Figures & data
Figure 1. Basic principle of PAT. An object is illuminated with a short optical pulse (left) that induces an acoustic pressure wave (middle). The pressure signals are recorded outside of the object, and are used to recover an image of the interior (right).

Figure 2. Illustration of the proposed network for PAT image reconstruction. In the first step, the FBP algorithm (or another standard linear reconstruction method) is applied to the sparse data. In a second step, a deep CNN is applied to the intermediate reconstruction which outputs an almost artefact-free image. This may be interpreted as a deep network with the FBP in the first layer and the CNN in the remaining layers.
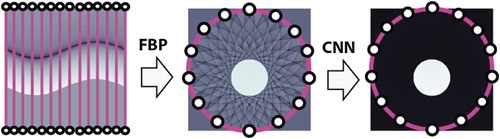
Figure 3. Sparse sampling problem in PAT in circular geometry. The induced acoustic pressure is measured at M detector locations on the boundary of the disc
indicated by white dots in the left image. Every detector at location
measures a time dependent pressure signal
, corresponding to a column in the right image.
![Figure 3. Sparse sampling problem in PAT in circular geometry. The induced acoustic pressure is measured at M detector locations on the boundary of the disc BR indicated by white dots in the left image. Every detector at location zm measures a time dependent pressure signal p[m,⋅], corresponding to a column in the right image.](/cms/asset/458dc419-0894-45dd-b1ca-678ac9721841/gipe_a_1518444_f0003_oc.jpg)
Figure 4. Architecture of the used CNN (U-net with residual connection). The number written above each layer denotes the number of convolution kernels (channels), which is equal to number of images in each layer. The numbers denote the dimension of the images (the block sizes in the weight matrices), which stays constant in every row. The long horizontal arrows indicate direct connections with subsequent concatenation or summation for the upmost arrow.
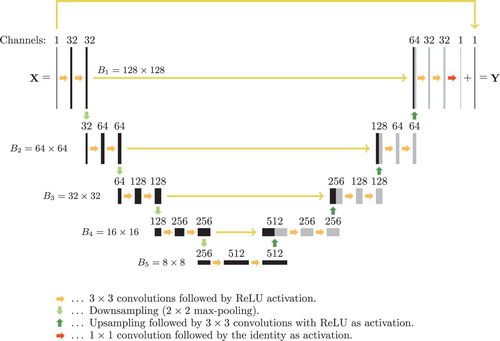
Figure 5. Results for simulated data (all images are displayed using the same colourmap). (a) Superposition of five ellipses as test phantom; (b) FBP reconstruction; (c) reconstruction using the proposed CNN; (d) TV reconstruction.

Table 1. Relative  -reconstruction errors for the four different test cases.
-reconstruction errors for the four different test cases.
Figure 6. Results for noisy test data with 2% Gaussian noise added (all images are displayed using the same colourmap). (a) Reconstruction using the FBP algorithm; (b) reconstruction using the CNN trained without noise; (c) reconstruction using the CNN trained on noisy images; (d) TV reconstruction.
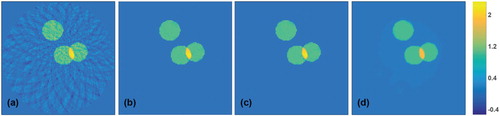
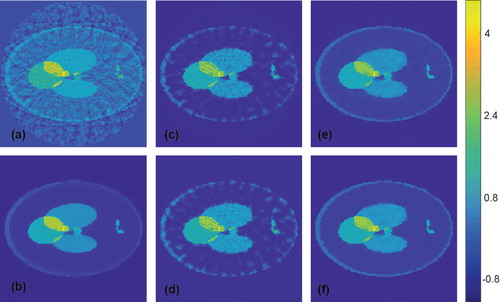
Figure 7. Reconstruction results for a Shepp–Logan type phantom using simultated data (all images are displayed using the same colourmap). (a) FBP reconstruction; (b) reconstruction using TV minimization. (c) Proposed CNN using wrong training data without noise added; (d) proposed CNN using wrong training data with noise added; (e) proposed CNN using appropriate training data without noise added; (f) proposed CNN using appropriate training data with noise added.
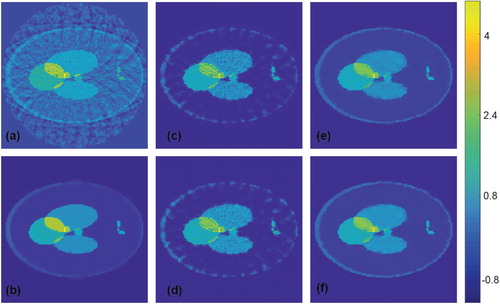
Figure 8. Reconstruction results for a Shepp–Logan type phantom from data with 2% Gaussian noise added (all images are displayed using the same colourmap). (a) FBP reconstruction; (b) reconstruction using TV minimization. (c) Proposed CNN using wrong training data without noise added; (d) proposed CNN using wrong training data with noise added; (e) proposed CNN using appropriate training data without noise added; (f) proposed CNN using appropriate training data with noise added.