Figures & data
Table 1. Participant characteristics
Figure 1. Flow chart of participant enrollment, assignment, and follow-up
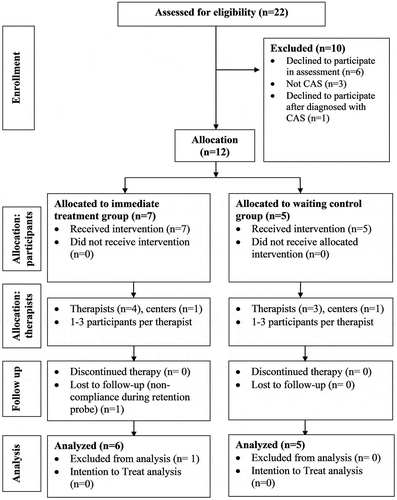
Table 2. Principles of motor learning
Table 3 a. Summary of GLMM for a) intersegment duration b) PVI for duration (dur), fundamental frequency (f0), and intensity (I) in SW stimuli and c) PVI(dur), PVI(f0), and PVI(I) for WS stimuli. Tables show F-tests for main effects and interaction; β-value, standard error, and p-value, for phase (Baseline, Post-treatment, and 1-month Retention) and set (Treated and Untreated pseudoword and Real word) comparisons; ICC – the Intraclass Correlation Coefficient denotes the variability accounted for by the “between-subject” factor with respect to the overall variability in the model; and fit statistics: AIC – Akaike’s Information Criterion – An estimator of the of out-of- sample prediction error and the relative quality of statistical models for a given set of data. In estimating the amount of information lost by a model, AIC deals with the trade-off between the fit of the model and the simplicity of the model; AICC- The AIC Corrected can be used for smaller sample sizes; BIC – Bayesian Information Criterion – A criterion for model selection among a finite set of models. The model with a lower BIC is considered better. When fitting models, it is possible to increase the likelihood (sometimes reflected in a better fit) by adding parameters, although this may result in overfitting the model. BIC and AIC both attempt to resolve this problem by introducing a penalty term for the number of parameters in the model; the penalty term is larger in BIC than in AIC
Figure 2. Mean intersegment duration for the combined group of 11 participants, with each of three stimulus sets (treated plosive pseudowords, untreated plosive pseudowords, and untreated real words) graphed separately across baseline, immediate post-treatment (Post), and one-month retention time-points. Errors bars show standard error
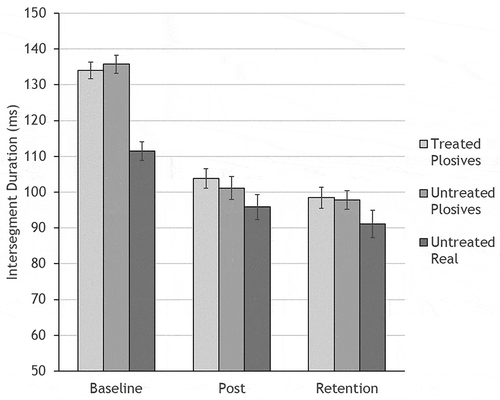
Table 4. Summary of perceptual outcome measures. Odds ratios, 95% confidence intervals, standard error, and p-values are shown for each phase comparison (Baseline, Post-treatment, and 1-month Retention) and set comparison (Treated and Untreated Plosives and Real Word)
Figure 3. Odds ratios for combined 11 participants for each perceptual variable, showing the likelihood of accuracy in each variable at immediate post-treatment and one-month retention time points as compared to performance at baseline. Error bars show 95% confidence intervals
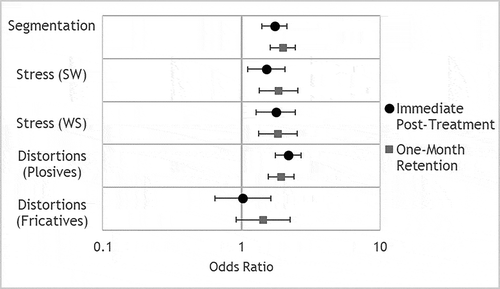
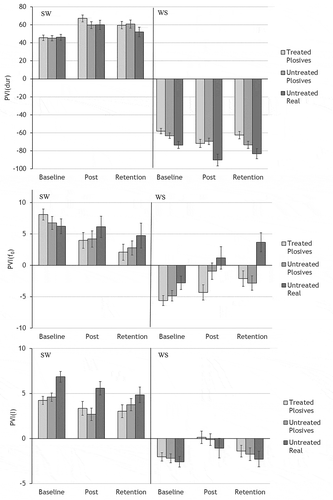
Figure 4. Mean pairwise variability indices of strong and weak vowel duration contrasts (PVI(dur), top panel), maximum fundamental frequency contrasts (PVI(f0), middle panel), and maximum intensity contrasts (PVI(I), bottom panel), for the combined group of 11 participants. Each stimulus set (treated plosive pseudowords, untreated plosive pseudowords, and untreated real words) is graphed separately across baseline, immediate post-treatment (Post), and one-month retention time points. Means for strong-weak (SW; positive values) and weak-strong (WS; negative values) stimuli are graphed separately for each variable, with error bars showing standard error