsteady flow. At
(c), the RL control is also unable to fully stabilise the system, yet, contrarily to the linear case, it still results in a flow having stationary Nu. For
(d) the performance of RL is not as stable as at lower
, the control however still manages to reduce the average Nusselt number significantly. (a)
, (b)
, (c)
and (d)
.
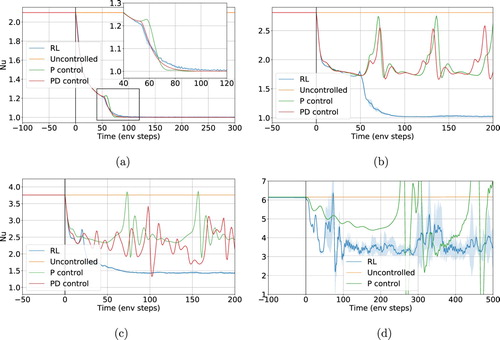
Figure 5. Instantaneous stream lines at different times, at , comparison of cases without control (a), with linear control (b) and with RL-based control (c). Note that the time is given in units of
(i.e. control loop length, cf. Table . Note that the snapshots are taken at different instants). RL controls establish a flow regime like a ‘double cell mode’ which features a steady Nusselt number (see Figure c). This is in contrast with linear methods which rather produce a flow with fluctuating Nusselt. The double cell flow field has a significantly lower Nusselt number than the uncontrolled case, as heat transport to the top boundary can only happen via diffusion through the interface between the two cells. This ‘double cell’ control strategy is established by the RL control with any external supervision.
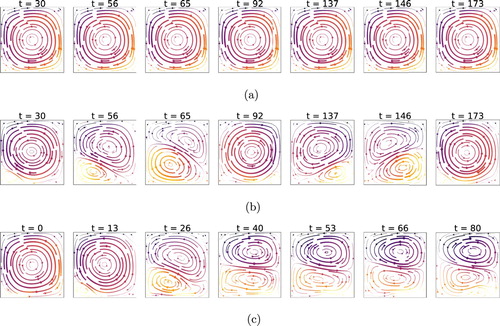
Figure 6. Instantaneous stream lines at , comparison of cases without control (a), with linear control (b), and with RL-based control (c). We observe that the RL control still tries to enforce a ‘double cell’ flow, as in the lower Rayleigh case (Figure ). The structure is, however, far less pronounced and convective effects are much stronger. This is likely due to the increased instability and chaoticity of the system, which increases the learning and controlling difficulty. Yet, we can observe a small alteration in the flow structure (cf. lower cell, larger in size than in uncontrolled conditions) which results in a slightly lower Nusselt number.
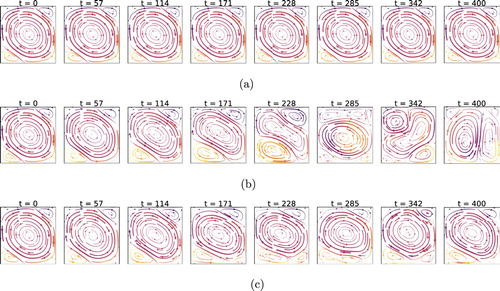
Figure 7. Performance loss due to an artificial delay imposed to an RL controller operating on the Lorenz attractor. The controller, operating on the y variable of the system (reduced model for the RBC horizontal temperature fluctuations) aims at either maximising (LA oscillator) or minimising (LA stabiliser) the number of sign changes of the x (in RBC terms the angular velocity of the flow). The delay, on the horizontal axis, is scaled on the Lyapunov time, , of the system (with λ the largest Lyapunov exponent). In case of a delay in the control loop comparable in size to the Lyapunov time, the control performance diminishes significantly.
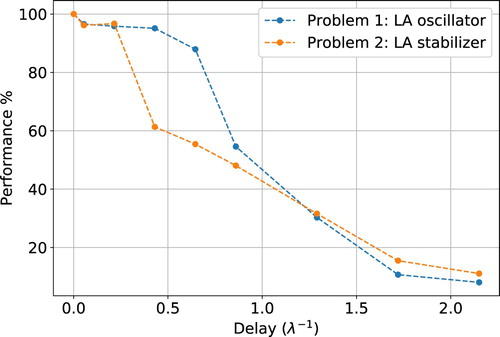
Figure 8. Average Nusselt number for an RL agent observing the Rayleigh–Bénard environment at different probe density, all of which are lower than the baseline employed in Section . The grid sizes (i.e information) used to sample the state of the system at the Ra considered does not seem to play key role in limiting the final control performance of the RL agent.
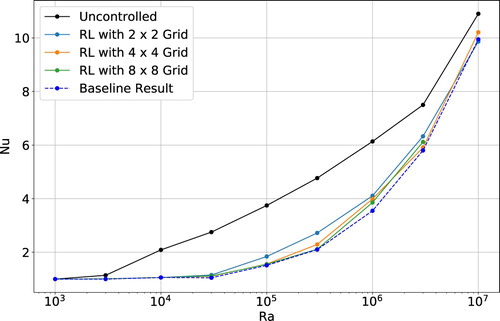
Table A1. Rayleigh–Bénard environments considered. For each Rayleigh number we report the LBM grid employed (size ), the uncontrolled Nusselt number measured from LBM simulations and a validation reference from the literature.
Figure A1. Performance of RL during training (case of the Rayleigh–Bénard system). We report the average Nusselt number and its fluctuations computed among a batch of 512 concurrent training environments. (a) ‘low’ Ra () in which the control achieves
in a stable way, (b)‘mid’ Ra (
) which still gives stable learning behaviour but converges to
and, lastly, (c) ‘high’ Ra (
) in which the higher chaoticity of the system makes a full stabilization impossible. (a)
(‘low’). (b)
(‘mid’) and (c)
(‘high’).
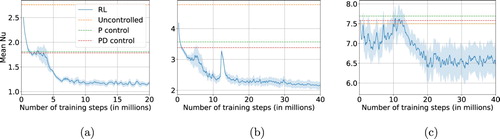
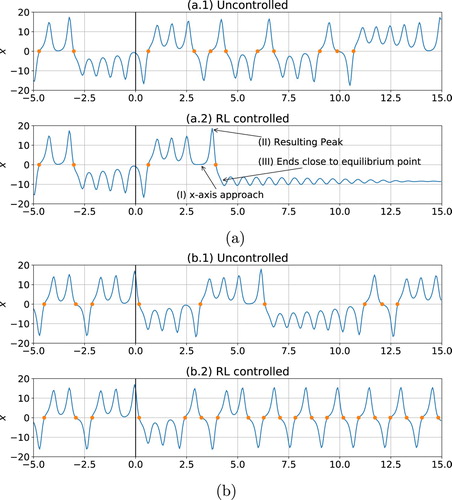
Figure A2. System trajectories with RL control, respectively aiming at minimising (a) and maximising (b) the number of x sign changes. In (a.1) and (b.1), we report two reference uncontrolled cases which differ only by the initialization state, . Panel (a) shows that the RL agent is able to fully stabilise the system on an unstable equilibrium by using a complex strategy in three steps (I: controlling the system such that it approaches x, y, z = 0 which results in a peak (II) which after going through x = 0 ends close enough to an unstable equilibrium (III) such that the control is able to fully stabilise the system). Furthermore, Figure (a) shows that the RL agent is able to find and stabilise a unstable periodic orbits with a desired property of a high frequency of sign changes of x.