
Figures & data
Figure 1. Overview of the study area: (a) geographical location; (b) six ecological districts; (c) elevation; (d) land cover and land use.
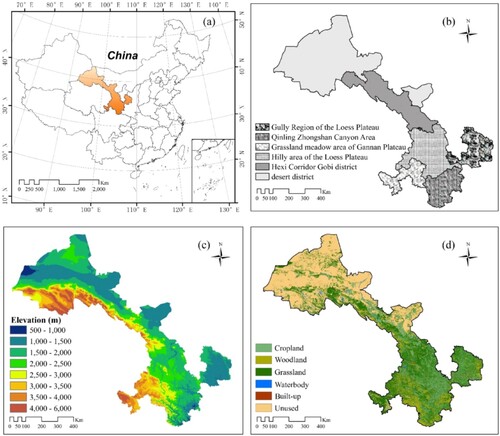
Table 1. Geographic data and agricultural statistics for fractional crop-planting area mapping.
Table 2. CNLULC land use classification scheme.
Figure 2. Workflow of integration of geographic data and agricultural statistics to generate FCPA estimates.
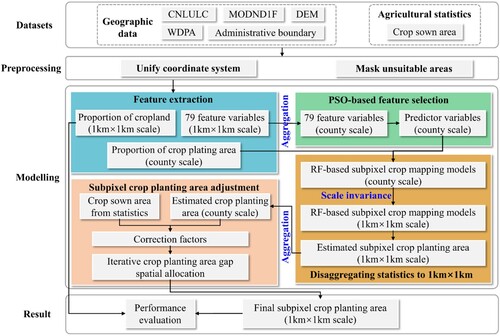
Figure 3. Workflow of adjusting the predicted crop-planting areas by RF models to match the agricultural statistics.
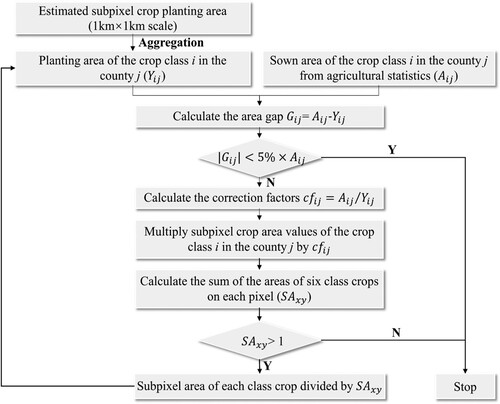
Figure 4. Selected features and their importance ranking: (a)–(f) represents six types of crops (i.e. wheat, maize, oil-bearing, vegetable, orchards, and other crops, respectively).
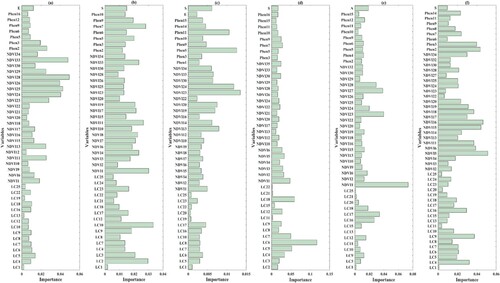
Figure 5. Comparison of agricultural statistics with disaggregating estimates based on RF-based regression models. The first to sixth rows of subplots from top to bottom represent six types of crops (i.e. wheat, maize, oil-bearing, vegetable, orchards, and other crops) respectively. The first to third columns from left to right are (a1–f1) agricultural statistics, and the predicted FCPA by RF models (a2∼f2) without feature selection and (a3∼f3) with PSO feature selection.
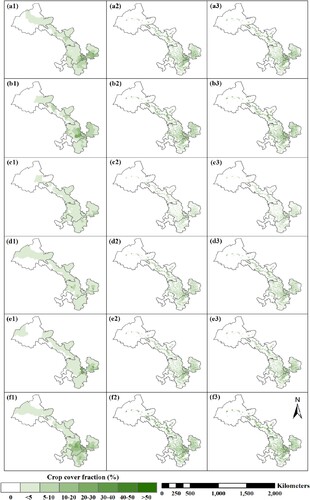
Figure 6. Comparison of agricultural statistics with disaggregating estimates based on adjusted RF regression models. Except for adjusting the prediction of RF-based models, the symbols are identical to those in .
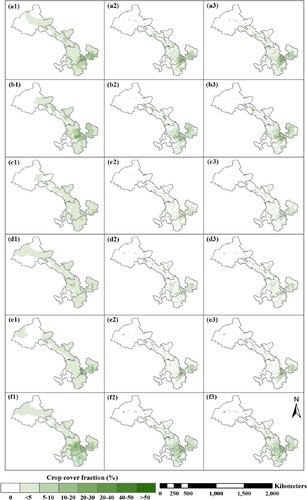
Figure 7. Comparison of agricultural statistics with RF-based downscaled estimates aggregated to the administrative unit level. The first to sixth rows of subplots from top to bottom represented six crops of wheat, maize, oil-bearing, vegetable, orchards, and other crops, respectively. The first to fourth columns from left to right represent downscaled results from ‘RF,’ ‘RF-FS,’ ‘RF-C,’ and ‘RF-FS-C,’ respectively. A red line portrays the 1:1 line for the estimated census relationship and each scatter represents a county.
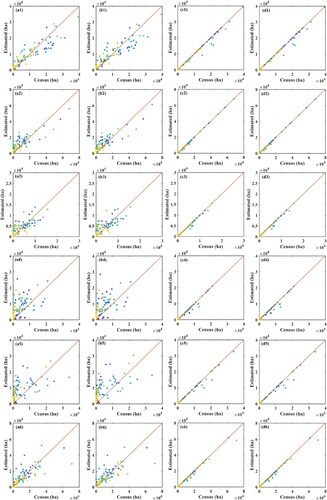
Table 3. Accuracy of the RF-based FCPA mapping models on the county scale.
Figure 8. Comparison of agricultural statistics of six crops with RF-based downscaled estimates aggregated to the ecological district scale. Each subplot represents an ecological area: (a) hilly area of the Loess Plateau; (b) desert district; (c) Hexi Corridor gobi district; (d) Qinling Zhongshan canyon area; (e) gully region of the Loess Plateau; and (f) grassland meadow area of Gannan Plateau.
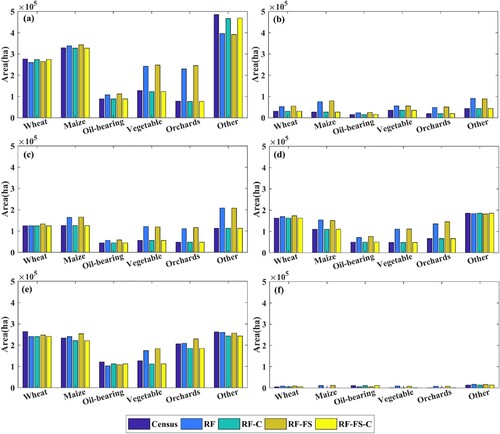
Figure 9. Comparison of cropland distribution from CLCD and estimated total crop-planting area on a 1-km pixel scale: (a) the proportion of cropland calculated using 30-m LCLD data and estimated total crop-planting area by (b) RF, (c) RF-C, (d) RF-FS, and (e) RF-FS-C, respectively.
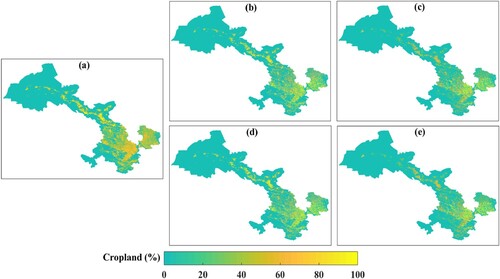
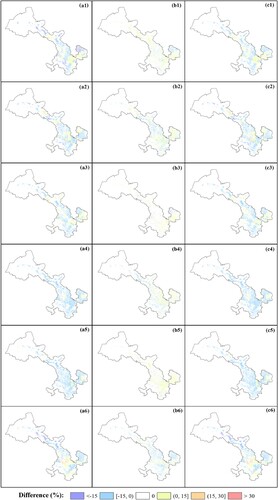
Figure 10. The effect of feature selection and postprocessing adjustment. The first to sixth rows of subplots from top to bottom represent six crops of wheat, maize, oil-bearing, vegetable, orchards, and other crops, respectively. The first to third columns from left to right represent the effects of (a1∼a6) adjustment, (b1∼b6) feature selection, and (c1∼c6) a combination of the two, respectively.
Data availability statement
The data supporting the findings of this study are available from the website provided in the manuscript.