
Figures & data
Figure 1. Map of vision in transformer.
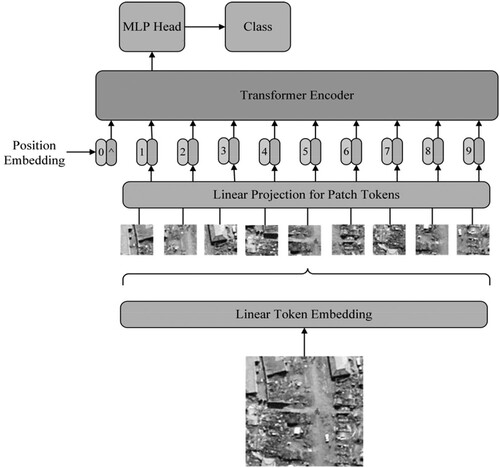
Figure 2. Location of the study areas.

Table 1. Classification of building damaged by aerial images after earthquake.
Table 2. Example images of classification instances.
Table 3. Distribution of the sample set.
Figure 3. The flowchart of the Conv-Transformer structure.
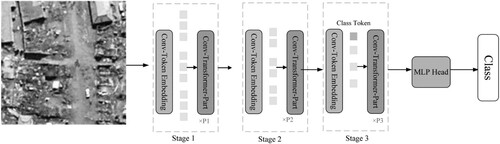
Figure 4. The flowchart of the Conv-Projection structure.
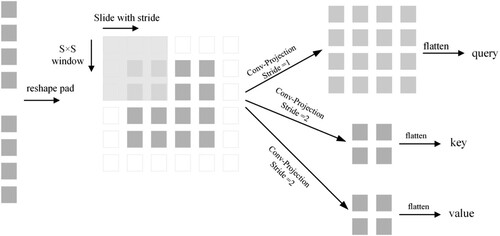
Figure 5. Self Attention (a), Local Attention (b) and Global Attention (c). (Local Attention can only obtain the information of the image in the window, while Global attention can pay attention to the information of the entire image).

Figure 6. Cross Attention implementation in details (Only the Class tokens are fused because the Class tokens represent all the information of the branch patches).
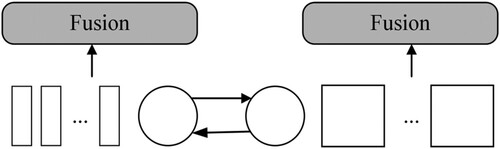
Figure 7. Cross Attention implementation in detail (The class token in Big-branch interacts with the patch tokens in Small-branch as query, and the class token in Small-branch also performs the same operation to complete the interaction of the feature information between the two branches).
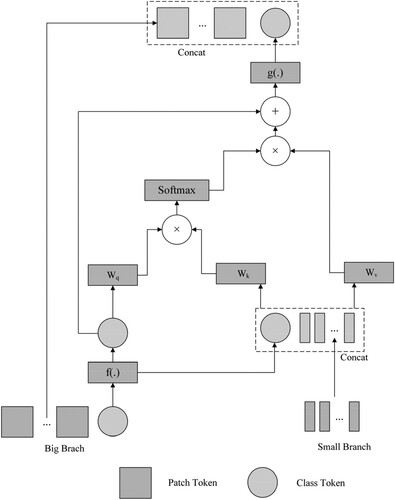
Figure 8. Cross Conv-Transformer network structure. (The network is divided into two branches, each branch is composed of a different number of Conv-Transformer. The output of the last two branches is sent to the Cross-Attention module for information fusion and filtering, and finally to the MLP for classification).
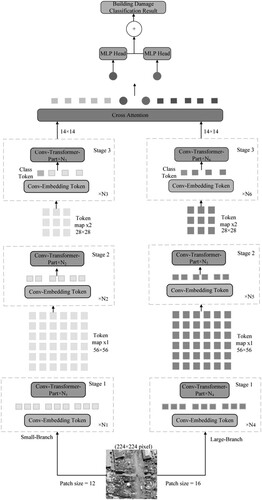
Figure 9. Precision and loss curve of the four models during training.
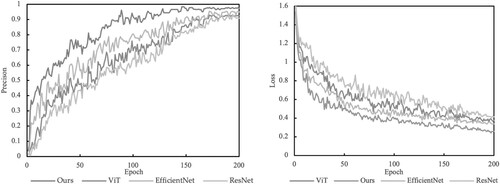
Table 4. Confusion matrix of the ResNet.
Table 5. Confusion matrix of the ViT.
Table 6. Confusion matrix of the EfficientNet.
Table 7. Confusion matrix of the Crosss Conv-Transformer.
Figure 10. Block level distribution map of earthquake damage degree in Yushu.
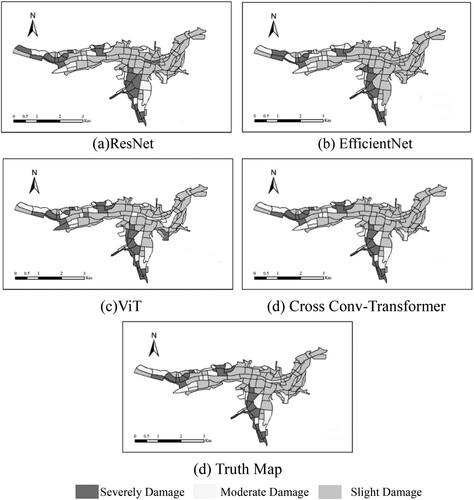
Table 8. Confusion matrix of the Crosss Conv-Transformer.
Figure 11. Heat map of the model’s feature.
